

界面新闻记者 |
界面新闻编辑 | 文姝琪
凭借“长文本”标签,月之暗面从国内一众AI大模型公司中脱颖而出,打破了这个行业在产品上大同小异、技术上难分伯仲的刻板印象。
去年10月,由杨植麟创办的月之暗面发布首款大模型产品智能助手Kimi Chat,将上下文窗口长度扩展至20万字。彼时,Anthropic的Claude2-100k和OpenAI的GPT4-32k支持的最长文本分别为100K(约8万汉字)和32K(约2.5万汉字),Kimi是这两者的2.5倍和8倍。
这一步踩对了C端(用户端)需求的节奏,大模型技术规模化应用的可能性被刻画出更清晰路径。用户蜂拥而至,Kimi日活用户从10万规模直逼百万量级。
一把火扔进了迷雾中的行业,此前喧嚣沸腾但迟迟找不到亮光的竞争者纷纷卷入“长文本”浪潮,百川智能的Baichuan2-192K(约35万汉字)、零一万物的Yi-34B(约40万汉字)等大模型先后打破Kimi的记录。
但不等半年时间,Kimi重新夺回主动权,并将风浪掀得更高。

3月18日,Kimi将上下文输入限制突破至200万汉字。这轮热度一度致其小程序宕机,甚至于在二级市场形成Kimi概念股板块,一家创业公司左右资本情绪的戏码罕见上演。互联网大厂亦开始明牌上桌,阿里通义千问开放1000万字长文档处理功能,百度文心一言也即将释放200万至500万长度处理能力。
长文本战场的火药味渐浓,但长文本是否有极限?它对实现AGI(通用人工智能)和大模型技术的应用层繁荣有什么意义?在这场行动陷入无意义漩涡之前,行业理应对此抱有答案。
直面技术矛盾
由上下文窗口长度所决定的长文本能力是指,语言模型在进行预测或生成文本时,所考虑的前一个词元(Token)或文本片段的大小范围。
上下文窗口越大,大模型可以获得的语义信息也越丰富,有助于消除歧义、生成更加准确的文本。云从科技技术管理部负责人在接受界面新闻采访时表示,以长上下文为重点突破更加贴近人类记忆的特点,相当于扩展了AI的记忆库,让AI可以参考更多历史记忆信息,给出更准确的输出。
对于多轮对话、长文档处理等场景中,一定长度的上下文窗口是大模型能否高质量完成交流的必要条件。在基础大模型频繁迭代的2023年,长文本能力也一直是主流大模型厂商关注的焦点。
但是上下文窗口、模型智能水平、算力成本之间始终存在着矛盾。
Transformer架构中的注意力机制,需要消耗算力来计算Token与Token之间的相对注意力权重。当上下文窗口显著增大时,模型每次可以处理的文本范围变得更广,但这也意味着每次处理所需的计算资源会大幅增加。因此,尽管每次处理的文本量更大,但由于算力资源限制,模型在整个生命周期内能够处理的总Token数量会减少,导致模型的理解能力下降。
针对这一点,学界自2019年起便开始针对“efficient Transformer”(高效Transformer)为目标进行研究,也出现了诸如稀疏注意力机制等解决方案。核心思路在于通过限制模型必须计算的关系数量,减少计算负担和存储需求,从而提高处理长序列时的效率。
“未来真正要追求无损长文本以及高效推理的话,那改进Transformer架构使其更高效还是很必要的。”波形智能CTO周王春澍表示。
即便是在模型本身的上下文窗口受限的前提下,业内也存在着RAG(Retrieval-Augmented Generation,检索增强生成)等技术路线来实现与超长文本能力类似的效果。即,使用检索系统从一个大型的文档集合中检索出与输入序列相关的文档,然后将这些文档作为上下文信息输入到生成模型中,以辅助生成过程。
在通义千问打出1000万字的长文档处理功能、360预告500万字的长文档处理能力后,一个业内普遍存在的推测就是,这类功能是通过RAG辅助之后,基于基座模型本身的上下文窗口实现的;如果由大模型完成千万汉字长文本的处理,那所耗费的算力资源会相当惊人,不具备商用价值。
