
文 | 唐辰同学
网文作者拒成番茄小说AI训练“花肥” 。
近段时间,不少网文作者在社交媒体发文控诉,番茄小说在签约协议中,增加了“AI训练补充协议”,要求作者同意把作品“授权”给平台的AI,用于内容开发。
背刺平台作者
根据此次补充协议内容,作者完成签署后,其作者全部/部分内容及相关信息,都将用于平台AI人工智能模型训练,或者其他新技术研发应用场景。如若签订,作者后续“将优先参与平台AI新功能内测”。
也就是说,番茄小说的作者,被迫同意补充协议后,其小说作品便被平台拿去“投喂”给大模型训练。但他们并不能拿到更多收益,最多是获得一个十分鸡肋的新功能内测资格。
实际上,早在2023年,就有作者在番茄小说的签约协议中,发现涉及AI训练的条款。当时并没有被作者和业界广泛关注。这次拿“作者小说训练AI”事件之所以发酵,主要还是番茄小说的吃相过于难看,更多作者选择停更、断更和在社交平台发声抗议,来和平台博弈、维权,要求解除AI协议。

一方面,番茄小说合同中关于作品“投喂”AI的条款,隐蔽且“霸道”。不少作者是通过网络帖子才注意到合同中的“霸王条款”。从作者发帖的内容可以看到,番茄小说的补充协议里,并没有明说平台不会把作品拿去训练AI,但也没有放弃寻求作者的同意,甚至在引导作者,让渡自己的权益。
另外一方面,面对“投喂”AI引发的争议,番茄小说在相关论坛及其今日头条官方账号进行回应,称“官方没有发布过任何纯AI写作的作品,也不会违背作者个人意愿使用AI写作能力。如作者对协议有异议,可以尽快协助解除相关AI条款约定。”
但平台作者们认为,番茄小说回应所选择的论坛和今日头条账号,并不被所有人知晓。这个姿态,只是对外界的一个交代,不是直接触达作者的信息渠道。因为番茄小说平日给作者发信息的正规渠道都是站内信。
“这就是希望我们尽可能少关注到这件事的新闻或者帖子,尽量减少去主动解约作者人数。”有作者提到。此外,还有多位作者表示此回应避重就轻、玩文字游戏:“没发布过‘纯AI’写作的作品,意味着可能发布过大部分内容由AI生成的作品,比如真人搭框架,AI填内容。”
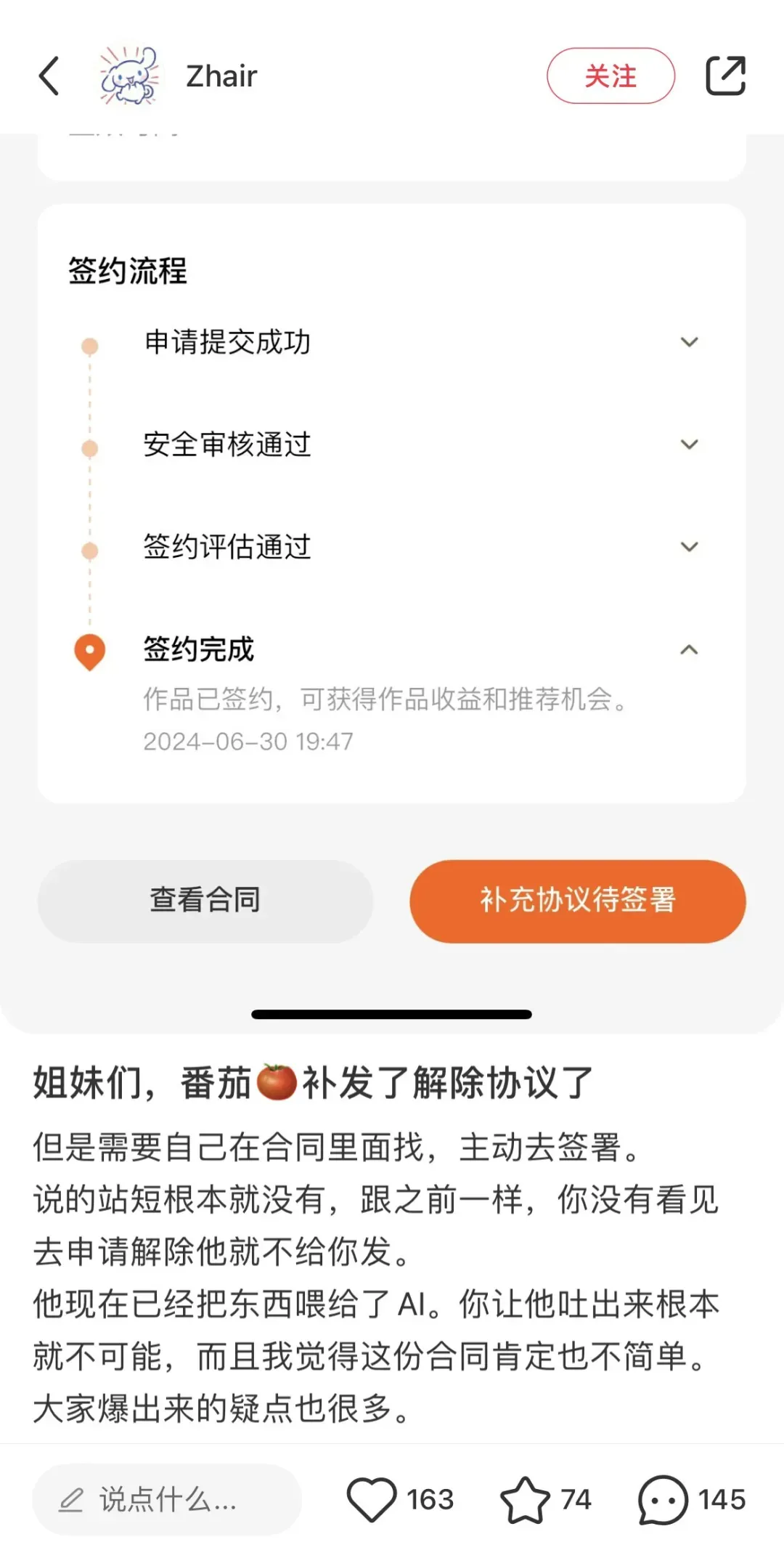
随着抵制和反对声音的持续放大,番茄小说不得不上线合同条款解除功能,支持解除“AI训练补充协议”。
即便如此,解约也并没有那么轻松。有作者发现,解约的操作入口很深。还有作者提到,他的解约申请16日已经提交,但至今还在待处理状态。还有上百位博主发帖表示,与番茄小说解约后被限流,且没有收到违反有关规则的通知。不少作者更担心被平台方起诉,泄露合同内容。一旦败诉,赔偿金也会是一笔不小的费用。
