

文|读懂财经
上周,AI行业发生了两件大事。
1月19日,Meta首席执行官扎克伯格宣布,Meta内部正在训练下一代模型Llama 3。截至今年年底,Meta将会有近35万块H100搭建的基础设施。1月21日,有媒体爆出消息,OpenAI CEO奥特曼正在筹集数十亿美元,建立一个全球性的AI芯片工厂网络。
这两件事其实都和一个东西有关——算力。
在生成式 AI 快速爆发的时代,算力短缺是运行 AI 模型面临的主要困难,GPT-4、Gemini、Llama 2 和其他模型严重依赖 H100 GPU,但H100产能却严重受限。即使像微软、Meta 这样大型科技公司,也需要提前数年预定产能,才能获得足够的新型芯片,更不用说OpenAI了。
AI产业算力短缺的根源在于,在摩尔定律主导下,性能每18-24个月翻一番的芯片,难以满足大模型参数规模的指数级增长。用OpenAI的话说,每年训练AI模型所需算力增长幅度高达10倍。这是瓶颈,也是机会。在新兴技术的故事里,成本才是影响大模型落地。

换言之,这场以大模型为名的千亿美金级豪赌实验,最终能否将世界带到新的摩尔时代,并不仅仅是看智能水平能提升到什么程度,更取决于模型发展会不会出现类似于摩尔定律的规律。
/ 01 / AI芯片,算力计算的“高地”
上周,Meta首席执行官扎克伯格宣布,到2024年底Meta将拥有35万块H100,拥有近60万个GPU等效算力。
35万块H100,是个什么概念呢?众所周知,训练大模型往往是最花费算力的阶段。OpenAI训练GPT-4,用了大约25000块A100 GPU。作为A100的升级版,据 Lambda 测算, H100 的训练吞吐量为A100的160%。也就是说,届时Meta拥有的算力是训练GPT-4所用算力的20倍以上。
买这么多算力,扎克伯格自然也花了大价钱。目前,一块英伟达H100售价为2.5万至3万美元,按3万美元计算,意味着小扎的公司仅购买算力就需要支付约105亿美元,更不用说电费了。
而这些算力很大部分将用于训练“Llama 3”大模型。扎克伯格表示,Meta将负责任地、安全地训练未来模型的路线图。
在打算力主意的不止是小扎,还有OpenAI的奥特曼。同样是上周爆出的消息,OpenAI CEO奥特曼正在筹集数十亿美元,建立一个全球性的AI芯片工厂网络。
目前,他正在和多家潜在的大型投资者进行谈判,包括总部设在阿布扎比的G42和软银集团。根据彭博社的报道,仅在OpenAI与G42的谈判中,涉及金额就接近80亿到100亿美元。
不过与小扎准备打富裕仗不同,奥特曼亲自下场制造AI芯片,更多是一种无奈。据外媒报道,这一事件背后的原因很可能就是,OpenAI已经无「芯」训练「GPT-5」了。
此前,奥特曼表示,OpenAI已经严重受到GPU限制,不得不推迟了众多短期计划(微调、专用容量、32k上下文窗口、多模态),甚至还一度影响到了API的可靠性和速度。
除了自己造芯外,OpenAI也在尝试通过其他方式来获得更低成本的算力。去年,就有媒体爆出,OpenAI从一家名为 Rain AI 的初创公司提前订购价值 5100 万美元的“神经形态”类脑人工智能芯片,于2024年10月开始供货。
当然,有自己下场造芯的可不止OpenAI一家,甚至进度快的微软、谷歌已经将自研芯片用到大模型上了。
比如,Microsoft Azure Maia 是一款AI加速器芯片,可发挥类似英伟达GPU的功能,用于OpenAI模型等AI工作负载运行云端训练和推理。而谷歌最新的AI 芯片TPUv5e在训练、推理参数少于2000亿的大模型时,成本也低于英伟达的A100或H100。
为什么所有大家都在绞尽脑汁搞算力,现在算力又发展到了什么程度呢?
