
文|娱乐资本论 James
“在这一轮大模型竞争中,千亿大模型并不需要那么多,但私有化百亿大模型会百花盛开。”
1月21日,猎豹移动CEO傅盛在猎户星空大模型的发布会上,当着视智未来等一众媒体的面为自家技术下的“小模型”站台,并做出2024年的“三大AI预言”。
今年6月,傅盛与金沙江创投董事总经理朱啸虎曾经在微信朋友圈激辩,是否应该停止围绕大模型的创业。后来两人还登上电视节目继续辩论。这次,傅盛在言语和行动上,都再一次回应了当初的争论。
不仅是傅盛VS朱啸虎,在过去一年里,李彦宏和他在搜索引擎领域的“宿敌”王小川,围绕文心追上ChatGPT还要“差几个月”也吵得火热。
回首过去一年,国内关于大模型发展路径的一些最响亮的声音,还是来自一些你熟悉的名字和面孔。大佬们在移动互联网时代已经叱咤风云,指点江山。这一次AIGC浪潮里,他们又给我们带来了多少思想碰撞,和茶余饭后的谈资?
比如在海外,海外马斯克和奥特曼关于是否要暂停研发GPT-4也有过激变,最终的结局则是马斯克买一万台GPU,旗下团队XAi发布首个大模型Grok……
下面就让娱乐资本论·视智未来带领各位读者,对上述国内两场大佬论战做一个简要回顾,看看到底是谁赢了?

VOL.1 李彦宏VS王小川
现状:李彦宏认为中国公司的机遇是大模型原生应用
搜索引擎和大模型似乎有天然的亲缘关系。国内最大搜索引擎百度,也同样因为公司在AI方面的技术积累,成为最早发布国产大模型产品的企业。
2023年2月,百度率先发布消息称,类似ChatGPT的产品将在一个月内上市。这是国内首次出现明确的OpenAI竞争者。
到了3月份,文心一言的首次发布会为稳妥起见,只是选择了屏幕录制的方式低调演示;但后来人们实际使用上还算满意,所以百度股价上演了先跌后回的过山车剧情。
3月份,李彦宏参加极客公园的直播,显得信心十足。他说,文心一言离 ChatGPT 版本,差距可能就是一两个月的差别。
“按照团队现在的分析,我们水平差不多是 ChatGPT 今年 1 月份的水平。但是大家早就忘了 1 月份它是什么样子,今天大家已经习惯 GPT-4,GPT-4 的技术跟我们只差一天出来,是一个其他大厂也很难去拿出一个东西相比的技术。”
此言一出,引来不少争论,争论的人当中就包括从搜狗出来,自己也想做大模型的王小川。
4月,王小川投身大模型创业,成立百川智能,豪言“年底要做出国内最好的大语言模型”。谈及“老朋友”李彦宏,王小川回复:“怎么可能只差两个月?采访的可能是平行世界的李彦宏,不是我们这个世界里的。”
他认为OpenAI比国内领先三年时间。追上GPT-3.5可能一年时间是有机会的,但目前OpenAI已经达到GPT-4的级别,GPT-5也在训练过程当中了,因此“追上”需要三年。
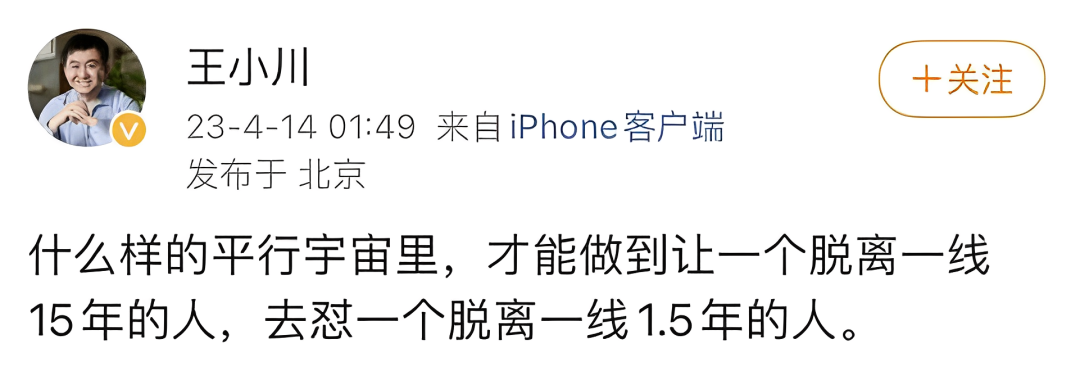
对此,百度集团副总裁、搜索平台负责人肖阳回应称,王小川脱离一线太久,对国内人工智能技术缺乏了解:“当年搜狗也立志取代百度搜索,结果也是显而易见的。所以很难评价,那我祝他成功吧。”
王小川又在微博回应:“什么样的平行宇宙里,才能做到让一个脱离一线15年的人,去怼一个脱离一线1.5年的人。”
