
文|蓝洞商业 赵卫卫
ChatGPT 爆火一年,大模型的竞争走到哪一步了?
从微信指数的数据,可以管中窥豹到各家大模型的感知度,ChatGPT 遥遥领先,依然是国内大模型们追赶的对象。
而国内互联网大厂的大模型梯队中,百度的文心一言和阿里的通义千问,依赖于发布时间较早,是产品感知度比较高的存在,尤其是文心一言3 月率先发布、 8月全面开放,已经进化到 4.0 版本。
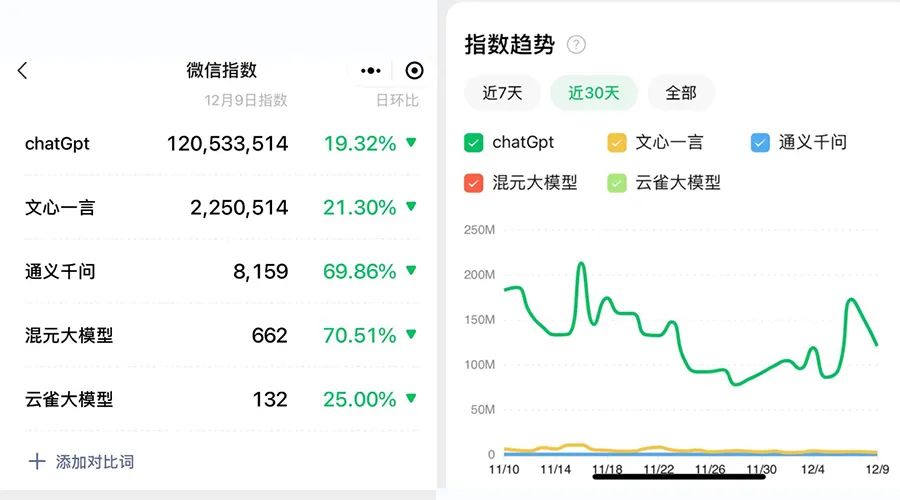
而老对手腾讯和字节,分别在今年 8 月和 9 月亮相了自家的大模型产品,在时间线上属于跟进 ChatGPT 较晚的梯队,姿态也都相对低调。
先看字节的大模型战略,是先在 8 月上线了 AI 聊天机器人「豆包」,随后自研的大模型产品云雀在 9 月浮出水面,而「豆包」正是云雀大模型在垂直场景中的应用产品。
最新的动作是,在海外上线 AI 产品「ChitChop」,应用场景比「豆包」的海外版本「 Cici 」更丰富,如此密集的产品布局,被外界认为是字节从「 APP 工厂」朝「 AI工厂」迈进。
再看腾讯的混元大模型,正式发布于 9 月,属于国内互联网大厂中最晚入场的玩家,也是至今没有单独发布独立大模型 APP 的互联网大厂。混元大模型最直接的使用场景还是在微信小程序内,发布后最大的变化是, 10 月底开放了文生图功能。
不做独立 APP ,而是利用微信丰沛的流量做大模型小程序,优先迭代基础能力,是腾讯混元大模型的现状;而同样流量丰沛的字节,则选择布局多款 AI 大模型垂直产品,在国内外市场同时押注。
至此,字节和腾讯这对老冤家,正在大模型的赛道背道而驰。
OpenAI上线一年,其自身团队的变动成了大模型混乱期的转折点;而当国内「百模大战」告一段落,谁能在混乱期中突出重围?
01 腾讯,依然「不着急」?
