

文|阿尔法工场
金沙江创投的朱啸虎曾说:美国打第一次海湾战争才花了120亿美金,现在互联网企业的融资可以和一场局部战争的花费进行对比,这是史无前例的。
现在,中国的AI大模型厂商,在五月的尾巴,打响了一场新的烧钱“海湾战争”。
这场以字节豆包0.0008元/千tokens点燃硝烟的价格战,在百度高调官宣ENIRE Speed和ENIRE Lite免费开放时,达到了新的巅峰。
01 格局决定行业命运
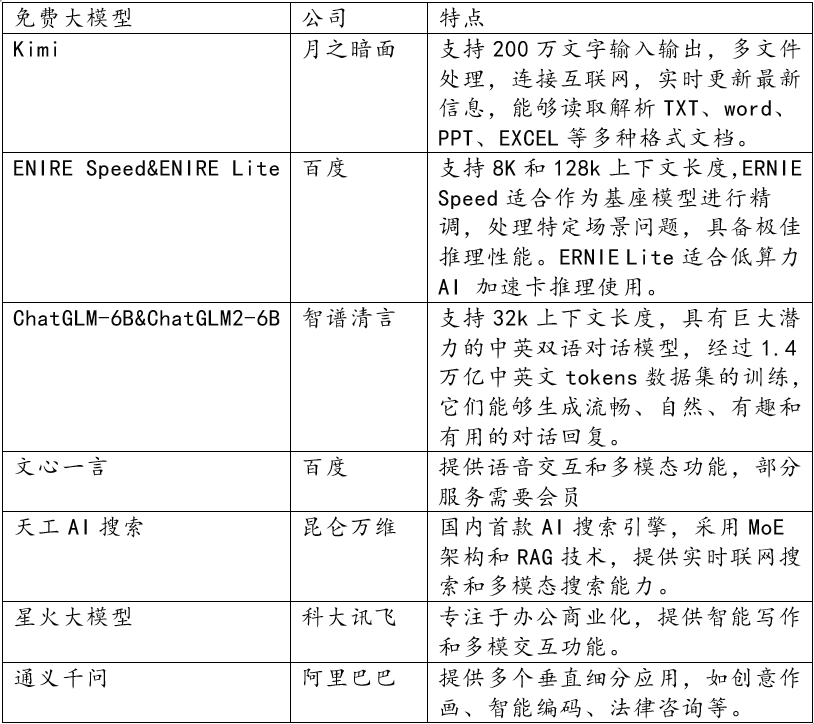
据不完全统计,目前国内已有超过10家大模型厂商宣布其主力模型免费或部分免费。

以百度为例,5月21日,其文心大模型的ENIRE Speed和ENIRE Lite两款主力模型全面免费开放,即刻生效。
效仿百度,腾讯云、讯飞星火也开走免费路线。
腾讯云在22日将混元-lite模型调整为全面免费,同时宣布万亿参数模型混元-pro的API输入价格从0.1元/千tokens降至0.03元/千tokens。
同天,科大讯飞也宣布讯飞星火API能力正式免费开放。
另外,阿里云的通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens直降到0.0005元/千tokens,直降97%,约为GPT-4价格的1/400。
这款模型最高支持1千万 tokens长文本输入,这意味着,一块钱就可以买200万tokens,相当于4本《西游记》。
而一周前,字节跳动火山引擎刚刚宣布推出筹备已久的豆包大家族模型,并以0.0008元/千tokens的价格给了业界一点小小的震撼。豆包通用模型pro-32k输入价格相比行业价格0.12元/千tokens,低了整整99.3%。
不过,字节豆包大模型断崖式价格下跌带给市场的震撼还未散去余温,百度、腾讯云、科大讯飞直接宣布免费,又将这场价格战拉到一个新的维度。
用趋于零的价格争取生态,这样的策略不止发生在国内。
早在一个月前,OpenAI就突然宣布ChatGPT-3.5全面免费。从GPT-4到GPT-4o,输入端价格从0.03美元/千tokens下降到0.005美元/千tokens,降幅为83%;输出端价格则从0.06美元/千tokens下降到0.015美元/千tokens,降幅为75%。
作为回应,OpenAI的头号对手谷歌则在其开发者大会上推出了0.0035美元/千tokens的Gemini Pro1.5,并将上下文长度拓展至200万tokens。
国内外价格战的打响无不证明着,要在愈发汹涌的人工智能市场上分得一杯羹,卷是宿命,也是必然。
02 鏖战,谁能破局
向C端免费意味着大模型走向了类似移动互联网产品一样,先培养用户深度习惯,提高用户黏性后再开启收费的路径。
这也预示着,大模型烧钱的军备竞赛开始渐入高潮。
弹药不足的,退局最快。
就C端而言,模型训练要钱,获客要钱。在token价格趋近于零的情况下,大模型C端的破局之道,就一个字,谁更有钱。
以Stability AI为例,没有人会想到,这个在2023年仍称霸文生图赛道榜首的佼佼者,会在一年之内快速陨落。
据The Information报道,Stability AI在2024年第一季度营收不到500万美元,亏损就超过3000万美元,拖欠云计算供应商等其他厂商将近1亿美元的账单,正在与潜在买家协商出售。
烧钱大战背后,像Stability AI般的隐退或将成为市场优胜劣汰的必然现象。