眼看大家吵的有点上头,旷视科技联合创始人印奇表示,未来得看一家公司,无论大小,先把性能对标GPT-3.5的大模型真的做出来,这是所有事情的起点。
此后不久,5月4日晚,在百度内部一个颁奖活动上,李彦宏称“跟ChatGPT的差距大约是两个月”有点断章取义。是因为他后面紧接着说:“这不是重点,重点是这两个月的差距我们要用多长时间才能赶上,也许很快,也许永远也赶不上。”
那时国内已经出现了“百模大战”的趋势。此时文心跟ChatGPT之间的差距并没有明显拉近,但是其它基底大模型如雨后春笋般涌现,开发者从高校,到“AI 1.0”,再到姚班同学会等等,应有尽有。
对此,李彦宏在之后几乎每一次公开发言,都在“规劝”后来者别做模型了,你们已经晚了。
- 在被问到“中国创业公司里会不会再出一个OpenAI?”时,李彦宏的回答是“基本不会了”,还强调“没有必要再重新发明一遍轮子。”
- 在百度发布财报之后不久,李彦宏表示,市面上的大模型加起来调用量没有文心一言一家多。
- 2024年李彦宏说“我多多少少有点着急”,整个国内的AI大模型行业其实卷偏了。“卷AI原生应用才有价值,大模型的进展对绝大多数人都不是机会。”
另一方面,百川智能半年多来也有一些实际进展,平均每个月都有一款新模型发布。但王小川当时说的年底做出“国内最好”也没有成为业界公认的现实。
在极客公园的会上,王小川紧接着李彦宏之后露面。他的说法是,“不能猪肉还没吃过就想去造、去生产一头猪,这个步子跨的太大了”。
王小川认为,大模型开发需要强大的算力、财力和智力支持,所以“未来的两年时间内,更多的是加入一家(大模型)公司,能够获得平台级的支持,这样做超级应用成功的概率要大很多。”
这是他难得的跟李彦宏看法基本一致的少数时刻。新来的人只要不做自己的大模型,投靠到谁的旗下,都是好事。
VOL.2 傅盛VS朱啸虎
几乎在李彦宏和王小川激辩的同一时间,朱啸虎出席了一个活动,一只蝴蝶为3个月后的风暴扇动了一下翅膀。当时朱啸虎分享他对于当前消费产业和企业服务的投资看法。从投资的角度,他对于企服创业者的融资前景表现得更为悲观,而这很大程度上是因为他用到了ChatGPT。
“上个月我和大家讲,中国企服的春天可能还需要等5-10年。因为过去几年,投资人对企业服务的增长率特别失望。最近ChatGPT-4出来以后,我很抱歉地和大家说,企服的寒冬可能漫漫无期。”
他说:“ChatGPT太强大了,对创业公司很不友好。创业公司基于ChatGPT能够创造的价值非常单薄。”为证明这一点,他说Grammarly和Jasper都受到了GPT本体的“降维打击”。他认为功能单一的小创业公司很危险,但是“反而利好每个行业中的现有玩家。现在,已经拥有使用场景的玩家,通过ChatGPT很容易就能为自己的产品加上人工智能的功能。”
他认为,新进入企服行业的创业者还有两个机会:一是借着大玩家转向困难的机会,快速反应推出它们没做到的新产品形态;二是直接交付最终服务,比如呼叫中心就不要让人家用你的软件,而是直接让话务员下岗。
6月26日,傅盛转发了这篇演讲实录,并评论说:“硅谷一半的创业企业都围绕ChatGPT开始了,我们的投资人还能这么无知者无畏。”
这引发了朋友圈里的一场辩论,双方的观点和相关截图被广泛转发。

这场辩论这样开头:
朱啸虎:“99%的价值都是GPT创造的,这样的创业公司有什么价值?”