在人工智能技术发展,AI创作大趋势下,番茄小说推出AI辅助工具无可厚非,一定程度上也能提高网文作者的写作效率。但番茄小说把AI补充训练协议明确写在作者合同中,没有考虑作者的心情,强行把作者的劳动成果“投喂”给AI,不仅涉嫌侵犯内容版权,更是对他们的一种背刺。
因为对于很多网文作者来说,这是他们的谋生之路。如今在不知情的情况下,随时可能被AI作者替代,何尝不是第二个面对无人驾驶的网约车司机?毕竟,原创作者坚持日更千字甚至万字就极为难得,而AI作者分分钟就能“创作”出一本小说。
经济观察网还提到,明确把AI条款写进合同的,只有番茄小说一个平台。阅文集团、掌阅、七猫小说、中文在线等网文平台的作者和工作人员,他们均称没有见过类似AI条款。换句话说,直接宣布将语料“投喂”给大模型的平台, 目前仅有番茄小说一家。
拿了你的东西,还不明确告知目的是什么。这也就能理解,番茄小说为何在这轮风波中,被作者推到对立面,奋起落锤反抗。有作者便表示准备和小伙伴离开,“越了解AI写作,越觉得番茄小说不把作者当人。”
番茄小说的底气
虽然放在全球范围看,AI创作引发的争论和抗议早已有之。比如,2023年7月,出于对AI发展的忌惮,有着近16万成员的好莱坞三大工会之一的美国演员工会(SAG-AFTRA)也出现过罢工现象,罢工人员曾在十数家制片公司外举行抗议活动。
再比如,2023年底,《纽约时报》就将微软和OpenAI告上法庭,称被告未经许可使用数百万篇版权文章训练AI模型,开发有竞争属性的产品,赚取了丰厚的利润,但严重威胁到了新闻从业者的生计,造成数十亿美元的损失。在此之后,陆续有媒体加入到反抗的队列。截至今年6月,至少已有12家新闻媒体机构对OpenAI和微软提起了侵权诉讼。
与之对比,番茄小说AI协议事件,可以定义为是国内首例内容创作者联合反对AI写作的案例,值得网文行业以及AI从业者的反思。晋江文学城总裁刘旭东就表示,他并不鼓励AI创作。人类作者参与这种行为是饮鸩止渴。迟早有一天,平台会用自己训练的AI虚拟作者代替人类作者。“如果这一天注定要到来,我希望来得晚一些”。
在他看来,网文平台看重AI,大部分是为了降本增效。特别是在免费网文平台,有一些靠发钱吸引来的、对作品质量要求不高的读者,他们需要“量大管饱”、品质不必太高的内容,而AI写作的内容恰好能满足这种需求。所以鼓励AI创作就成了一些平台的导向。
如其所说,网文平台布局AI已久。在番茄小说的AI条款发酵之前,包括字节跳动系、腾讯系、知乎在内的多家公司,都在投入以中文写作为核心能力的大模型。
