
文|产业家 思杭
编辑|皮爷
2024年初,国内的大模型公司还未从上一波“GPT4”的焦虑当中缓过来,Sora就已经席卷而至。紧接着,所有互联网大厂几乎都“停下手头工作”,开始在新的领域做出一点成绩,从而尽快在市场上发声。
但在近期阿里蔡崇信的采访中,他说道,“中国AI技术可能要落后美国两年”。在这种不断追赶的焦虑背后,一个引人思索的问题是,国内大模型公司追赶的究竟是什么?
站在更为具体的赛道上来看这一问题,作为离Sora最近的赛道——音视频而言,这种焦虑也在不断放大。
从GPT3.5到GPT4.0,从Runway、Pika到Sora,当大模型的价值链不断升级,那些暂未爬到顶端的企业,还剩下多少‘生存空间’?
实际上,于音视频厂商而言,当“追逐技术”变为“追逐用户”,这种价值就变得更加具体、更加实际。从近两年音视频厂商的发力趋势可以看出,AI虽然是不可错过的大趋势,但企业要解决的难题是,如何将技术与用户连接在一起。让大模型发挥想象力的同时,更要解决用户的实际问题。
AI时代,不断进击的“音视频”
2022年,先是钉钉的一套“组合拳”,紧接着,音视频PaaS/SaaS厂商也纷纷跟进,不仅大手笔投入研发,还在AI方向补充弹药进行长远布局,自此,围绕音视频赛道的“混战”也正式打响。
音视频PaaS公司“拍乐云”被收购一事在2022年受到广泛关注,收购方正是阿里钉钉。一石激起千层浪,音视频赛道迅速成为焦点。更为炸裂的消息是,有着视频会议开创者Webex架构师、网易云信CTO和拍乐云创始人等多个显赫头衔的“赵加雨”,也携团队空降钉钉音视频事业部的一号位。
而跟随赵加雨的这伙人,个个都是音视频领域的得力干将。其中,李备是拍乐云音频专家,曾有5年WebEx音频专家工作经验;章琦,拍乐云首席科学家,8年WebEx音视频引擎架构师工作经验。
所有信号都指向了阿里布局音视频赛道的决心。实际上,阿里在音视频的布局更早就开始了。2021年11月,钉钉内部成立了独立的音视频事业部,该事业部成立的初衷便是聚焦在“研究音频技术及算法创新,以及探索下一代音视频会议形态”。
钉钉这一枪打响后,长年深耕在音视频赛道的腾讯云,以及其他PaaS和SaaS厂商,也纷纷从研发、解决方案、应用场景和AI方面增添自己的弹药库。
同样身为互联网厂商,音视频于腾讯而言,可以算是一种“与生俱来”的基因。到2022年,腾讯云的步伐早已到了在技术侧实现突破,以及在行业应用上更加细分的程度。
比如腾讯云将一种能够远程实时控制的音视频技术方案,应用在煤矿、港口场景里的无人驾驶卡车运营当中。而在此之前,在传统行业里实现远程的音视频连接和操作,无论是技术还是应用场景方面都远未达到成熟。
对于其他音视频PaaS/SaaS厂商而言,增加研发投入则是一种更为直接的方式。
在2022年,除了阿里钉钉的一套“组合拳”,音视频赛道里的另一个重磅消息是,音视频SaaS第一股“百家云”在纳斯达克敲钟上市。其2022上半年营收就达到了6860万美元,实现同比增长65.5%。在2023年其更是净利润达480万美元,实现扭亏为盈。而其研发费用更从2021财年的580万美元大幅增加到2022财年的1300万美元。
实际上,这种研发费用的骤增不仅仅是底层技术方面的发力,还有定制化和AI方面的投入。从财报中看,在2022财年的全年营收中还增加了一项“定制平台开发服务”,全年该业务的营收达到了1030万美元;而AI解决方案的收入也增加了760万美元。
而与SaaS厂商不同,音视频PaaS厂商的研发投入则更重。以声网为例,根据其2022年的财报显示,当年的全年总营收是1.61亿美元,而单是研发费用就达到了1.1亿美元。
那么,这1.1个亿的费用具体体现在哪些方面?
