
文|硅兔赛跑 Xuushan
编辑|蔓蔓周
今天,OpenAI藏了许久的“Strawberry”模型终于发布了!
连OpenAI的CEO Sam Altman都在社交平台X上提到自己等不及了,并直言:“这是 o1,我们迄今为止最强大的模型系列。”

OpenAI o1是一个全新的系列模型,和GPT系列模型相比有两大不同:第一,该系列模型是在思考之后回答用户问题,输出高质量的内容,而非迅速回应无效回答。第二,o1系列更擅长推理,推理能力大幅提升,尤其擅长准确生成和调试复杂代码。目前OpenAI并未全面对用户开放o1系列模型,仅开放了o1-preview和o1-mini版本供用户使用。同时,OpenAI还发布了o1-mini模型,该模型推理速度更快,且成本更低,o1-mini比o1-preview便宜80%,更擅长编码等推理性内容,但不擅长语言、通用知识类内容。OpenAI最后提到发布o1系列并不意味放弃GPT系列模型,他们将继续开发和发布GPT系列模型。让人意外的是,OpenAI此次还披露了o1系列研发的参与者。该项目由Jakub Pachocki、Jerry Tworek(overall)、Liam Fedus、Lukasz Kaiser、Mark Chen、Szymon Sidor、Wojciech Zaremba领导,核心贡献者有51位。

o1模型发布后,一些曾参与到o1模型内测的用户或者刚刚体验了o1模型的用户给出了更多的看法。以OpenAI的研发人员为代表的工程师多数都在夸赞AI思考链的强大。但同时,硅谷里也有人发出了不同的声音,认为o1很多测试并没有得到科学界认证。比如说,纽约大学教授、美国知名AI学者Gary Marcus认为o1法学考试能力有夸大嫌疑,其真实能力有待检验。

让大模型学会思考?o1将思考过程透明化
我们看到o1系列模型与GPT系列模型明显不同之处,在于o1有“思考链”了。这里面有两个值得注意的地方。一是,OpenAI尝试让利用大规模强化学习算法“教会”模型有效思考,像人类一样。OpenAI主要通过强化学习,让o1学会思考其思路链并改进其思考路线。o1逐渐学会识别不同的思考链模式,并且能够纠正思考路线错误。同时,它还学会将棘手步骤分解为更简单步骤。此外,它还能学会在一个思考模式不起作用时,尝试不同思考链解决。“这个过程极大地提高了模型的推理能力。”OpenAI说道。二是,OpenAI发现随着强化学习的增加(训练时间计算)和思考时间的增加(测试时间计算),o1的性能会持续提高。

这时候,新的问题又摆在了OpenAI面前——AI的思考过程到底要不要显示出来?OpenAI认为如果展示AI的思考链能够帮助人类读懂AI的思考,并且避免AI“背叛”人类,更好地监视AI的安全性。同时,OpenAI也提到希望模型能够自由地以未改变的形式表达其思想,而非受到“政策合规性以及用户偏好”的训练。从硅兔君目前测试的o1-mini模型来看,OpenAI最终还是为o1模型选择了透明化其思考过程。这一下,不少网友都跑去提出许多奇奇怪怪的问题,就为了想看看AI在想什么。目前,o1模型还在早期测试阶段,其o1-preview模型也仅支持文字输入,输入方式相比GPT-4更单一。不过,OpenAI提到未来希望添加浏览、文件和图片上传等功能。现在,ChatGPT Plus和Team用户将能够在ChatGPT中的模型选择器中直接选择访问o1模型。每周能够给o1-preview发生30条消息,给o1-mini发送50条消息。符合API等级5的开发人员现在可以开始使用API中的两种模型进行产品原型设计,速率限制为20RPM。但目前o1模型的API不包括函数调用、流式传输、对系统消息的支持和其他功能。ChatGPT Enterprise和Edu用户将从下周开始使用这两种模型。
OpenAI o1模型:数理化强者,推理能力翻倍提升
o1在几个ML基准测试中,都表现出当下最先进的水平。尤其是在启用视觉感知功能后,o1在MMMU上的得分为78.2%,成为第一个与人类专家相媲美的模型。OpenAI测试结果显示,OpenAI o1在竞争性编程问题(Codeforces)中排名第 89 位,在美国数学奥林匹克 (AIME) 预选赛中跻身美国前500名学生之列,并在物理、生物和化学问题 (GPQA) 基准测试中超越人类博士级水平。在绝大多数的推理能力较强的任务中,o1的表现明显优于GPT-4o。

