
文|光锥智能 郝鑫
编辑|王一粟 刘雨琦
2024年伊始,OpenAI再向世界扔了一枚AI炸弹——视频生成模型Sora。
一如一年前的ChatGPT,Sora被认为是AGI(通用人工智能)的又一个里程碑时刻。
“Sora意味着AGI实现将从10年缩短到1年”,360董事长周鸿祎作出预判。
但这个模型如此轰动,并不只是因为AI生成的视频时间更长、清晰度更高,而是OpenAI已经超越过去所有AIGC的能力,生成了一个与真实物理世界相关的视频内容。
无厘头的赛博朋克固然酷炫,但真实世界中的一切如何让AI重现才更具意义。
为此,OpenAI提出了一个全新的概念——世界模拟器。
在OpenAI官方出具的技术报告中,对Sora的定位为“作为世界模拟器的视频生成模型”,“我们的研究结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条可行之路。”

(图源:OpenAI官网)
OpenAI认为,Sora为能够理解和模拟真实世界的模型奠定了基础,这将是实现AGI的一个重要里程碑。凭借这一点,就彻底与AI视频赛道的Runway、Pika等公司拉开了一个段位。
从文字(ChatGPT)到图片(DALL·E )再到视频(Sora),对OpenAI来说,仿佛在搜集一张张的拼图,试图通过影像媒介形态彻底打破虚拟与现实的边界,成为电影“头号玩家”一般的存在。
如果说苹果Vision Pro是头号玩家的硬件外显,那么一个能自动构建仿真虚拟世界的AI系统,才是灵魂。
“语言模型近似人脑,视频模型近似物理世界”,爱丁堡大学的博士生Yao Fu表示。
“OpenAI的野心大得超出了所有人的想象,但好像也只有它能做到”,多位AI创业者对光锥智能感叹道。
Sora如何成为“世界模拟器”?
OpenAI新发布的Sora模型,一脚踹开了2024年AI视频赛道的大门,彻底与2023年以前的旧世界划出了分界线。
在其一口气释出的48个演示视频中,光锥智能发现过去AI视频被诟病的问题大部分得到了解决:更清晰的生成画面、更逼真的生成效果、更准确的理解能力、更顺畅的逻辑理解能力、更稳定和一致性的生成结果等等。
但这一切也不过是OpenAI显现出的冰山一角,因为OpenAI从一开始瞄准的就不是视频,而是所有存在的影像。
影像是一个更大的概念,视频是其中的一个子集,例如大街上滚动的大屏、游戏世界的虚拟场景等等。OpenAI要做的事情,是要以视频为切入口,涵盖一切影像,模拟、理解现实世界,也就是其强调的“世界模拟器”概念。
正如AI电影《山海奇境》制作人、星贤文化陈坤告诉光锥智能,“OpenAI在向我们展示它在视频方面的能力,但真正的目的在于获取人们的反馈数据,去探索、预测人们想要生成的视频是什么样的。就像大模型训练一样,一旦工具开放,就相当于全世界的人在为其打工,通过不断标记、录入,让其世界模型变得越来越聪明。”
于是我们看到,AI视频成为了理解物理世界的第一个阶段,主要突出其作为“视频生成模型”的属性;发展到第二个阶段,才能作为“世界模拟器”提供价值。
抓住Sora“视频生成”属性的核心在于——找不同,即Sora和Runway、Pika的差异性体现在哪里?这个问题至关重要,因为某种程度上解释了Sora能够碾压的原因。
首先的一点,OpenAI沿用了训练大语言模型的思路,用大规模的视觉数据来训练一个具备通用能力的生成模型。
这与文生视频领域“专人专用”的逻辑完全不同。去年,Runway也有过类似的计划,被其称之为“通用世界模型”,思路大致相似,但没有后续,这回Sora倒是先一步完成了Runway的梦想。
据纽约大学助理教授谢赛宁推算,Sora参数量约为30亿,虽然对比GPT模型显得微不足道,但是这个数量级已经远超了Runway、Pika等一些公司,可以称得上是降维打击。
