

文|读懂财经
在2022年的春节,OpenAI推出的ChatGPT快速引爆了资本圈与AI圈,至此拉开了AI大航海的序幕。
到了今年,类似的故事也在发生。2月16日凌晨,在没有任何预兆和消息透露的情况下,OpenAI 突然发布了自己的首个文生视频模型:Sora。很显然,这给了整个AI行业一点小小的震撼。
相比市面上现有的AI视频模型,Sora展示出了远超预期的能力:不仅直接将视频生成的时长一次性提升了15倍,在视频内容的稳定性上也有不小的提升。更重要的是,在公布的演示视频里,Sora展示了对物理世界部分规律的理解,这是过去文生视频模型一大痛点。
随着Sora的发布,另一个有趣的事情是,为什么总是OpenAI?要知道,在Sora发布前,探索AI视频模型的公司并不少,包括大众熟知的Runway、Pika,也取得了不错的进展。但OpenAI依然实现了降维打击。
这是一场典型的OpenAI式胜利:聚焦AGI这一终极目标,不拘泥于具体场景,通过Scaling Law,将生成式AI的“魔法”从文本延伸到了视频和现实世界。

在这个过程中,AI所创造的虚拟世界与现实世界的边界逐渐模糊,OpenAI距离AGI的目标也将越来越近。
/ 01 / 降维打击的Sora
在Sora发布前,大众对文生视频方案并不陌生。根据知名投资机构a16z此前的统计,截至2024年底,市场上共有21个公开的AI视频模型,包括大众熟知的Runway、Pika、Genmo以及Stable Video Diffusion等等。
那么相比现有的AI视频模型,Sora所展示出来的优势,主要集中在以下几点:
一是视频长度的巨大提升。Sora生成长达1分钟的超长视频,这样内容长度远远高于市面上的所有AI视频模型。
根据a16z统计,现有的AI视频模型制作的视频长度大都在10秒以内,像此前大热的Runway Gen 2、Pika,其制作的视频长度分别只有4秒和3秒。60秒的视频长度,也意味着其基本达到了抖音等短视频平台的内容要求。
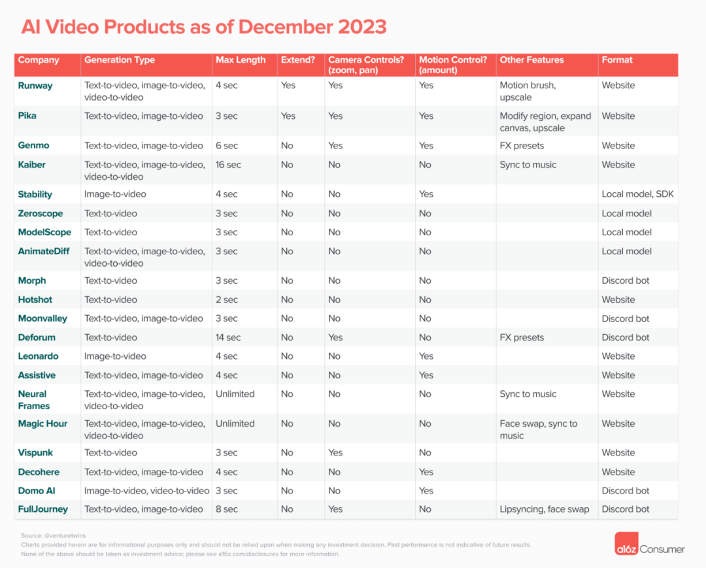
二是视频内容的稳定性。对AI视频来说,它们基本上是生成帧,在帧与帧之间创造时间上连贯的动画。但由于它们对三维空间以及物体应如何交互没有内在的理解,导致AI视频往往会出现人物扭曲和变形。
比如说,这样的情况经常会出现:片段的前半部分,一个人在在街道上行走,后半部分却融化在地面上——模型没有“坚硬”表面的概念。由于缺乏场景的三维概念,从不同角度生成相同片段也很困难。
但Sora的独特之处在于,其所制作的60秒视频不仅能够实现一镜到底,视频中的女主角、背景人物,都达到了惊人的一致性,各种镜头随意切换,人物都是保持了极高的稳定性。以下是Sora发布的演示视频:
Prompt: 一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信又随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。许多行人走来走去。
三是深刻的语言理解能力使Sora能够精准地识别用户的指令,从而在生成的视频中呈现出丰富的表情和生动的情感。这种深层次的理解不仅局限于简单的命令,Sora还理解这些东西在物理世界中的存在方式,甚至能够实现相当多的物理交互。
举个例子,就拿Sora对于毛发纹理物理特性的理解来说,当年皮克斯在制作《怪物公司》主角毛怪时,为能呈现其毛发柔软波动的质感,技术团队为此直接连肝几个月,才开发出仿真230万根毛发飘动的软件程序。而如今Sora在没有人教的情况下,轻而易举地就实现了。
“它学会了关于 3D 几何形状和一致性的知识,”项目的研究科学家Tim Brooks表示。“这并非我们预先设定的——它完全是通过观察大量数据自然而然地学会的。”
毫无疑问,相比于其他“玩具级”的视频生成AI,Sora在AI视频领域实现了降维打击。
/ 02 / 把视觉数据统一起来
从技术层面来说,图片生成和视频生成的底层技术框架较为相似,主要包括循环神经网络、生成对抗网络(generative adversarial networks,GAN)、自回归模型(autoregressive transformers)、扩散模型(diffusion models)。
