

文|三易生活
如今,人工智能毫无疑问已经是科技行业最为热门的赛道之一,甚至几乎所有叫得上名号的科技企业都卷入了这场竞赛。而在AI大模型的相关市场竞争中,除了底层的算法、架构外,“语料”则是一个被反复提及的关键要素。但围绕“语料”这一AI大模型的生产资料,在过去一年间,整合行业也上演了一系列光怪陆离的故事。
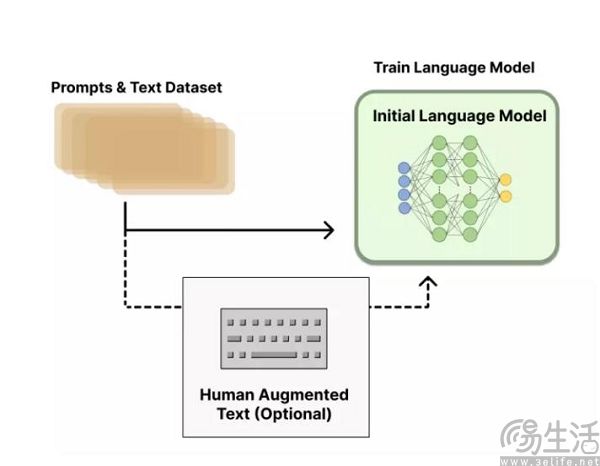
那么训练AI大模型的语料从何而来呢?自然是从书籍、报刊、杂志、视频、音频、代码等,一系列凝聚了人类智慧的产物中来,但是由于AI不是人类,他们认识世界的方式与人类不同,所以蕴含在这些作品中的信息还需要经过一道处理工序,才能转化为可以被AI大模型利用的语料,而这就是所谓的“数据标注”了。
比如OpenAI旗下的ChatGPT,就是靠着2美元时薪的海外外包数据清洗人员,完成了史无前例的1750亿参数量、45TB的训练数据。
如果把人工智能比作一栋大楼,那么标注的数据就是一块块的砖,如果将人工智能比作一碗饭,那么标注的数据自然也就是大米了。从某种意义上来说,现阶段的人工智能在实质上其实就是字面上的意义,也就是50%的人工+50%的智能。如果没有人工数据标注的存在,那么当下的AI大模型竞争恐怕是要直接“熄火”。
有鉴于此,谷歌方面近期表示要让人工智能更智能一些。