万兴科技AI创新中心总经理齐镗泉,评价Sora的成功再次验证了“大力出奇迹”的可能性,“Sora依然遵循OpenAI的Scaling Law,靠大力出奇迹,大量数据,大模型和大量算力。Sora底层采用了游戏、无人驾驶和机器人领域验证的世界模型,构建文生视频模型,达到模拟世界的能力。”
其次,在Sora身上第一次展现了扩散模型与大模型能力的完美融合。
AI视频就像一部电影大片,取决于剧本和特效两个重要元素。其中,剧本对应着AI视频生成过程中的“逻辑”,特效则对应着“效果”。为了实现“逻辑”和“效果”,背后分化出了两条技术路径扩散模型和大模型。
去年年底,光锥智能就曾预判到,为了同时能够满足效果和逻辑,扩散和大模型两条路线终将走向融合。没想到,OpenAI如此迅速地就解决了这个难题。
(图源:OpenAI官网)
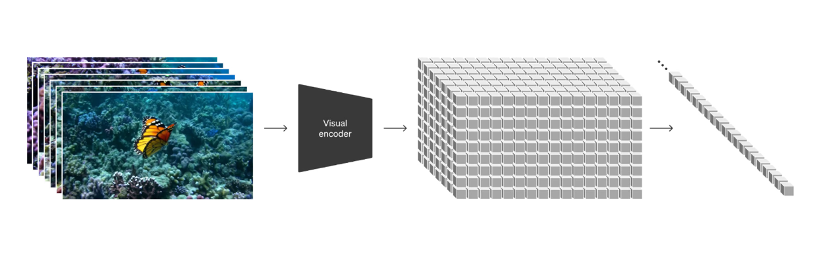
OpenAI 在技术报告中画重点提到:“我们将各种类型的视觉数据转化为统一表示法的方法,这种表示法可用于生成模型的大规模训练。”
具体来看,OpenAI将视频画面的每一帧都编码转化为了一个个的视觉补丁(patches),每个补丁都类似于GPT中的一个token,成为了视频、图像中的最小衡量单位,并且可以随时随地被打破、被重组。找到了统一数据的方式,统一了度量衡,也就找到了打通扩散模型和大模型的桥梁。
在整个生成的过程中,扩散模型仍在负责生成效果的部分,增加大模型Transformer的注意力机制后,就多了对生成的预测、推理能力,这也就解释了Sora为什么能够从现有获取的静态图像中生成视频,还能扩展现有视频或填充缺失的画面帧。
发展至今,视频模型已经呈现出复合的趋势,模型走向融合的同时,技术也在走向复合。
把之前沉淀的技术积累运用到视觉模型上,也成为了OpenAI的优势。在Sora文生视频的训练过程中,OpenAI就引入了 DALL-E3和GPT的语言理解能力。据OpenAI表示,DALL-E3、GPT基础上进行训练,能够使Sora准确地按照用户提示生成高质量的视频。
一套组合拳下来,结果就是出现了模拟能力,也就构成了“世界模拟器”的基础。
“我们发现,视频模型在进行大规模训练时,会表现出许多有趣的新兴能力。这些能力使Sora能够模拟物理世界中的人、动物和环境的某些方面。这些特性的出现并没有对三维、物体等产生任何明确的归纳偏差——它们纯粹是规模现象”,OpenAI表示道。
“模拟”之所以能够如此炸裂,根本的原因在于,用大模型创造出不存在的事物人们已经习以为常,但是能够准确地理解物理世界运转逻辑,例如力是如何相互作用的,摩擦是如何产生的,篮球是如何打出抛物线的等等,这些都是以前任何模型都无法完成的事情,也是Sora超越视频生成层面的根本意义所在。
不过,从demo到实际成品,可能是惊喜也可能是惊吓。Meta首席科学家杨立昆就直接对Sora提出了质疑,他表示:“仅凭能够根据提示生成逼真的视频,并不能说明系统真正理解了物理世界。生成过程与基于世界模型的因果预测不同,生成式模型只需要从可能性空间中找到一个合理的样本即可,而无需理解和模拟真实世界的因果关系。”
齐镗泉也表示,虽然OpenAI验证了基于世界模型的文生视频大模型是可行的,但也存在物理交互的准确性难点,尽管Sora能够模拟一些基本的物理交互,但它在处理更复杂的物理现象时可能会遇到困难;长期依赖关系的处理存在挑战,即如何保持时间上的一致性和逻辑性;空间细节的精确性,处理空间细节方面如果不够精确,可能影响到视频内容的准确性和可信度。
颠覆视频,但远不止视频
Sora成为世界模拟器或许是很久以后的事情,但是就生成视频而言,已经对现在的世界产生了影响。
第一类就是解决之前技术上面无法突破的问题,推动一些行业迈向新的阶段。
最典型的就是影视制作行业,Sora这回最具革命性的能力就是最长生成视频长度达到了1分钟。作为参考,大热门Pika所能生成的长度在3秒、Runway的Gen-2生成长度在18秒,这意味着有了Sora以后,AI视频将能成为真正的生产力,实现降本增效。