比如去年7月,阅文发布了国内网络文学行业首个大模型“阅文妙笔”,并基于这一大模型推出应用产品“作家助手妙笔版”;知乎在2022年,作为领投方,参与了AI创业公司面壁智能的天使轮融资。此后,2023年11月,和面壁智能共同发布了“知海图AI”中文大模型;“七猫”平台宣布基于跟百度的“文心一言”合作,为作者提供了“AI助理”等相关辅助写作功能,可以提供历史文化信息、为角色命名、生成场景描写等。
同时,撇除刘旭东观点里的“竞品思维”,有一点是客观的。番茄小说成立不过5年,便超越阅文(起点)、晋江等老牌网文平台,一跃成为用户最多的免费小说平台,靠的就是“免费、量大、管饱”的策略。
这放在字节跳动“App工厂”体系内,其增长策略和今日头条、抖音如出一辙:用户看书不花钱,还能通过不断地刷时长,获得积分、金币甚至返现奖励,番茄小说凭借用户规模获得广告收益。这个模式也被业界评价为,“用户没有花钱买商品,因为用户就是被卖掉的商品”。
调研机构QuestMobile数据显示,番茄小说位列2023年12月国内数字阅读行业MAU(月活跃用户数)规模首位,MAU为1.92亿,同比增长35.8%。另据晚点LatePost曾披露,2023年,番茄小说的收入已经超过 100 亿。“挟流量以令作者”,这或许是番茄小说的底气。
大模型的中文语料焦虑
目前来看,AI替代的问题是一个全球性也是时代性的争论话题。由番茄小说AI训练协议推高的,关于平台用作者内容投喂AI是否侵权以及如何界定、AI是否会革了网文作者的“命”、AI对内容创作影响有多大等问题的探讨,短期内难以有一个共识的答案。但可以确定的是,当下没有谁,包括内容创作者群体,愿意被动的成为AI训练的“花肥”,自然会站出来说“不”。
番茄小说“顶风作案”还引发一个关键问题:字节大模型的语料不够“吃”了,正面临着语料短缺的焦虑。今年5月,字节跳动发布豆包大模型,官方宣称,豆包大模型正成为国内使用量最大、应用场景最丰富的大模型之一,目前日均处理1200亿Tokens文本,生成3000万张图片。番茄小说是其接入的50余个业务之一。
番茄小说基于豆包大模型的AI功能箱扩充——番茄小说上线了AI扩写、AI改写、自定义描写、AI续写、AI起名、卡文锦囊、AI助手七大功能——自然需要更多的文字作品来喂养,也需要更多数据来支撑AI写作,平台作者便成为所需“花肥”。
事实上,在番茄小说AI训练补充协议上线之前,豆包的语料库中,已经疑似被投喂了全网的免费、付费文学作品。蓝鲸新闻报道,有番茄小说作者提到,在豆包搜索个人在起点上架的小说内容时,也能搜索到有关内容。该作者怀疑在番茄小说的实名注册信息被泄露,各大平台以自己不同网名来写作的内容都已经被抓取。