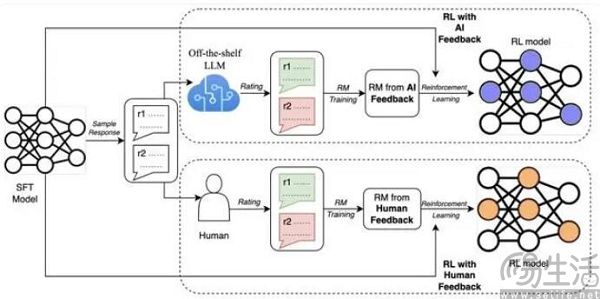
日前,Google Research的最新研究提出了AI反馈强化学习(RLAIF),用来代替基于人类反馈的强化学习(RLHF)。事实上,RLHF正是ChatGPT等同类产品表现出比Siri等上一代人工智能产品更聪明,表达更接近人类的关键驱动因素之一,它可以借助人类反馈信号来直接优化语言模型,数据标注人员则通过给大模型产出的结果打分,由他们来负责判断大模型生成的文本是否优质(迎合人类偏好)。
根据谷歌方面的研究结果显示,RLAIF可以在不依赖人类标注员的情况下,产生与RLHF相当的改进效果。具体来说,当被要求直接比较RLAIF与RLHF的结果时,人类对两者的偏好大致相同,同时RLAIF和RLHF都优于传统的监督微调(SFT)基线策略。这也就意味着谷歌的研究证明了用AI训练AI大模型并非空话,也代表着如今的人工智能行业很有可能会迎来一次大规模的洗牌。
众所周知,语料是AI大模型的基础,而AI大模型之所以比以往的同类产品表现得更“聪明”,单纯就是因为语料的规模更大。例如GPT-3就拥有的1750亿的参数量、45TB的训练数据,GPT-4的参数规模则达到了惊人的1.8万亿。但要将基础数据转化为AI可识别的语料,无疑是个巨大的工程。
数据标注就是把各种图片、文本、视频等数据集打上标签,成为计算机可以理解识别的技术。这一工作在2007年之前是由程序员来负责完成,但毕竟有限的程序员群体与AI对于语料的无止境需求极其不匹配,所以这也导致了AI在本世纪第二个十年以前一直都曲高和寡。直到2007年,计算机科学家李飞飞通过亚马逊众包平台雇佣了167个国家共计5万人,来给10亿张图片筛选、排序、打标签,最终构建了ImageNet数据集。
自此之后,大量科技企业发现数据标注并不需要程序员来参与,只要是受过一定教育的普通人即可完成,这也成为了为什么AI在近十年来突飞猛进的原因之一。其实数据标注从某种意义上来说,就与流水线上工人干的活没什么区别,而对着电脑屏幕根据给定的规则来给数据打上各式各样的标注这一工作,完全可以称得上是“赛博搬砖”。
相关厂商显然不会将自己宝贵的人力资源浪费在这样机械化的工作上,所以数据标注目前基本就是一个以外包为主导的行业,并且通过BPO的形式将数据标注工作交付给外包公司,确实也在一定程度上为AI厂商节约了成本,但从客观上来说,数据标注本身还是很费钱的。虽然0.25元/条是过去两年数据标注行业的均价,但别看单价没多少,可数以亿计的规模就直接让数据集的总价变得可观了起来。

看到这里,有的朋友可能会有这样的疑问,如果谷歌提出的RLAIF真的可行,数据标注人员是不是要失业了?毕竟数据标注人员一天能完成800到1000条的数据标注就已经是优秀水平了,但比起不眠不休、不会疲劳的AI,血肉构成的人类还是没得比。更有效率、更稳定的情况下,一旦再证明了RLAIF的效果不输RLHF,人类进行数据标注显然将会不再有经济性。
如果单纯从商业层面出发,RLAIF肯定要比RLHF更好,但问题是AI厂商作为人类社会的一份子,同样也具有社会性,并且AI厂商打造的大模型不仅要有性能,更重要的是还要合规。如今ChatGPT、New Bing在性能上比它们刚亮相时有所衰退的原因,已经不仅仅来自用户的体感,更得到了研究人员的证实。
其实这一现象并非是因为OpenAI、微软的技术退步了,反而是两者技术迭代的结果,因为他们必须要在AI伦理问题上合规。由此也衍生出了一个控制AI的概念“AI对齐”,即要求AI系统的目标要与人类的价值观与利益对齐,不会产生意外的有害后果,比如说暴力、歧视等。例如现在向文心一言提出帮你想一个骂人的话,文心一言就只会直接回答,“作为一个人工智能语言模型,我不会提供或使用任何形式的脏话或粗俗语言。”
但问题也就来了,网络上大家互相攻击的言论可谓是数不胜数,文心一言怎么可能会做不到骂人呢?但它确实可以很“正能量”,这其实就是“AI对齐”在发挥作用。可强行让AI遵守人类的价值观本身就是反直觉的,在微软研究院发布的一篇论文中就已经证实,对AI大模型所进行的任何AI对齐行为,都会损失大模型的准确性和性能。

所以现在的情况,就是谷歌提出的RLAIF本质上是剥离了AI大模型训练中的人类参与,但这与“AI对齐”的思路是相悖的。虽然在谷歌的相关论文中,RLAIF与人类判断呈现出高度相似,但目前在围绕AI的争议如此巨大的情况下,真的有企业敢于去用RLAIF来代替RLHF吗?
评论