傅盛:“互联网99%的规范都是TCP/IP创造的,创业有价值吗?”
多轮交流后,傅盛认为大模型的未来在于构建平台生态,创业者可以在平台基础上做事;朱啸虎认为大模型时代的平台,有占绝对意义的实际价值,是不需要合作伙伴来实现的,平台自己就代劳了。因此,跟以往iPhone应用商店那种生态的共赢后果不一样,大模型时代只有零散的小机会,没有BAT级别的创业机会。
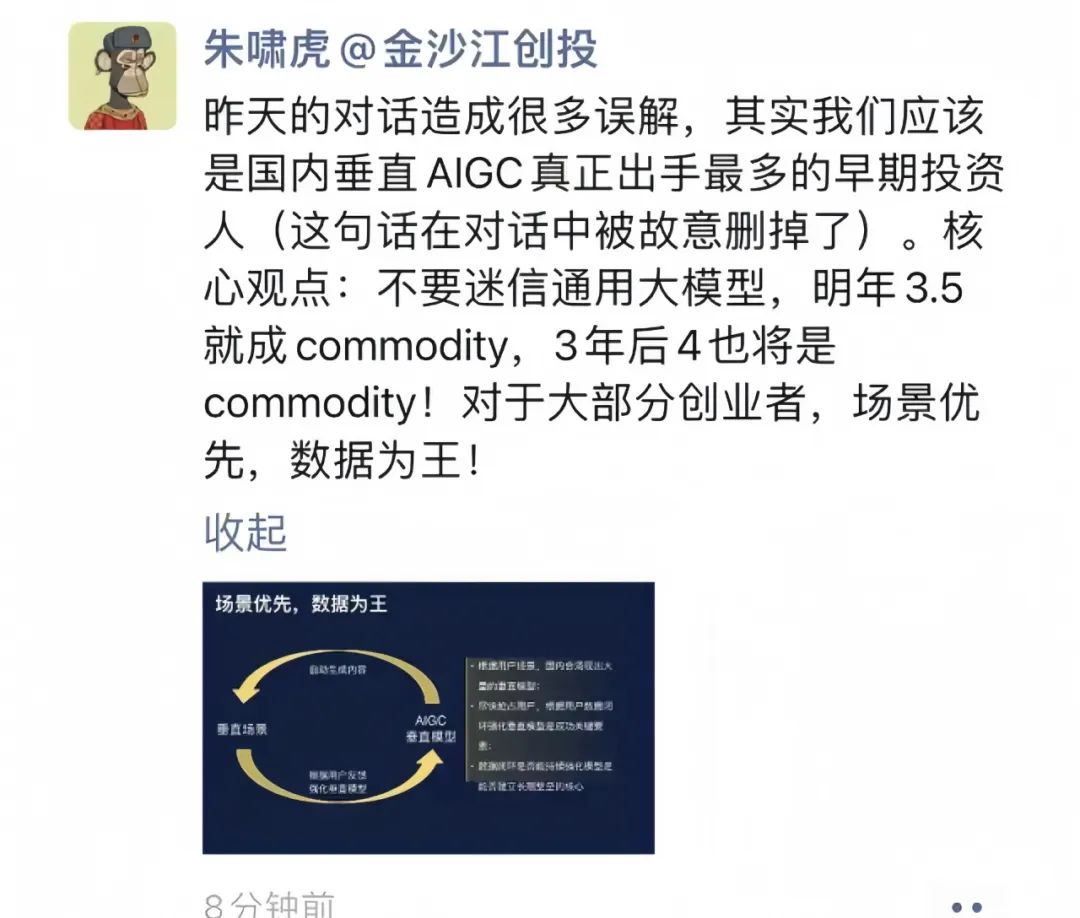
朱啸虎在争论后也发表了朋友圈,强调自己是国内对AIGC领域垂类创业者早期投资最多的人之一,并指出他的核心观点是:不要迷信通用大模型;对大多数创业者而言,场景优先,数据为王。
为了深入探讨这个话题,第一财经《头脑风暴》栏目请来了两人,就“大模型到底有没有创业价值”这一议题进行了线下辩论。
节目中,朱啸虎持续表示对大模型创业持保守态度,认为“百模大战”是个泡沫,并列举了三个理由:
1 通用大模型对创业公司无意义;
2 大模型的套皮应用没有价值;
3 能够达到商业化收入的,基本99%以上不是大语言模型的。
傅盛则反驳说:
1 他讨论的是大模型全行业有没有机会,被总结为“创业者不能做通用大模型”是偷换概念;
2 创业者身段更灵活,思考范式也是新的;
3 大模型应用现在不挣钱,不等于未来不挣钱。
最后,两人以下列共识握手言和:
不要为了兴趣去创业;
五年以后所有公司都应该是AI赋能的公司;
今天的创业技术越来越成熟,这个时候强调商业价值是对的。
朋友圈真是个神奇的地方,它把两人本来应该在线下交流中的对话保存下来,又让有意无意的“截图泄露”满足了大众强烈的吃瓜心愿。
但是到头来,这次火药味十足的争论有可能只是互相搞错了彼此的关注重点:朱啸虎的话是对初出茅庐的小年轻说的,但傅盛此时已经是一个拥有大模型“军备”,而且像李彦宏、王小川们一样,坐等着开发者投靠自己生态的大佬。要说傅盛担心什么,那可能就是怕朱啸虎的一番大白话,把下面的小开发者一起给吓跑了。
VOL.3 神仙打架,殊途同归