/ 02 / 英伟达,AI芯片的“王”
按照算力基础设施构成来看,包括 AI 芯片及服务器、交换机及光模块、IDC 机房及上游产业链等。其中,AI芯片是其中的“大头”,能够占到服务器成本的55-75%。
从定义上说,能运行 AI 算法的芯片都叫 AI 芯片。按技术架构,可分为CPU、GPU、FPGA、ASIC及类脑芯片。虽然都叫AI芯片,但在擅长事情和应用场景上有很大的差异。
就拿我们最熟悉的CPU和GPU来说,GPU更像是一大群工厂流水线上的工人,适合做大量的简单运算,很复杂的搞不了,但是简单的事情做得非常快,比CPU要快得多。而CPU更像是技术专家,可以做复杂的运算,比如逻辑运算、响应用户请求、网络通信等。
看上去好像CPU比GPU更牛逼,但你不妨换个角度想,即使教授再神通广大,也不能一秒钟内计算出 500 次加减法,因此对简单重复的计算来说,单单一个教授敌不过数量众多的小学生。这就是为什么GPU被大量用户AI大模型训练的原因。
在一个大模型构建和迭代过程中,需要经过大量的训练计算工作。通常来说,训练一次是几乎不可能训练成功的,存在着大量的失败和反复,此外为保证模型迭代的更快,也需要进行大量的并行训练。即便打造出第一版大模型,后续模型的持续迭代的成本无法避免。
根据此前披露的消息,GPT-4的FLOPS约为2.15e25,并利用约25000个A100 GPU进行了90到100天的训练,如果OpenAI的云计算成本按每A100小时约1美元计算,那么在这样的条件下,训练一次GPT-4的成本约为6300万美元。
但就是这样一个支撑AI发展最重要的硬件领域,却被一家公司牢牢掌握着话语权,那就是英伟达。
用两组数据可以侧面证明英伟达在GPU领域的统治力:根据 Liftr Insights 数据,2022 年数据中心 AI 加速市场中,英伟达份额达 82%。根据不久前的数据,2023年人工智能研究论文中使用的英伟达芯片比所有替代芯片的总和多19倍。
毫无疑问,英伟达是去年以来AI浪潮的最大赢家。2022年10月到现在,英伟达的股价从110美元左右上涨到近600美元,涨了500%。FactSet数据显示,此前20个季度,英伟达有19个季度的业绩都优于市场预期。
2022年底,英伟达发布了最新的GPU产品——H100。相比A100,它的效率高达3倍,但成本只有(1.5-2倍)。更重要的问题是,受限于产能紧张,H100仍然供不应求。根据外媒报道,英伟达将在2024年,把H100的产量从去年的50万张左右直接提高到150-200万张。