o1在广泛基准测试中都比GPT-4o有所改进,该项测试共54至57个测试方向,图中显示了7个子类别,可以看到o1全方面强于GPT-4o 。

同时,OpenAI还评估了AIME的数学表现,AIME 是一项旨在挑战美国最聪明的高中数学学生的考试。在2024年的AIME考试中,GPT-4o平均仅解决了12% (1.8/15) 的问题。o1拿下了13.9 的分数使其跻身全国前500名学生之列,并超过了美国数学奥林匹克的分数线。OpenAI还在GPQA测试上对o1进行了评估。这是一个很难的考试,主要测试化学、物理和生物学方面的专业知识。为了将模型与人类进行比较,OpenAI招募了具有博士学位的专家来回答 GPQA测试的问题。OpenAI发现o1的表现超过了那些人类专家,成为第一个在这个基准上做到这一点的模型。这些结果并不意味着o1在各方面都比博士更有能力——只是意味着该模型在解决一些博士需要解决的问题方面更熟练。OpenAI还模拟了Codeforces主办的竞争性编程竞赛,以展示该模型的编码技能。这个评估与竞赛规则非常接近,允许提交10份作品。GPT-4o的Elo评级为(3 分)(808 分),位于人类竞争对手的第11个百分位。该模型远远超过了 GPT-4o 和 o1——它的 Elo评级为1807分,表现优于93%的竞争对手。

除了考试和学术基准之外,OpenAI还选择了一些用户测试了对o1-preview和 GPT-4o的偏好。在这次评估中,人类训练师看到了对o1-preview和GPT-4o 提示的匿名回答,并投票选出他们更喜欢的回答。在数据分析、编码和数学等推理能力较强的类别中,o1-preview的受欢迎程度远远高于GPT-4o。然而,o1-preview在某些自然语言任务上并不受欢迎,这表明它并不适合所有场景。

o1还显著提升了AI推理的最新水平。OpenAI期望这些新的推理能力将提高模型与人类价值观和原则相结合的能力。OpenAI相信o1及其后续产品将在科学、编码、数学和相关领域解锁更多的AI新应用。

OpenAI o1-mini:小巧、便宜、高效,但不擅长语言
OpenAI o1-mini是OpenAI推出一款经济高效的推理模型。该模型主要为一些需要推理而无需通用世界知识的应用程序服务。简单来说,OpenAI o1-mini模型小巧、便宜、高效,但是对通用知识了解不多。
o1-mini在预训练期间针对STEM推理进行了优化。在使用与o1相同的高计算强化学习 (RL) 管道进行训练后,o1-mini在许多有用的推理任务上实现了相当不错的性能,同时成本效率显著提高。
比如说,在AI和推理基准测试中,o1-mini的表现优于o1-preview 和o1。
在高中AIME数学竞赛中,o1-mini(70.0%)与o1(74.4%)相当,同时价格便宜得多,且成绩优于o1-preview(44.6%)。o1-mini的得分(约 11/15 个问题)大约位列美国高中生前 500 名。

在Codeforces竞赛网站上,o1-mini的Elo得分为1650,与o1(1673)不相上下,且高于o1-preview(1258)。该模型的Elo得分处于Codeforces平台上竞争程序员中第86个百分位左右。o1-mini在 HumanEval编码基准和高中级网络安全夺旗挑战赛 (CTF) 中也表现出色。