2023年,声网推出“凤鸣AI引擎”,将AI降噪、AI回声消除、空间音频等技术进行了集成;在视频方向,推出了超高清能力的超分、画质提升、感知编码、虚拟背景和AR特效等增强观看体验、临场感和互动表达能力的实时AI技术;也开发了语音转文字、内容审核等AI功能来增加信息提取、传递和保存的维度。
这是在AI时代、大模型时代下对智能化的一种响应。但罗马不是一天建成的。于音视频厂商而言,推出AI相关的技术或应用场景需要长期的投入。
无论是声网,还是保利威、百家云等其他音视频PaaS/SaaS厂商,对于AI的积累都要追溯到几年前。只是从外界声音来看,2023年是集中发力的一年。
以声网为例,在凤鸣AI引擎中集成的大部分技术都源于多年的积累。产业家向声网CTO钟声了解到,“空间音频”是凤鸣AI引擎中集成的技术。利用AI算法来模拟头部球面区域的立体声场,在更细微处,甚至能捕捉到人的喜怒哀乐,将这种三维信息提取出来再放到AR增强的场景。从技术处理的细节便可以感知到,它是一种“厚积薄发”的产物。
实际上2023年,大模型在国内“狂飙”的同时,音视频厂商更是不可能错过这波风口。技术的长期投入,这一年给音视频厂商的机会是在服务场景上更深化、更细致。
最为常见的便是AIGC解决方案的发布,这也是在市场层面能够迅速引发关注的方式。比如声网在去年发布RTE X AIGC 一站式产品能力解决方案;百家云发布全新AIGC产品“市场易”;腾讯云在音视频产品矩阵上的智能化升级;保利威发布AI智能教育解决方案;即构推出AI视频生成应用“即构数智人”等等。
而在无数的声音背后,大模型给音视频带来的实际价值是什么?
技术、落地场景和“大小模型”方案
“到了今天这个时代,客户不会关注噱头,而是更切实地关注提高了多少效率,降低了多少成本。”这是保利威全国售前总经理王建成近两年的感受。
技术不断进步的同时,服务场景也正在进一步深化。
抛开底层技术,在大模型时代,如果说真正能在效率上提升,以及成本上有所降低,用户一定会在操作体验层面有更强的感知。
那么,更为细致的应用场景,便是结合AI大模型,来解决曾经几乎“不可能”的事情。
以金融领域为例,其监管十分严格。一种常见的情况是,在直播过程中需要人为干预,进行监听。所以这种情况下,实时生成字幕对于大部分的金融客户就很难满足。
王建成告诉产业家,保利威的做法是结合金融客户的特殊需求和行业特点,做出一种专为金融行业打造的特殊模型。
这是一种将直播技术与业务结合的最佳例证。而在AI大模型时代,在技术高度不断刷新的当下,真正去解决用户的实际问题,对于音视频SaaS厂商,或许是一个更为务实的答案。
为什么说焦虑与现实有时并不成正比?
一方面,技术高度的不断刷新确实会带给人更大的焦虑,但另一方面,从现实的角度来讲,技术高度的不断刷新却并未真正下沉到产业,发挥真正的价值。
根据艾瑞咨询报告显示,在目前实时音视频领域,领跑场景依旧停留在C端,在实际生产过程中,产业数字化的价值微乎其微。
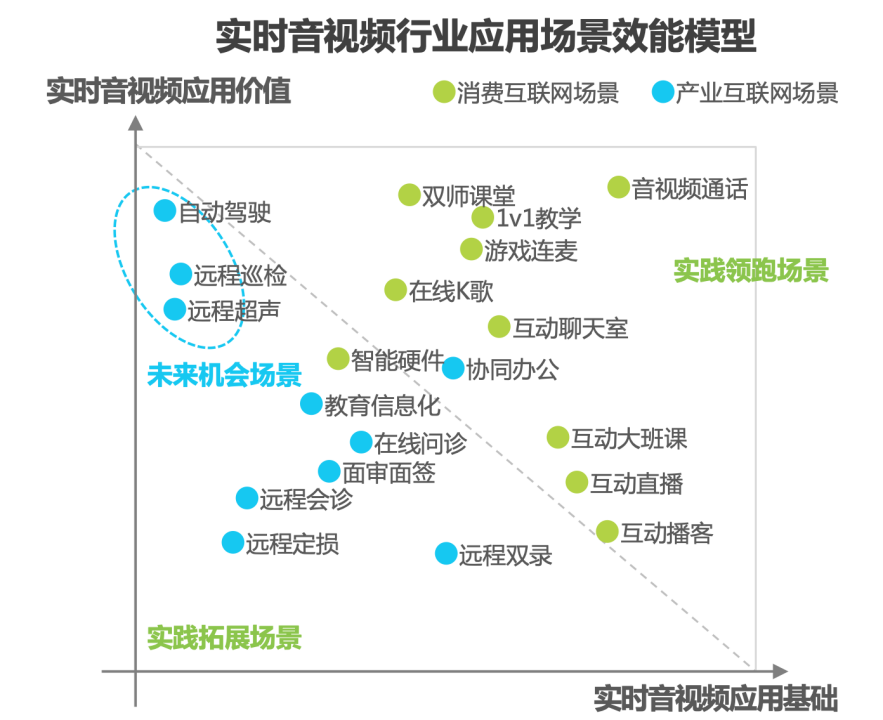
那么,从技术的角度出发,音视频技术现在究竟发展到什么程度了?