还有作者爆料,WPS疑似将自己的审签内容喂给了豆包,称“我才发表到35章,豆包章纲直接给我扩到90章。我的细纲里中后期剧情还没发表出去,豆包都出章纲了,那些剧情还和我大纲的剧情一模一样,只有顺序有点乱。”
对此,豆包也发布声明称,传言完全不实。豆包上部分书目信息,来源于公开信息,豆包也会给出相关网站信息;豆包与WPS在AI训练层面并未开展任何形式的合作,也没有使用任何用户未公开的私人数据进行训练。
抖音也进一步明确,作者问询相关书目信息,豆包是基于公开搜索结果呈现作品及概述,不存在盗用信息行为。番茄小说对于已经签署补充协议、或签约条款中包含AI条款的作者,已开放相关通道,将协助作者尽快解除相关AI条款约定。
但这并没有打消作者和业界的疑虑。信奉实用主义的字节,此前就有过类似的“骚操作”。今年5月,豆包被爆出将AI自问自答的内容生成静态网页,利用搜索引擎提高排名曝光,从而吸引流量。比如,当有人问AI搜索软件Perplexity一个无厘头的问题:“林黛玉的性格和鲁智深的性格有什么相似之处”时,答案其中一个信息源,竟然是豆包和用户的聊天记录。

要知道,数据是支撑大模型发展的核心要素之一,语料即是大模型训练所需要的数据,是巧妇下厨的“米”。同时,语料的质量会显著影响大模型的性能。数据质量低,输出的结果必然会是“垃圾内容多”。
唐辰注意到,阿里研究院在最近发布的《大模型训练数据白皮书》中提出,互联网上中文语料和英文语料占比存在显著差异:在全球网站中,英文占比高达59.8%,而中文仅占 1.3%。
商汤科技大装置事业群高级总监张行程表示,中文高质量语料相对缺乏是国内外大模型面临的共同问题。中文语料库不仅规模较小,且其电子化和网络化程度明显不足。此外,受版权、隐私等限制,许多优质中文语料库也无法公开获取。
去年,阅文在推出“阅文妙笔”时,就被问询其素材来源,但相关负责人不予置评。从这点上看,字节跳动正面临中文语料短缺的问题,也是国内所有大模型厂商的共同困境。
而这,也是主张“大力出奇迹”的字节跳动,为实现大模型训练的可靠性甚至领跑行业,才跑偏了,不顾一切的将网文作者、作品作为“花肥”,投喂给AI的根本原因。
参考资料:
中国企业家杂志,《3个月上架222本书,番茄小说疑似“进化”出AI作者》
科技日报,《大模型发展提速 中文语料够“吃”吗》
我是唐辰同学,关注互联网科技及商业故事。原创内容,未经许可,谢绝转载。
评论