响应速度方面,OpenAI比较了GPT-4o、o1-mini和o1-preview对一个单词推理问题的回答。虽然GPT-4o回答不正确,但o1-mini和o1-preview都回答正确,而且o1-mini得出答案的速度快了大约3-5倍。
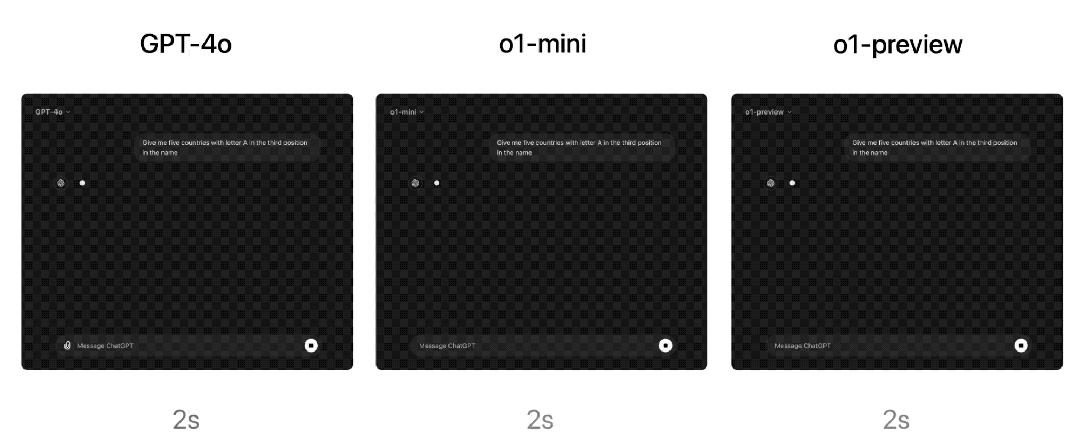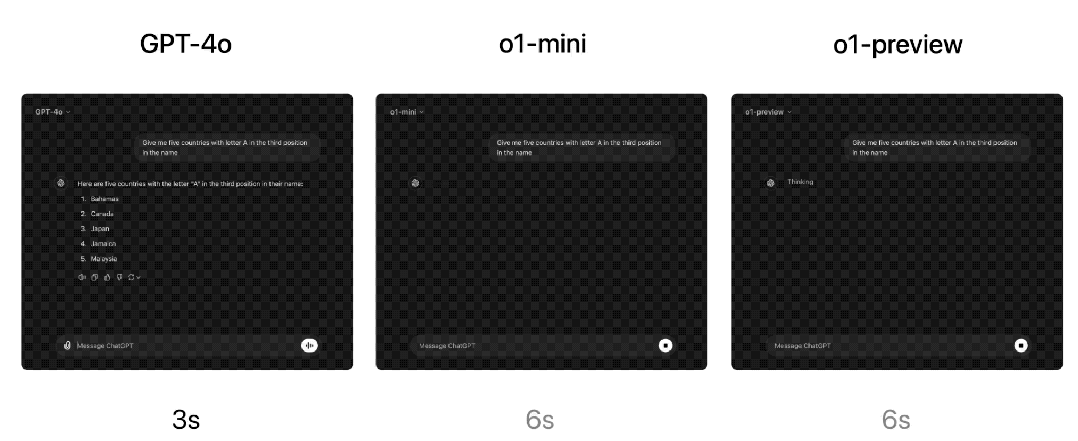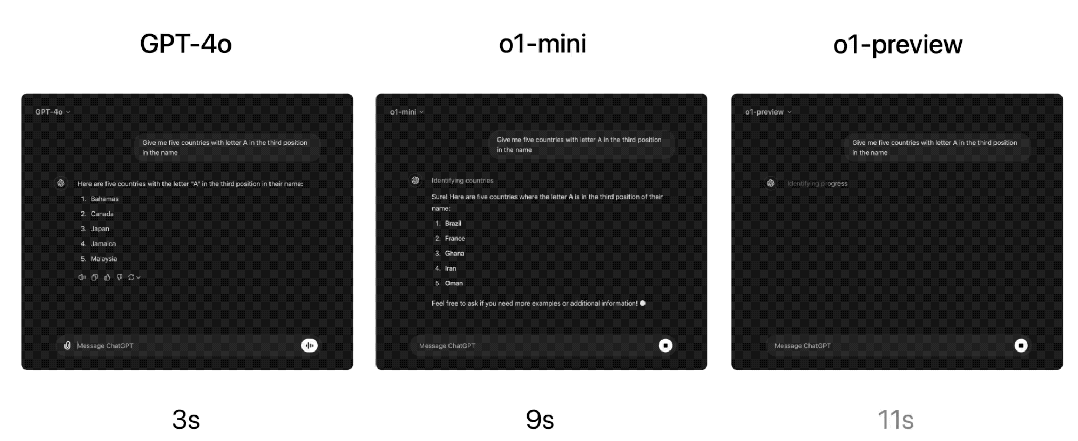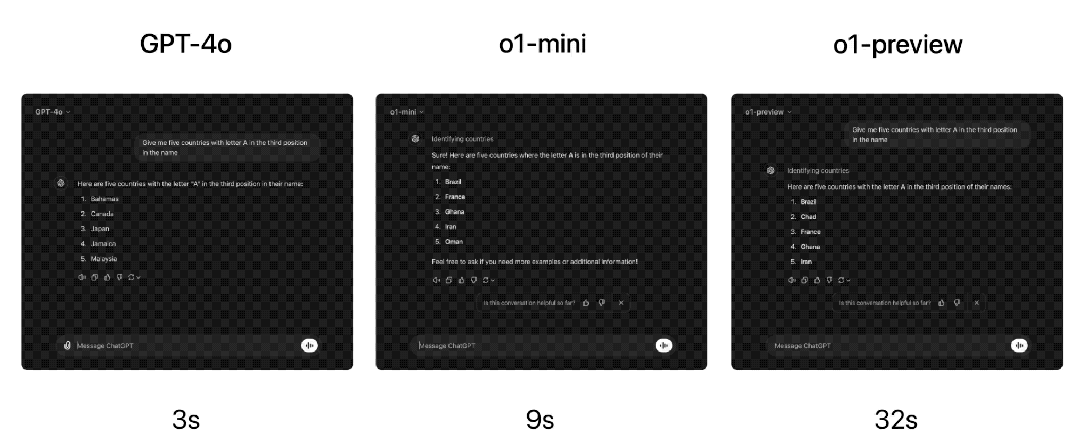
但语言明显是o1-mini模型的弱项。OpenAI让人类评分员用同一开放性自然语言提问o1-mini和GPT-4o,测试问题以及测试方法与他们测试o1-preview与GPT-4o的方法相同。与o1-preview类似,在推理能力较强的领域,o1-mini比GPT-4o更受欢迎,但在以语言为中心的领域,o1-mini 并不比 GPT-4o更受欢迎。

整体看来, o1-mini专注于STEM推理能力,其关于日期、传记和生活常识等非STEM主题的事实知识可与GPT-4o mini等小型 LLM 相媲美,但与GPT-4o仍有一定差距。
OpenAI介绍道:“我们将在未来版本中改进这些限制,并尝试将模型扩展到 STEM之外的其他模态和专业。”
评论