与Runway、Pika等主流AI视频聚焦于扩散模型不同,Sora采取了一个新的架构——Diffusion transformer 模型。正如它的名字一样,这个模型融合了扩散模型与自回归模型的双重特性。Diffusion transformer 架构由加利福尼亚大学伯克利分校的 William Peebles 与纽约大学的 Saining Xie 在 2023 年提出。
在这个新架构中,OpenAI沿用了此前大语言模型的思路,提出了一种用 Patch(视觉补丁)作为视频数据来训练视频模型的方式,是一个低维空间下统一的表达单位,有点像文本形式下的Token。LLM把所有的文本、符号、代码都抽象为Token,Sora把图片、视频都抽象为Patch。
简单来说,OpenAI会把视频和图片切成很多小块,就像是拼图的每一片一样。这些小块就是Patch,每一个补丁就像是电脑学习时用的小卡片,每张卡片上都有一点点信息。
通过这种方式,OpenAI能够把视频压缩到一个低维空间,然后通过扩散模型模拟物理过程中的扩散现象来生成内容数据,从一个充满随机噪声的视频帧,逐渐变成一个清晰、连贯的视频场景。整个过程有点像是把一张模糊的照片变得清晰。
按OpenAI的说法,将视觉数据进行统一表示这种做法的好处有两点:
第一,采样的灵活性。Sora 可以采样宽屏 1920x1080p 视频、垂直 1080x1920 视频以及介于两者之间的所有视频(如下列3个视频)。这使得 Sora 可以直接以其原生宽高比为不同设备创建内容,快速以较低尺寸制作原型内容。
第二,取景与构图效果的改善。根据经验发现,以原始宽高比对视频进行训练可以改善构图和取景。比如,常见的将所有训练视频裁剪为正方形的模型,有时会生成仅部分可见主体的视频。相比之下,Sora 的视频取景有所改善。
为什么OpenAI能够想到将视觉数据进行统一表示的方法?除了技术原因外,也很大程度上得益于OpenAI与Pika、Runway,对AI视频生成模型的认知差异。
/ 03 / 世界模型,通过AGI的道路
在Sora发布前,AI 视频生成往往被人看作是AI应用率先垂直落地的场景之一,因为这很容易让人想到颠覆短视频、影视/广告行业。
正因为如此,几乎所有的 AI 视频生成公司都陷入了同质化竞争:过多关注更高画质、更高成功率、更低成本,而非更大时长的世界模型。你能看到,Pika、Runway做视频的时长都不超过 4s 范围,虽然可以做到画面足够优秀,但物体动态运动表现不佳。
但OpenAI对AI视频生成的探索更像是沿着另一条路线前进:通过世界模型,打通虚拟世界与现实世界的边界,实现真正AGI。在OpenAI公布的Sora技术报告里,有这样一句话:
“我们相信Sora今天展现出来的能力,证明了视频模型的持续扩展(Scaling)是开发物理和数字世界(包含了生活在其中的物体、动物和人)模拟器的一条有希望的路。”
世界模型,最早是由Meta 首席科学家杨立昆(Yann LeCun)在2023 年 6 月提出的概念,大致意思是可以理解为是要对真实的物理世界进行建模,让机器像人类一样,对世界有一个全面而准确的认知,尤其是理解当下物理世界存在的诸多自然规律。
换言之,OpenAI更愿意把Sora 视为理解和模拟现实世界的模型基础,视为 AGI 的一个重要里程碑,而不是AI应用落地的场景。这意味着,相比其他玩家,OpenAI永远用比问题更高一维度的视角看待问题。
在实际情况里,这会让解决问题变得更加容易。正如爱因斯坦说过,我们不能用创造问题时的思维来解决问题。从这个角度上说,也能够解释为什么OpenAI总能时不时给行业来点小震撼。
尽管从目前看,AI生成的视频仍然有着各种各样的问题,比如模型难以准确模拟复杂场景的物理,也可能无法理解因果关系的具体实例,但不可否认的是,至少Sora开始理解部分物理世界的规则,让眼见不再为实,基于物理规则所搭建的世界真实性遇到前所未有挑战。
当大模型从过去文本中学习的模式,开始转为向视频和真实世界学习。随着Scaling Law的逻辑在各个领域涌现,或许赛博世界与物理世界的边界将变得更加模糊。
评论