上面两场论战里,拥有大模型的三个人,最后放出的信息其实是一致的:不要做基底大模型,而是以他们做好的大模型为基础来做开发。
到年底,这种基础说法不变,不过大佬“允许”创业者们探索的业务,从单纯的API调用、GPTs(智能体)开发,扩大到了做垂类的小模型。
例如,周鸿祎对大模型的2024十大预测就说:大模型成为数字系统标配,无处不在;开源大模型迎来爆发;“小模型”涌现,运行在更多终端,等等。
与此同时,一些也有基座大模型诞生,但是家底没那么大的玩家,则对于前途充满忧虑,毕竟一不小心,自己就能从手握基底大模型的“大佬”行列,缩到只能在别人羽翼下炼垂类模型的小虾米。
1月16日,智谱AI 发布新一代基座大模型GLM-4时,CEO张鹏表示,“我们曾做过预测到2027年能实现稳定盈利,不过这个预测放在今天参考价值已经不大了。”他并不担心智谱AI的技术能力或产品能力。但要预测未来,需要考虑很多外部因素,包括AI行业的大环境变化,甚至是芯片、算力市场的走势,不是简单拍脑袋就能猜出来的。
论战当中涌现出的一些基础结论,也确实直到半年后的今天,依然具备映照现实的意义。例如“场景优先,数据为王”,这个说法充分概括了给金融、政企等领域做私有化大模型的各家服务商的核心竞争力所在。
由于有的数据无法复用,辛辛苦苦做了半天无法形成数据飞轮(即循环使用数据用于新的训练),有些服务商沦为所谓的“大模型包工头、施工队”,生意做得非常辛苦。娱乐资本论·视智未来此前的文章也集中关注了大模型中间层创业者的生存状态,和大模型行业何时能谈论盈利模式的问题。
AI大模型私有化正野蛮生长:仅4个月接到上市公司大单
对个人用户收费:国产大模型最勇敢的瞬间
不过,对于做基础模型的开发到底还有没有意义这个问题来说,如果你去问海外的大模型大佬,或许会给你不一样的答案。
目前国内“百模大战”中诸多大模型开发者,是基于Meta开源的LLaMA等一系列开源社区的基础代码,来进行二次开发的。其能力差异主要由语料库差异和少量微调等结合而成。
