
文|半导体产业纵横
据Trendforce 报道,内存制造商三星、SK 海力士和美光希望堆叠更多 DRAM 芯片。随着第五代堆叠 DRAM 高带宽内存 (HBM5) 的推出,至少有 20 个内存层。
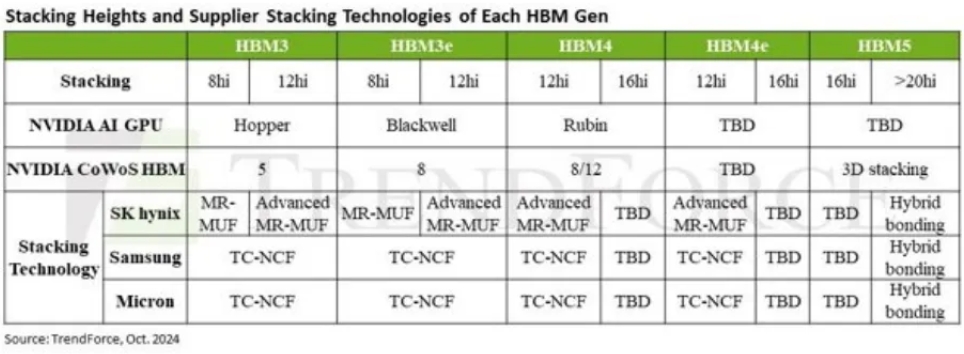
目前的 HBM3e 设备使用 8 个 24 千兆位芯片,总容量为 24 千兆字节。12 倍堆叠的 HBM3e 模块(称为 12-Hi)已发布,容量为 36 千兆字节。每个芯片具有相同容量的 20-Hi 变体的容量为 60 千兆字节,但后者可能会同时增加,以实现更高的存储量。
不过,该产品还需要几年时间才能上市。Trendforce 估计 Nvidia 希望在下一代产品中使用 HBM5。届时它将不再位于 GPU 旁边并通过硅中介层连接,而是直接安装在 GPU 上。
Blackwell(B100 和 B200)仍使用 HBM3e。Nvidia已宣布将在 2026 年推出具有八个 HBM4 堆栈的 Rubin;具有 12 个堆栈的改进版本 Rubin Ultra 将于 2027 年问世。具有 HBM4e 的 Rubin 继任者将于 2028 年问世,而具有 HBM5 的继任者最早将于 2029 年问世。
混合键合取代焊球
在此之前,制造商必须解决生产问题。到目前为止,他们一直在 DRAM 层之间使用焊球,即所谓的微凸块。三星和美光依靠热压缩非导电膜 (TC-NCF) 来实现稳定:他们将一层薄膜贴在单个芯片上,薄膜在高温和高压下熔化,从而将各层粘合在一起。
SK Hynix 依靠所谓的大规模回流成型底部填充 (MR-MUF) 来改善散热。制造商对此的描述如下:“大规模回流是一种通过熔化堆叠芯片之间的凸块将芯片粘合在一起的技术。模塑底部填充用保护材料填充堆叠芯片之间的间隙,以提高耐用性和散热性。MR-MUF 结合使用回流和成型工艺,将半导体芯片连接到电路上,并用液态环氧模塑化合物 (EMC) 填充芯片和凸块间隙之间的空间。”
但随着容量和时钟频率的不断提高,组件产生的热量也随之增加。此外,制造商必须节省空间才能将 20 个内存层压入一个组件中。
据称,该解决方案是混合键合,AMD 此前已在其带有堆叠缓存的 Ryzen X3D 处理器中使用过该技术。然后,将所有 DRAM 层磨平,以便它们彼此粘合在一起而没有焊点(凸块)。为了实现这一点,制造商必须转换其封装系统。三星大概也希望将这项技术用于 SSD 的 NAND 闪存。
如果制造商有意提前积累该技术经验,16 层堆叠的 HBM4 和 HBM4e 堆叠(16-Hi)也可能采用混合键合。然而,这显然在技术上还不是必要的。
高堆叠内存的 GPU 在制造成本上必然会有显著的提升。首先,研发新的散热技术、信号处理技术和封装工艺都需要投入大量的资金。与此同时,该技术还存在诸多挑战。
在一个 GPU 上堆叠 20 个 DRAM 芯片,散热将成为首要面临的巨大挑战。大量芯片在高速运行时会产生可观的热量,如果不能有效地进行散热处理,将导致芯片性能下降甚至损坏。英伟达将不得不投入大量研发资源来开发新的散热技术。例如,可能会探索更高效的散热材料,从传统的铜基散热片转向石墨烯等具有超高热导率的新型材料。同时,液冷技术也可能会得到进一步发展和优化,设计出更加精细且适配这种高芯片密度的液冷系统,确保每个 DRAM 芯片都能在适宜的温度下工作。
在如此高密度的芯片堆叠下,信号完整性也是一个亟待解决的问题。众多芯片之间的信号传输路径变得更加复杂,电磁干扰、信号延迟等问题容易出现。英伟达需要在芯片设计和电路布局上进行创新。比如,采用更先进的布线技术,增加信号屏蔽层来减少电磁干扰。同时,在芯片之间可能会引入新的信号补偿和校准机制,实时监测和调整信号的传输状态,确保从一个 DRAM 芯片到 GPU 核心的数据传输准确无误,维持整个系统的高性能运行。
此外,制造工艺将面临更高的要求。要实现 20 个 DRAM 芯片的稳定堆叠,对芯片的封装工艺提出了近乎苛刻的条件。目前的封装技术可能无法满足这种高复杂度的要求,英伟达需要与芯片制造厂商紧密合作,共同研发新的封装工艺。
在这个过程中,如何保证高良品率是关键。因为随着制造复杂度的提升,不良品出现的概率也会增加。这可能需要在生产流程中引入更精密的检测设备和方法,从芯片原材料的筛选到每一道生产工序都进行严格的质量把控,以确保最终产品能够达到预期的性能和可靠性标准。
评论