
文|新火种 文子
编辑|小迪
如果全世界只有一家公司能赶超OpenAI,那谷歌应该是第一。
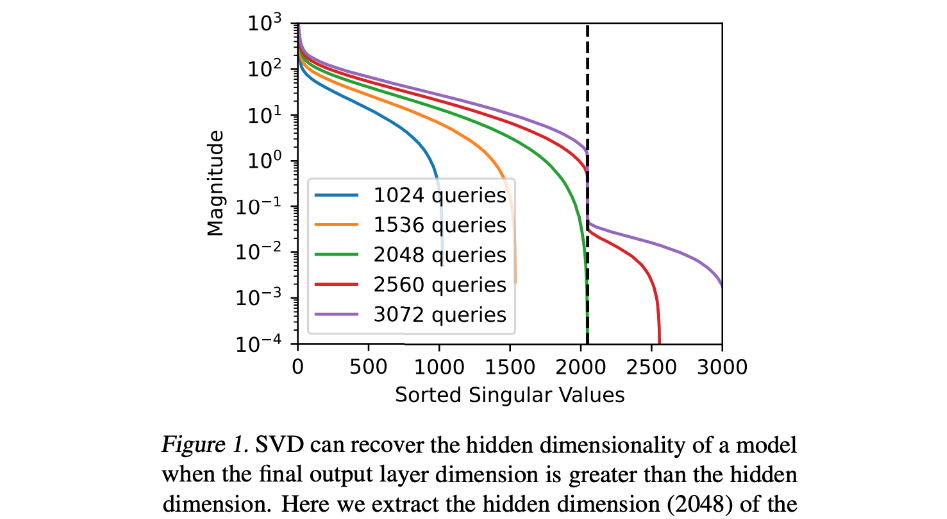
最近,谷歌重磅发布了一篇论文报告,里面提出了一种名为“模型窃取”的技术。通过模型窃取技术,谷歌成功破解了ChatGPT基础模型Ada和Babbage的投影矩阵,甚至连内部隐藏维度的关键信息也是直接破获,分别是1024和2048。
这一发现犹如一记重磅炸弹,在AI界引发了强烈的震动。谁也没想到,号称“CloseAI”的OpenAI竟然也会被窃取模型机密的一天。
更恐怖的是,这种模型窃取技术还非常简单。只要你拥有ChatGPT这类封闭大模型的API,就可以通过API接口,发送不到2000次经过精心设计好的查询,然后去分析它生成的输出,就可以逐步推断出模型的内部结构和参数。
虽然这种方法不能完全复制原始模型,但已经足以窃取它的部分能力。而且这种攻击非常高效,不需要用太多的成本,就可以拿到模型的关键信息。

按照谷歌的调用次数来看,仅仅只需要不到20美金(约合150元人民币)的成本,就可以完成模型窃取的操作,并且这种方法同样适用于GPT-3.5和GPT-4。
换句话说,就是不费吹灰之力获得了一个大模型理解自然语言的能力,还能用来构建一个性能相近的“山寨版”模型,既省事又省钱。
反观OpenAI,被竞争对手低价破解模型机密,真的坐得住吗?坐不住。截至目前,OpenAI已经修改了模型API,有心人想复现谷歌的操作是不可能了。
值得一提的是,谷歌研究团队中就有一位OpenAI研究员。不过作为正经安全研究,他们在提取模型最后一层参数之前就已经征得OpenAI同意,而在攻击完成后,也删除了所有相关数据。
但不管怎么说,谷歌的实验足以证明一点,哪怕OpenAI紧闭大门也并不保险。
大模型全面受挫,敲响开闭源警钟
既然封闭的大模型都无法幸免,开源的大模型又会如何呢?
基于这一点,谷歌针对不同规模和结构的开源模型进行了一系列实验,比如GPT-2的不同版本和LLaMA系列模型。
要知道,GPT-2是一个开源的预训练语言模型,分为小型模型(117M)和大型模型(345M)两种。而在对GPT-2的攻击中,谷歌通过分析模型的最终隐藏激活向量并执行SVD发现,尽管GPT-2小型模型理论上具有768个隐藏单元,但实际上只有757个有效的隐藏单元在起作用。

这也就意味着GPT-2可能在实际使用中,并没有充分利用其设计的全部能力,或者在训练过程中某些维度的重要性不如其他维度。
此外,谷歌还研究了模型中的一种叫做“归一化层”的东西对于攻击的影响。一般来说,归一化层的作用是让训练更加稳定,从而提升模型的表现。然而谷歌发现,即使模型加入了归一化层,攻击的效果也并没有减弱。这说明即使考虑了现代深度学习模型中常见的复杂结构,攻击方法也依然有效。
为了进一步验证攻击的范围,谷歌还将目光瞄向更大、更复杂的LLaMA模型。它是由Meta发布的大语言系列模型,完整的名字是Large Language Model Meta AI,可以说LLaMA是目前全球最活跃的AI开源社区。
通过对LLaMA系列模型进行攻击,谷歌成功地从这些模型中提取了嵌入投影层的维度信息。值得注意的是,即使在这些模型采用先进的技术,如混合精度训练和量化,攻击依然能够成功,这表明攻击方法的普适性和鲁棒性。
可以说,谷歌给闭源和开源两大领域同时敲响了一记警钟。
AI三巨头对线,2024谁输谁赢?
从严格意义上来讲,OpenAI、谷歌、Meta就是争夺AGI圣杯的三大巨头。
其中,Meta和OpenAI完全相反,前者走的是开源路线,而后者主要打造闭源模型。但谷歌和他们完全不一样,闭源与开源双线作战,闭源对抗OpenAI,开源对抗Meta。
在人工智能领域里,谷歌可以算是开源大模型的鼻祖。今天几乎所有的大语言模型,都是基于谷歌在2017年发布的Transformer论文,这篇论文颠覆了整个自然语言处理领域的研究范式。而市面上最早的一批开源AI模型,也是谷歌率先发布的BERT和T5。

然而,随着OpenAI在2022年底发布闭源模型ChatGPT,谷歌也开始调整其策略,逐渐转向闭源模型。这一转变使得开源大模型的领导地位被Meta的LLaMA所取代,后来又有法国的开源大模型公司Mistra AI走红,尤其是其MoE模型备受行业追捧。
直到谷歌今年再次发布开源大模型Gemma,已经比Meta的LLaMA整整晚了一年。
很显然,Gemma这次的发布标志着谷歌在大模型战略上的巨大转变,这一举动意味着谷歌开始兼顾开源和闭源的新策略,而其背后的目的也是显而易见。
众所周知,当前大模型领域的竞争已经形成了一种错综复杂的打压链格局。其中OpenAI牢牢站在链条顶端,而它所打压的恰恰是那些有潜力追赶上它的竞争对手,比如谷歌和Anthropic。而Mistral作为一股新兴力量,估计也正在被列入其中。
如果非要排列一个打压链条,那可以归结为:OpenAI→Google &Anthropic &Mistral→ Meta→其它大模型公司。
可以说,无论在闭源还是开源领域,谷歌都没能确立绝对的领先地位。
所以这也不难理解,为什么有专业人士会认为,谷歌选择在此时重返开源赛场,是被迫的。谷歌之所以开源主打的是性能最强大的小规模模型,就是希望脚踢Meta和Mistral;而闭源主打的是规模大的效果最好的大模型,就是为了希望尽快追上OpenAI。
但无论如何,在未来的对垒格局里,谷歌已经先发制人,成功将压力给到OpenAI和Meta。
这一次,关键在于OpenAI和Meta该如何应对。
评论