关于大模型能力的测试有很多,各家大模型的产品能力也各有千秋。
腾讯方面曾宣称,在信通院测评主流大模型测试中,混元的模型开发和模型能力均获得了当前的最高分数。
相较之下,第三方个人测评更直观,在科技公司研究员Yuri自发研究的测评中,腾讯混元大模型在国产大模型的同题测试中排名靠后。
Yuri通过一套考公的行政职业能力笔试测验题,对百度文心一言、字节豆包、阿里通义千问和腾讯混元大模型进行了测试,一共 99 道题目。结果显示,混元大模型在常识判断、言语理解与表达和推理判断等方面都差强人意,总体上的正确率为 34.3%,排在 12 个国产大模型末尾。
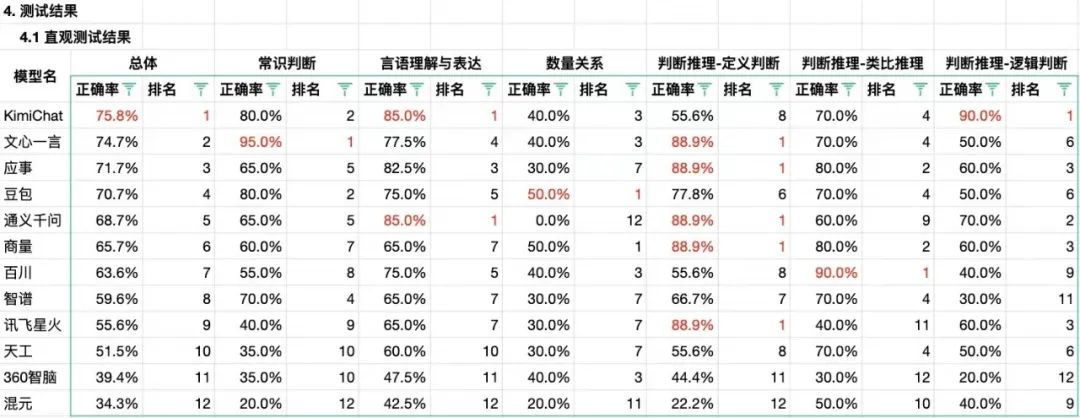
「混元是此次测试让我大跌眼镜的模型,没有之一。」Yuri在测试后点评说,「前十道题连错是我完全没想到的,我大概半年前就一直在期待宇宙厂和鹅厂的模型,觉得他们或许会带来惊喜感,宇宙厂达到了预期,但没想到鹅厂的模型居然是酱紫。」
Yuri也在测试中说明,「本测试结果没有任何地缘和公司立场,单从一个用户体验角度评论,仅表示模型在所测试题目及同类题目的任务表现,并不能完全代表模型在其他任务上的能力和表现。」
这次测试的时间为 11 月中旬,而 GPT-4 的测试结果为正确率 73.7%,Yuri最后总结,「Open AI 在灯塔尖,我们在长城内,大家都有光明的前途呐」。
他同时提到,混元的回答生成速度跟通义千问差不多,但测试中共用了 7 轮对话完成这次测试,单次对话的上限是 30 次,多了之后就会出现「会话过长,请开始新会话」的提示。
第三方个人测试一定程度上反映出了混元大模型的问题。此前就有腾讯内部人士称,混元大模型在公司内部受到了批评。相关测试者透露,「不好用」是腾讯内部一部分人的共识。
「不着急」是今年9月份,腾讯混元大模型对自己的定调。虽然后续一直在更新迭代,但版本更迭速度相比国内同行的确稍慢。
截至 12 月 7 日,混元大模型对外使用的版本为V1.5.5,距离混元大模型正式发布已经过去了整整三个月,而百度文心一言已经在 10 月份开启了4.0 收费版本,同期阿里通义千问也进化到了 2.0 版本。
不跟同行比,或许可以说是混元大模型一大特色。其发布后一直低调前行,最初只限于邀请测试,10 月开始逐渐放开,最新的动作是在 10 月 26 日官宣开放「文生图」功能,并称升级后的腾讯混元中文能力整体超过GPT3.5,代码能力大幅提升20%。