陈坤告诉光锥智能,在Sora诞生前,其利用AI视频工具制作科幻电影的成本已经下降至了一半,Sora落地后,更加值得期待。
Sora发布后,令他印象最深刻的是一个海豚骑车的demo。在那个视频中,上半身是海豚,下半身是人的两条腿,腿上还穿了鞋子,在一种极具诡异性的画风中,海豚完成了作为人骑自行车的动作。
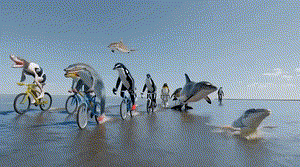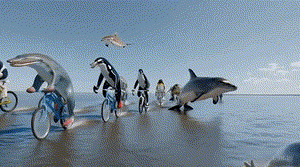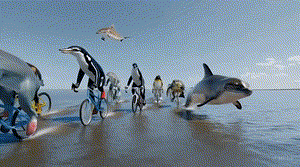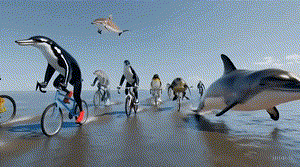
“这对我们来说简直太神奇了!这个画面创造出了一种又有想象空间,又符合物理定律的荒诞感,既是情理之中又出乎意料,这才是观众能发出惊叹的影视作品”,陈坤道。
陈坤认为Sora会像当年的智能手机、抖音一样,把所有内容创作者门槛降低一大步,把内容创作者呈数量级放大。
“未来内容创作者可能都不需要拍摄,只需要说一段话或者一段词,就能把脑子里面独特的想法表达出来,且可以被更多人看到。届时,我觉得还有可能会出现比抖音更大的新的平台。再往前一步,或许是Sora能够了解每个人潜意识的想法,自动去生成和创作内容,根本不需要用户去主动寻求表达”,陈坤表示道。
同样的行业还有游戏,OpenAI 技术报告的结尾是一个《我的世界》的游戏视频,旁边写着这样一句话:“ Sora可以通过基本策略同时控制Minecraft中的玩家,同时高保真地呈现世界及其动态。只需在Sora的提示字幕中提及‘Minecraft’,就能零距离激发这些功能。”

AI游戏创业者陈希告诉我们,“任何游戏从业者看到这句话,都是一身冷汗!OpenAI 毫无保留地展露了它的野心”。陈希解读分析认为,短短的一句话传达了两件事情:Sora能控制游戏角色,同时能渲染游戏环境。
“就如OpenAI 所说,Sora是一个模拟器,一个游戏引擎,一个想象力和现实世界的转换接口。未来的游戏,只要言之所及,画面就能被渲染出来。Sora现在学会了构建一分钟的世界,还能生成稳定的角色,再配合自家的GPT-5,一个纯AI生成的、数千平方公里、活跃着各色生物的地图,听上去已经不是异想天开。当然,画面是否能实时生成,是否支持多人联机,这些都是很现实的问题。但无论怎么说,新的游戏模式已经呼之欲出,至少用Sora生成一个《完蛋我被美女包围了》变得毫无问题了”,陈希道。
第二类是基于模拟世界的能力,在更多领域中创造出新的事物。
爱丁堡大学的博士生Yao Fu表示:“生成式模型学习生成数据的算法,而不是记住数据本身。就像语言模型编码生成语言的算法(在你的大脑中)一样,视频模型编码生成视频流的物理引擎。语言模型可以视为近似人脑,而视频模型近似物理世界。”
学会了物理世界中的普遍规律,让具身智能也更加接近人的智能。
例如在机器人领域,以前的传导流程为,先给到机器人大脑一个握手的指令,再传递到手这个部位,但是由于机器人无法真正理解“握手”的含义,所以只能把指令转化为“手的直径缩小为多少厘米”。若世界模拟器成为现实后,机器人就可以直接跳过指令转化的过程,一步到位理解人的指令需求。
跨维智能创始人、华南理工大学教授贾奎向光锥智能表示,显式的物理模拟将来就有可能应用到机器人领域,“Sora的物理模拟是隐式的,它展示出了只有其内部对物理世界理解和模拟才能生成出来的效果,要对机器人直接有用,我觉得还是显式的才行。”
“Sora能力还是通过海量视频数据,还有recaptioning技术,实现出来的,甚至也没有 3D 显式建模,更不用说物理模拟了。虽然其生成出来的效果,已经达到/接近了通过物理模拟实现的效果。但物理引擎能做的事情不仅仅是生成视频,还有很多训练机器人必须有的其他要素”,贾奎表示道。
虽然Sora还有许多局限性,但在虚拟和现实世界之间已经建立了一个链接,这让无论是头号玩家式的虚拟世界,还是机器人更像人类,都充满了更大的可能性。
评论