英伟达的成功也说明了一件事情:在大模型军备竞赛里,最后挖矿的谁能赢不知道,但买铲子的一定赚钱,且短期内有高议价权。
/ 03 / 摩尔定律,跟不上大模型进化速度
既然AI芯片这么重要,那为什么还会如此短缺?归根到底,AI芯片的性能提升仍然受限于摩尔定律,远远赶不上大模型参数的规模增长。
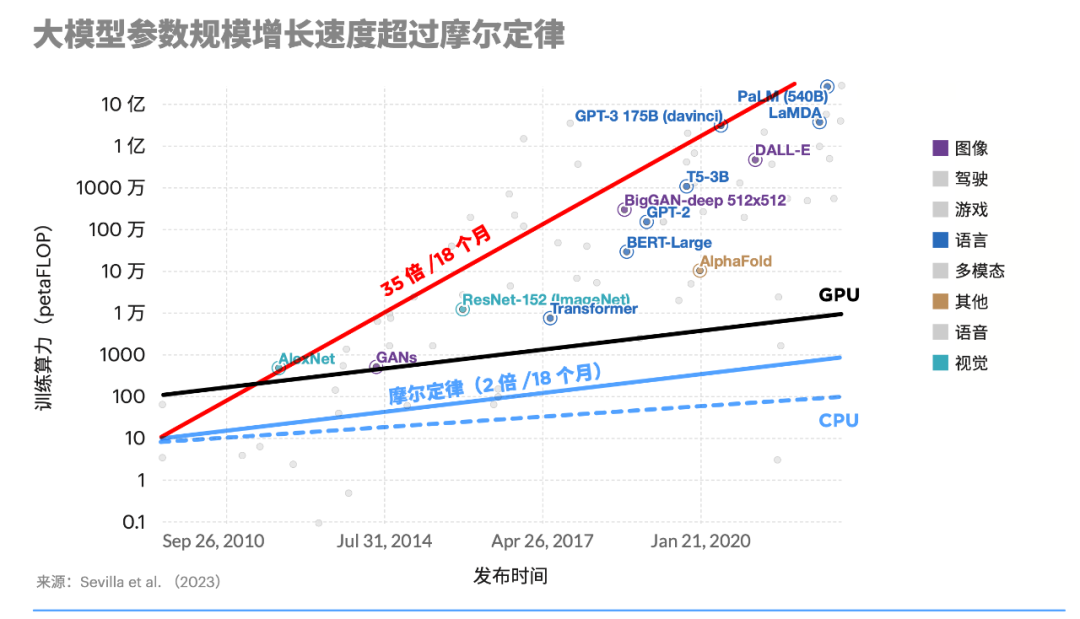
一些重点研究实验室报告称,公众对大语言模型的使用率达到了惊人高度。2021年3月,OpenAI宣布其GPT-3语言模型被“超过300个应用程序使用,平均每天能够生成45亿个词”,也就是说仅单个模型每分钟就能生成310万词的新内容。
在这种情况下,AI模型对算力需求的增长是惊人的。据OpenAI测算,自2012年以来,人工智能模型训练算力需求每3~4个月就翻一番,每年训练AI模型所需算力增长幅度高达10倍。
相比之下,GPU更迭效率仍然延续着摩尔定律。根据摩尔定律,芯片计算性能大约每18-24个月翻一番。从目前看,尽管H100相比A100性能有明显提升,但并没有像模型训练算力需求那样有明显数量级的增长。
在这种情况下,想要追求算力的增长,只能做更大规模的分布式训练。简单来说,就是用更多数量的机器,来满足训练所需的算力。这个方法的瓶颈在于,受网络传输的限制。目前,网络传输最大是800G,这意味着分布式训练的规模也不会无限制增长。
从种种迹象来看,巨型模型时代正在接近尾声。抛开缺少更多高质量训练数据的原因,算力硬件迭代速度和日益高涨的训练成本也是一个重要原因。根据拾象CEO李广密判断,未来几年OpenAI仅训练模型⾄少还得200-300亿美元,Google200-300亿美元,Anthropic100-200亿美元,算下来未来几年至少投入1000亿美元纯粹用到训练⼤模型。
在硬件提升有限的情况下,提高效率将成为很多大模型企业的选择。据谷歌 PaLM 的 论文,在训练阶段,缺乏优化经验或堆叠过多芯片,效率可能低至 20%,目前谷歌与 OpenAI 都能达到 50% 左右。前述机构推测目前推理阶段的效率只有25%左右,提升空间巨大。
在很多人看来,大模型更像一场千亿美金级豪赌实验,有机会将人类带入新的摩尔时代。在这个过程中,除了智能水平的提升,大模型训练、推理的成本下降会不会出现类似于摩尔定律的趋势,也是一个重要的观察维度。
从过去看,一个新技术能不能真正走向大规模落地,往往不取决于技术有多强,而是成本有多低。参考移动互联网应用大规模爆发,起于从3G到4G的所带来的流量成本大幅下降。从目前看,这样的故事大概率也将在人工智能领域发生。
评论