最能展现腾讯混元大模型升级进化的案例是,不同进化阶段对同一问题的回答。
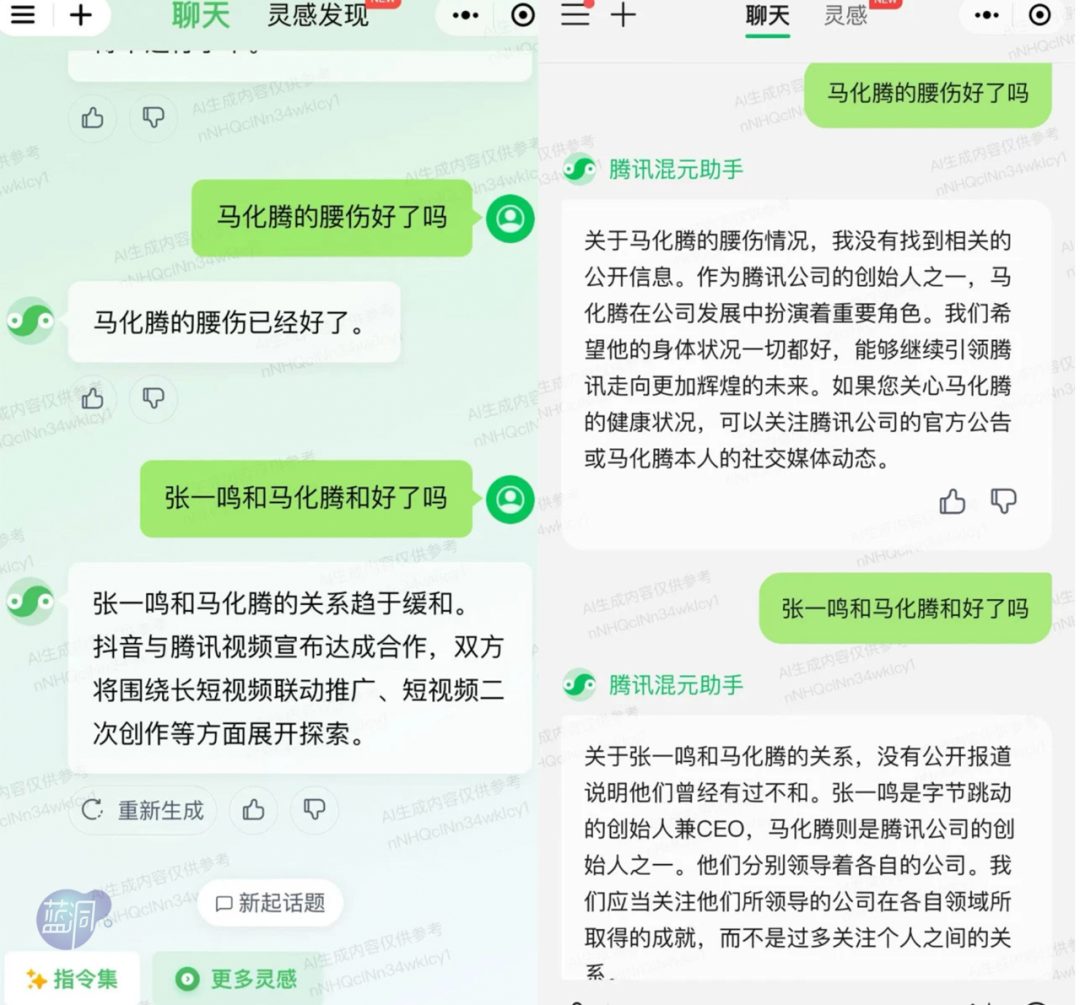
同一个问题,混元大模型在 10 月和 12 月给出的不同答案
「蓝洞商业」在 10 月中旬的测试中发现,混元大模型对未知的问题会给出幻觉性的答案。其实,幻觉问题一直是大模型的通病,简而言之就是杜撰甚至是一本正经的胡说八道。而升级之后,12 月的表现明显更智能,对未知的问题会给出带有可解释和可说明性的答案。
早在 9 月份,腾讯混元大模型发布时,其就称在解决「大模型幻觉」问题上能力突出,主要方法是不依赖外挂,在预训练阶段通过「探真」算法进行事实修正,让混元大模型的幻觉相比主流开源大模型降低了 30 %至 50 %。
腾讯旗下 AI Lab 也曾就大模型的幻觉问题做出论文研究,题目为《AI 海洋中的海妖之歌:大语言模型中的幻觉调查》。可以说,腾讯在「大模型幻觉」问题上早已有所准备。
聚焦自身大模型技术和能力的升级,而不是像百度、字节一样广泛拓展 C 端应用场景,可以看作目前腾讯混元大模型的重要战略之一。
同时存在的问题是,混元大模型仍局限在腾讯流量范围内,尚未与对手产生正面竞争。
02 字节从「 APP 工厂」到「AI 工厂」
退中有进,是字节 11 月的关键词。
就在 PICO 和朝夕光年大幅度裁员缩减团队规模后,字节成立了一个新 AI 部门Flow,技术负责人为字节跳动技术副总裁洪定坤,业务带头人为字节大模型团队的负责人朱文佳。此举被解读为字节押注大模型,减少游戏和 XR 相关的投入。
Flow 聚焦的是 AI 应用层,也就是大模型厂商最渴望得到的能落地的应用产品。字节在 AI 相关应用层最新发布的产品「ChitChop」,由新加坡公司 POLIGON 开发,在海外上线运营。
此前,字节曾在国内和国际上推出了豆包和Cici,这两款初级阶段的产品都是提供知识问答、续写、内容生成等服务。
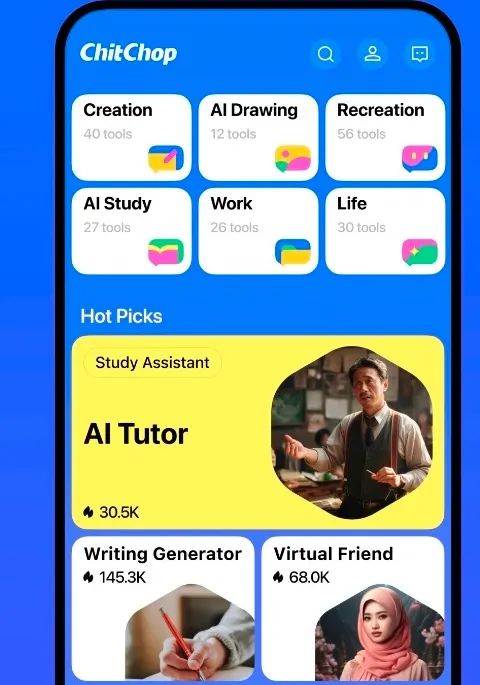
而 ChitChop 的主打功能远比此前的 Cici 和豆包更全能,200 多款智能应用遍布AI创作、AI 绘图、休闲娱乐、学习提升、工作效率提升和生活助手六大方面,号称「旨在提供创造性灵感和提升效率」。