月之暗面在这轮“长文本之争”的特殊之处在于,杨植麟此前在接受采访时曾明确表示,不会采用小模型、降采样、滑动窗口等形式来提升上下文窗口。在200万字上下文对外发布时,月之暗面工程副总裁许欣然也多次强调,此次上下文长度的提升是“无损”前提下进行的,不会影响模型的智能水平。
在Kimi宣布将上下文窗口拓展至200万汉字时,Anthropic所发布的Claude3上下文窗口为200K(Claude2 100K上下文窗口实测约8万汉字),百川智能发布Baichuan2-192K大模型能够一次处理约35万个汉字。从这一点上看,Kimi站稳了长文本能力这一产品定位。
Gangtise投研分析师表示,目前Kimi模型的日活跃用户数已达100万人,预计月活跃用户数约为500万人。其中小程序端日活跃用户数达60万人,网页端达34万人,APP端达5万人,留存率也在持续上涨。若Kimi模型保持当前增长趋势,小程序端市场地位可能显著提升。
角逐长文本的意义
从基础模型本身的上下文窗口来看,Kimi在一众大模型厂商中表现突出。但从长线来看,这能否构成核心壁垒仍有待讨论。
除去算法层面的优化,多位从业者告诉界面新闻,拓展上下文窗口的另一个限制在于显存容量与显存带宽。
“这其实是一个工程优化的问题。”周王春澍说,在计算资源相同的前提下,上下文窗口的增大会对能够处理的Token数产生影响。换言之,增加计算资源或者使计算资源的利用更高效,是达成长上下文窗口的最直接方案。
受Kimi模型的火热市场反应影响,阿里通义千问、百度文心一言、360迅速公布或预告自己的长文档处理功能。尽管在业内的普遍猜测中,上述产品的长文档处理能力是出自RAG辅助的结果,但是实际效果也证实RAG的路线能够实现与超长文本能力相近的效果。
“如果能确保知识定位的准确性,比如长文本的Chunking(分块)做的比较好、RAG工程优化也比较好的话,其实在涉及到一些推理的Benchmark(基准)上,RAG和长下文的方案在效果上没有本质性的区别。”周王春澍说。
在C端场景中,百万字级别的长文本能力可以延伸出财报解读、总结论文等多种需求,但是在更为广泛的B端(企业端)场景,模型本身过于长的上下文窗口反而会成为ROI的负累。
“上下文再长也不大可能长过动辄GB、TB级别的企业级数据,”叶懋认为,“在私有化部署过程中,长上下文很难一下覆盖这些非结构化数据,即使能覆盖,响应速度和算力需求方面的问题也会更加突出。”
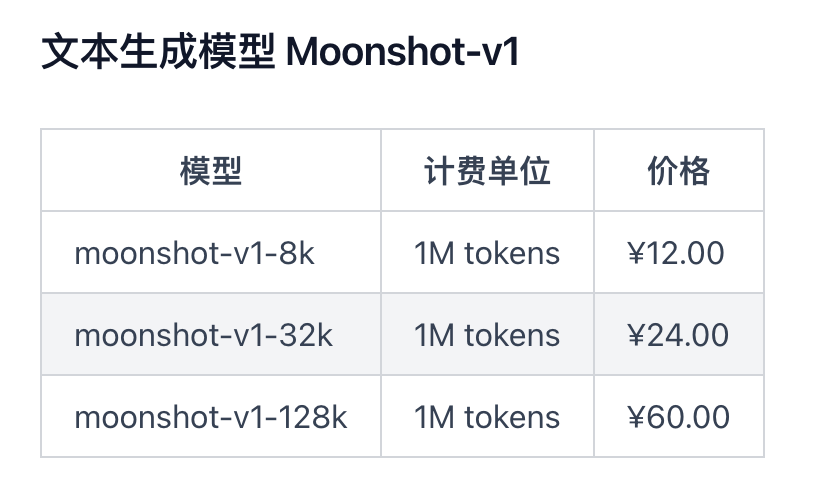
月之暗面官网显示,大致来说,对于一段通常的中文文本,1Token大约相当于1.5至2个汉字。如果按200万字粗略计算,使用moonshot-v1-128k的API接口的费用约在60元左右。而据周王春澍所说,如果使用RAG方案,可能需要的成本就只在一分钱或者一毛钱以内。
RAG与长文本能力之间的补足关系在B端场景中体现得尤为明显。在波形智能的商业实践中,与200K左右上下文窗口的模型方案相比,企业客户更倾向于选择RAG外挂数据库+8K左右上下文窗口的模型方案。
“在使用量比较多的场景下,很难想象大家会完全抛弃RAG,然后把上下文全给用起来。”周王春澍将RAG与长文本能力形容作个人计算机领域的CPU高速缓存和内存,两者相互配合完成运算任务。
而当一种更具性价比、且效果相近的方案存在时,基础模型是否有必要持续扩充上下文窗口就成了有待考虑的问题。
诚然,在追求AGI的路上,足够长的上下文窗口必不可少,但在目前这个阶段,成本、性能与长文本之间的“不可能三角”也确实为长上下文窗口的基础模型的实用性打上了问号。
一名关注AI大模型技术领域的投资人表示,当他看见行业出现这种普遍表征的时候,内心实感是各家公司确实在为抢入头部阵营做成绩,但这件事本质上还是“秀肌肉”。
如果真的要对估值增长产生实际影响,可能还是要等到更明确的落地场景和对应的商业模式出现,“否则市场再热闹也是没有用的。”
评论