红杉资本报告显示,AI行业2023年营收仅30亿美元,但在英伟达芯片上就烧了500亿美元。芯片这一项支出就将近收入的17倍。微软旗下的GitHub Copilo由于运行成本过高一直处于亏损状态,每月甚至要倒贴每个用户20美元。
作为一个在前期极其烧钱的行业,除了谷歌、微软、阿里、字节等自身就资产雄厚的头部大厂,或许在开始盈利之前,只有少数像OpenAI一样能疯狂融资的初创公司才有可能存活。
截止2024年5月,OpenAI已完成由红杉资本等知名风投机构领投的10轮融资,累计融资额高达113亿美元。Claude公司Anthropic以77亿美元的累计筹集资金紧随其后。
国内大模型则以月之暗面、Minimax、智谱清言声势最旺。智谱在B4轮融资中融得25亿人民币,估值超过100亿人民币。月之暗面和Minimax则在最新一轮融资中分别融得10亿美元和6亿美元。
烧钱的本质,是取得垄断地位,从而在未来获取垄断收益。
但最终胜出的仍是那些通过持续创新提供核心价值,在商业化道路上找到可持续模式的企业。
比如AI界的领头羊OpenAI,自2022年11月ChatGPT上线之日起,一直以极高的产品优势占据C位。上线不到半年,open.ai网站的访问次数就超过了18亿次,领先于运营14年的微软浏览器bing.com。
就通用人工智能助手ChatGPT而言,其不同版本的训练参数一直以指数级飙升。GPT1的训练参数为1.17亿,GPT2为15亿,GPT3为1750亿,而GPT4已经达到了1.7万亿个训练参数。根据Scaling Law标度定律,大模型训练参数越大,其自然语言理解能力就越强,其输出内容也更能还原用户指令。相比于GPT3的幻觉和4k token的上下文长度。GPT4已经支持32k token的长文本输入,响应被拒的可能性降低了82%。
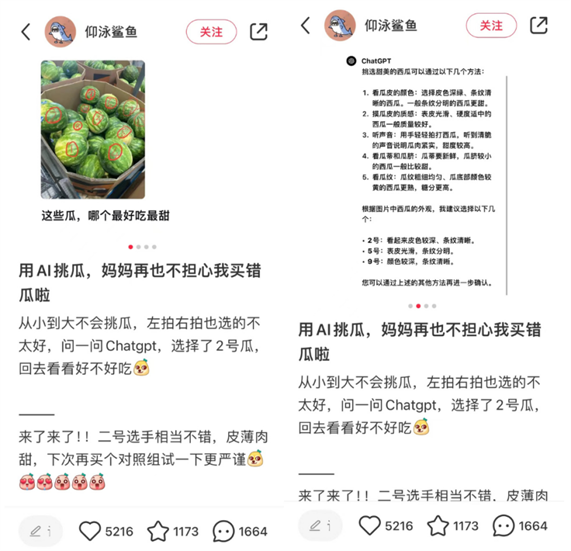
最新发布的GPT-4o更是被称为现实版的斯嘉丽,多模态的输入输出能力和类人化的情感表达让网友直呼,“她来了!”。不仅支持文、图、音频三种信息形态的输入,并且可以做超过50种语言的同声传译。甚而有网友给GPT-4o发了一张菜市场的西瓜图片,让GPT-4o帮着挑西瓜,据反馈,效果还不错。
据悉,或将于六月份发布的GPT5也来势汹汹,OpenAI首席执行官奥特曼透露,GPT-5类似于一个 “虚拟大脑”,将是一个支持文本、语音、图像、代码甚至视频的真正多模态模型。最关键的进步会围绕推理能力展开,在解决大模型幻觉和可靠性方面得到巨大提升。
03 识时务者,涌向B端
短期而言,打不起、或不想打“海湾战争”的识时务者,都涌向了B端。
随着模型升级,B端市场逐渐分化为两大阵营:一边是像谷歌、微软这样的科技巨头,它们将AI技术融入现有产品之中,以增强用户体验和提升产品效能。
腾讯的混元大模型就是这一策略的典型代表。除提供基础服务外,腾讯还通过社交平台和游戏业务,将AI技术与内容创作、个性化推荐等业务相结合,提供增值服务。腾讯董事会主席兼首席执行官马化腾表示,受益于 AI 技术显著提升广告定向能力,四季度,腾讯广告收入 297.94 亿元,同比增长 21%。
另一种,则是那些专注于为其他企业提供定制化AI服务的公司。这些公司希望找到技术与行业需求的结合之道,能够为B端客户量身打造解决方案。
不过,从互联网公司发展的历程来看,AI大模型公司里最终摘下王冠的依然是面向C端的公司。
评论