可以看到的是,腾讯云已经能够实现在煤矿、港口场景里,实时控制无人驾驶卡车运营。这是近两年较为新鲜的尝试。在这些场景同样有所布局的还有声网。除了更深入产业侧的工业领域 ,声网也在IoT行业、医疗健康行业持续发力。
而在大模型未到来之前,远程的音视频连接和操作,无论是技术还是应用场景方面都远未达到成熟。
站在技术的角度,更具体来讲,大模型给音视频领域带来的是更大的想象力。
2023年,阿里云智能高级算法专家刘国栋在深圳的一席演讲中提到了一种大模型与小模型结合的技术。
在大模型还未出现的时候,只有小模型。其实,大模型与小模型都有各自的局限。小模型的局限在于其泛化能力比较差。而泛化能力差,通俗来讲,就是小模型的理解和生成能力不好。但其优点在于,小模型、传统算法在算法开发、工程优化方面已相对比较成熟,小模型的训练资源占用少且训练速度快,部署容易,端侧落地性强。
而大模型出现后,这些问题都一一被解决了。而大模型的局限性在于,细粒度的问题还不能完美处理、容易出现幻觉现象、推理训练成本都比较高等。
因此,大小模型协同便是最好的解决方案。通过让大模型和小模型并联和相互引导的方式,来优化各自的问题。
而对于大模型与小模型的“协同”方面,声网也有自己的理解。对此,钟声向产业家解释道,“大模型的参数很大,需要巨量的数据包括高质量的数据来训练。一个符合常理的逻辑是,最领先的大模型,其推理能力较强,可以通过蒸馏等方法来训练小模型。大模型产生的结果,具备一定的质量,可以用来训练小模型。未来,大小模型应该以‘联合行动’的方式来共同完成任务,在算力、延时、隐私保护等方面实现一种更好的融合。”
一个更为遥远的畅想是,随着端上算力的增强,有着几十亿参数的大模型未来也有可能在端上运行。届时,在各个领域实现“实时音视频”则会成为现实。
更大的焦虑,更大的想象力
从GPT3.5到GPT4.0,从Runway、Pika到Sora,当大模型的价值链不断升级,那些暂时还未爬到顶端的企业,还剩下多少“生存空间”?
这是一个引人深思的发问。
近两年,科技界追逐技术的热情在不断高涨。大众对于AI的焦虑是更为遥远的“生存威胁”,而科技界对AI焦虑则是由所谓“参数”和“长文本”所“卷”起来的商业竞争。
如果聚焦到产业侧,聚焦到更实际的赛道,不断刷新的榜单,不断升级的参数、上下文长度,这些对于音视频厂商而言意味着什么?
在与钟声的对话中了解到,声网所追求的是实时性。而从目前来看,如果在云端的服务器上运行,最后在传输到端的设备上,很难实现“实时性”。所以声网的做法是是在端上进行计算。但客观来讲,端上运算的局限是算力不够。
对此,钟声发表了一种观点,虽然现在最前沿的技术都在追求Scaling Law(规模效应)支撑下的大模型,但对于声网而言,追求极致的小模型意义则要更大一些。首先保证低延时、低成本,直接让很小的AI算法在端上发力,通过极致、精准的算法来让音视频发挥最大的价值,低延时低成本可以为更多需要实时互动的客户和用户释放出或者创造出巨大的价值;这方面业界的关注度还不够,但终会成为焦点。声网在这方面则做了较为专注的研发投入。
站在更实际的角度,如果在云端运算,虽然在大算力的支持下运行大模型,最终可以得到较好的效果,但现实情况是,在大多数的消费侧场景,比如社交娱乐,系统响应延时过大,本身就不太像AGI,客户或用户也不可能花较高的费用来追求响应较慢的AGI效果。所以,在端上低延时低成本的运算更为有需求。
同时,钟声提出了一种畅想,在音视频领域,AGI最终会发展成端边云结合的方式,以平衡算力、延时、隐私和数据保护等几个AI发展的关键要素。
这是大模型赋予音视频厂商的想象力,而这种想象力也会应用到更现实的场景解决更实际的问题,比如医疗领域里会用到的远程救治,其实时性要求极高,延迟1s都可能威胁到生命。
那么,在当下这个拼技术刷榜单的大模型时代,音视频厂商要如何顺应AI时代?
实际上,近两年音视频的发展趋势已经从关注技术,走向关注更为实际的“降本增效”。以保利威为例,其SaaS订阅收入达到90%成绩背后,是结合具体的业务来解决实际用户的问题。
如果通过大模型所提升的音视频技术,不再止步于社交和娱乐,而是更为具体的生产环节,甚至是治病救人,那么也许实时音视频才会实现破圈,走向大众。
评论