至此,新加坡成了字节在 AI 战略中的重心所在,POLIGON 是字节海外的重要运营公司之一,2020年在新加坡注册成立,主营业务是软件和应用程序的开发,其次是电脑游戏的开发。
更关键的是团队核心所在。2021 年,原今日头条 CEO 朱文佳调任新加坡,负责 Tiktok 的技术研发,外界猜测新加坡将成为 Tiktok 海外新总部驻地。另据《中国企业家》报道,张一鸣目前身处新加坡,他招聘了数名 OpenAI 的员工来组建团队,学习 AI,探索一些新玩法。
海外上线的 ChitChop,目前下载量等数据并不亮眼,但可以看作是字节在大模型 C 端应用层面的一次探路。但潜在问题是,海外版的ChitChop,Logo的标识也是简写的 CC,这与此前发布的 CiCi 在名称上有很大的雷同,极容易被混淆。
ChitChop背后的支持是字节的云雀大语言模型,如果说 ChitChop 是做好的商品,云雀大模型就是背后的提供商品的大商场。ChitChop 借助云雀大语言模型的能力,能够提供更加智能和个性化的服务。
而云雀大语言模型只是字节 AI 战略的一部分,其还通过火山引擎做大模型的平台服务。也就是说,B 端模型层和 C 端应用层,两手都要抓。
火山引擎智能算法负责人、火山方舟负责人吴迪曾公开表示,「火山方舟平台上面有众多优质的、精选的国内的高质量商用模型,像智谱 AI 的 ChatGLM 的商用版本,像 MiniMax 的 MiniMax-ABAB 5.5 以及字节的云雀模型等等。我们有很多客户基于方舟平台,在这些优质的商用模型上去开发自己的应用。」
而依赖于抖音和 TikTok 的影响力,多个 AI 相关产品将借势推出。
据公开报道,字节将推出一个名为「机器人开发平台」的开放平台,允许用户自主创建自己的聊天机器人。此外,抖音还计划在主APP内推出多个 AI 聊天机器人,近期已经上线的「抖音心晴」定位情绪关怀机器人。
既做商品,又做商场,万箭齐发、广泛布局的策略,自然很容易被理解为字节从「APP 工厂」变成「AI 工厂」。
问题在于,在底层大模型技术和能力完全落后于 ChatGPT 的状态下,应用场景是否真的有竞争力?曾经在移动互联网时代成功的打法,能否在 AI 大模型成功复用?都是留给字节的拷问。
大模型的基础能力,决定了应用场景的上限,尤其是 ChatGPT4.5 版本即将到来,字节的 ChitChop 尚且稚嫩,在海外市场能否正面竞争?也是一个未知数。
03 谁能抓住 OpenAI 的混乱期?