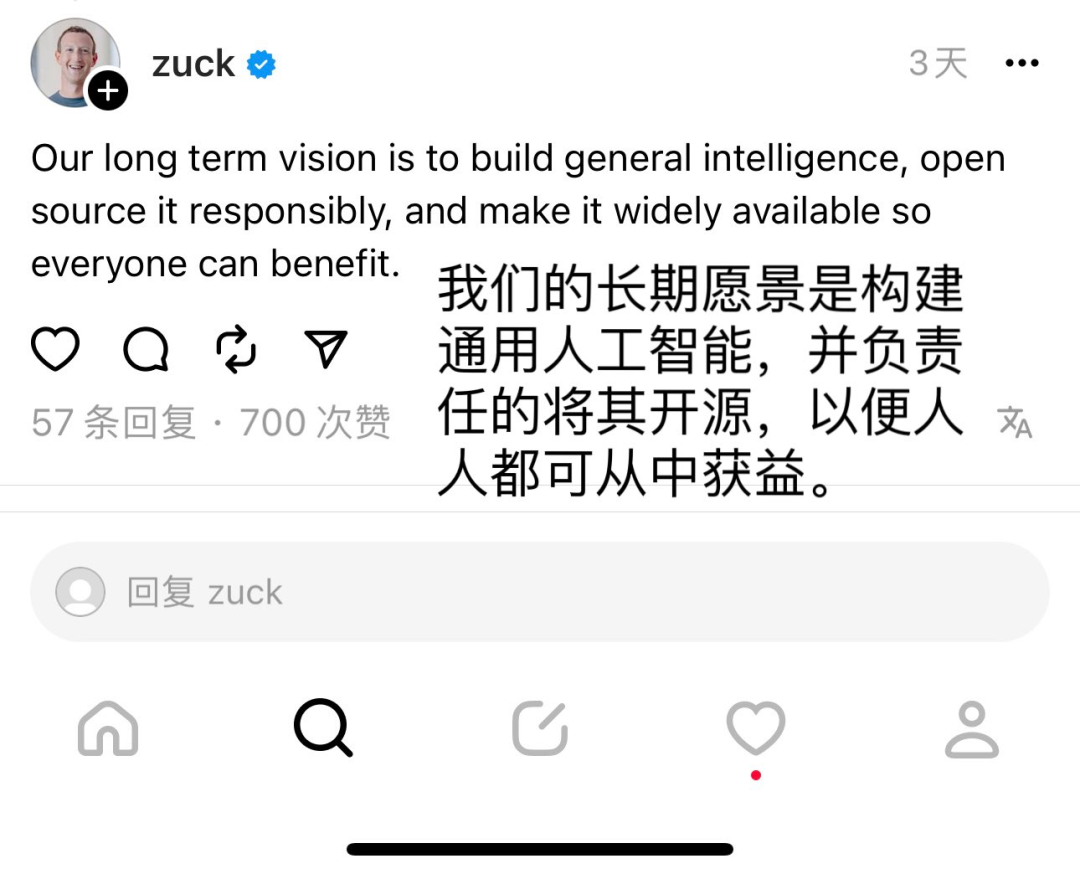
上周,Meta掌门人扎克伯格表示,公司希望建立所谓的“强人工智能”(AGI),并将其开源。公司将会斥资百亿美元构建强大的算力,以期待LLaMA的后续版本具备赶上和超越闭源的GPT等模型的能力,这样全世界最先进的AI能力就不会被OpenAI所垄断。
在过去一年中,大模型开发的主要进展集中在中国和美国,各种论战在这两个地方频繁发生。这些论战反映了两国不同的风格。
在美国,科学家、一线创业者、投资人在X(Twitter)上的争论,主要围绕人工智能是否会替代人类、通用/强人工智能的可能性,以及AI需要怎样的监管等议题。
硅谷的玩家们提出了一种被称为“有效加速主义”(e/acc)的价值观,主张不计代价、不考虑成本地前进。ChatGPT的飞跃性进展出现后,他们将功劳归于这种思想。然而与此相对的是,ChatGPT的所有者奥特曼去年下半年频繁出现在各种官方场合,呼吁对后来的人进行监管,多少有些过河拆桥的意味。
话说回来,自己在“中国版ChatGPT”浪潮初期快速占位,早早开发出基底大模型之后,就让开发者别再打这方面的主意,又何尝不是一种完全可以理解的“过河拆桥”呢?
并非所有的大模型玩家,都需要通过频繁发声争取资源。因为在过去一年中,做大模型的企业获得融资相对容易。而我们听到的声音,大多来自已经熟悉了大声喧哗的互联网业界资深大佬,他们或者需要抢占首发的注意力,或者要把明里暗里的竞争对手挤下去。
回顾这些大佬关于大模型的论战,实际上比各家官方公关稿中透露的信息,更能准确地向我们展示他们当时的发展程度。随着时间的推移,各方在大模型开发进展上趋于一致,因此他们的发言在年底也变得乏善可陈,大同小异。
他们都认为新来的人不应该再费力气做独立的大模型,而是应该投靠已有的基底模型,参与到共建生态当中。当然,这是因为他们自己将会是生态里的基底和组局者。
或许有句老话是正确的——“幸福的家庭都是相似的,不幸的家庭各有各的不幸。”
评论