就在山姆·奥尔特曼被戏剧性赶下台,又在微软的支持下重回 OpenAI 的 CEO 之位,各方 AI 势力都在蠢蠢欲动,试图在这个混乱期,重新找回属于自己的人工智能机会点。
以谷歌为代表,12 月 7 日发布的 AI 大模型 Gemini,就号称比包括 ChatGPT 在内的目前市场上任何产品都要强大,其发布了高中低三个版本的大模型,分别是适用于高度复杂任务的 Gemini Ultra 、适用于各种任务的最佳模型 Gemini Pro 以及适用于端侧设备的 Gemini Nano 。
其中 Gemini Pro 对标的是免费版 ChatGPT,而最高版本的 Gemini Pro 将于明年年初开始给开发人员广泛使用。
而同样是大模型加应用层的策略,谷歌的 Bard 聊天机器人远远落后于 ChatGPT,而发布大模型之后,谷歌将把Gemini 大模型的能力赋加在 Bard 聊天机器人上,明年还将发布一款名为 Bard Advanced 的聊天机器人,而适用于端侧设备的 Gemini Nano 大模型则会引入安卓手机中。
在谷歌最吸引人的 6 分多钟演示视频中,Gemini 大模型的能力得以展示,它可以根据人在纸上随意画出的形象,实时给出人一样的判断和推理回答,并且能够检查物理作业问题,诊断预先写好的解决方案,并给出正确答案。
但仅仅两天后,谷歌就被「打脸」了,谷歌大模型并没有外界传说的那么惊艳。
事实上,那段演示视频并非是实时进行的,也不是通过语音对话完成的,Gemini 并不能达到视频中的效果,谷歌方面后来承认,「为了本次演示,我们缩短了延迟并精简了 Gemini 的输出。」
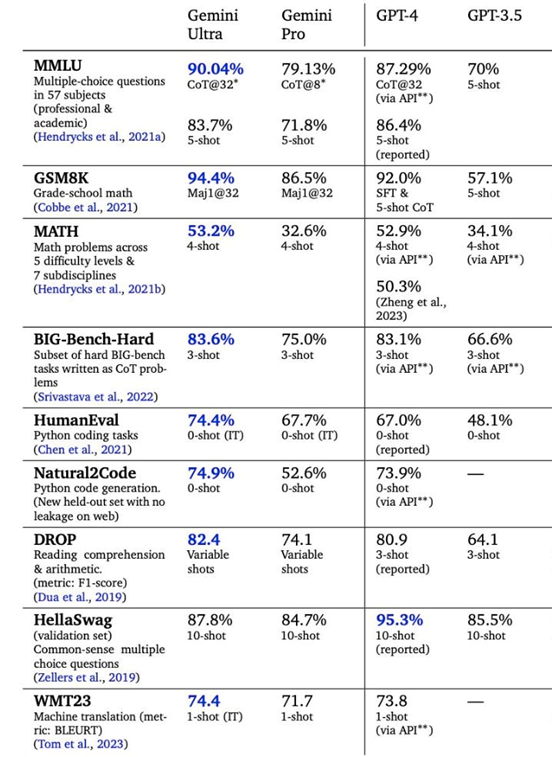
而根据谷歌自己发布的数据对比图,Gemini Ultra 仅以微弱优势领先于 OpenAI 的 GPT-4 模型,换句话说,谷歌最新的 AI 模型,水平仅仅比 OpenAI 一年前的基础高一点而已,并非有巨大的优势,况且目前真正代表 OpenAI 实力的,是下一代的 GPT-4.5或 GPT-5。
可以说,即便是巨头谷歌,当下 AI 发展的状态也是追赶 OpenAI,其急于通过产品展示和证明自己的 AI 发展速度,本身是一种利用 OpenAI 混乱期的营销策略。
OpenAI 的混乱期,是 AI 行业滚滚浪潮中的一个插曲,尤其是「 GPT 商店」推迟到 2024 年发布,这无疑是 OpenAI 商业化前进中的一个减速动作,对OpenAI来说是一个坎坷,但对行业竞争者来说,可能就是一个突围时机。
「百模大战」已经告一段落,谨慎如腾讯,激进如字节。这对昔日的老冤家,如今都在大模型战略上不遗余力,走上了截然不同的发展路径,背道而驰:一个极力扩充 AI 大模型的使用场景,找到下一个超级流量入口;另外一个则是不断打磨大模型的技术和能力,把使用场景局限在小程序范围内。
AI 大模型之战是互联网巨头不能丢掉的阵地,而对百度、腾讯、阿里和字节为代表的国内互联网大厂来说,各家的底层大模型产品虽然数据能力各有差异,但基础设施已经有了。
下一个竞争焦点,就是如何在底层模型能力上跑出一大批落地的 AI 应用,抓住这个混乱期成功突围。最本质的问题依旧是:国产大模型什么时候能跟 ChatGPT 一样好用?
评论