

文 | 表外表里 张冉冉 薛程鹏
编辑 | 曹宾玲 付晓玲
在特斯拉智驾团队工作区,工程师们安装了一台85英寸的大型电视,上面实时显示着汽车在无干预状态下行驶的里程数,时刻提醒大家“努力奋斗”。
他们还在旁边摆了一面锣,每次克服了干预问题,就敲锣庆祝。
让马斯克团队如此全力以赴的,正是后来轰动一时的FSD v12自动驾驶系统。它采用one model端对端架构,可以让智能驾驶无限接近真人,也被称为汽车界的“ChatGPT时刻”。
然而,这项特斯拉燃烧激情、奋战15个月才完成的划时代成就,被理想短短6个月就“完美copy”了——10月下旬,理想在所有MAX车型上全量推送了“端到端+VLM”系统。
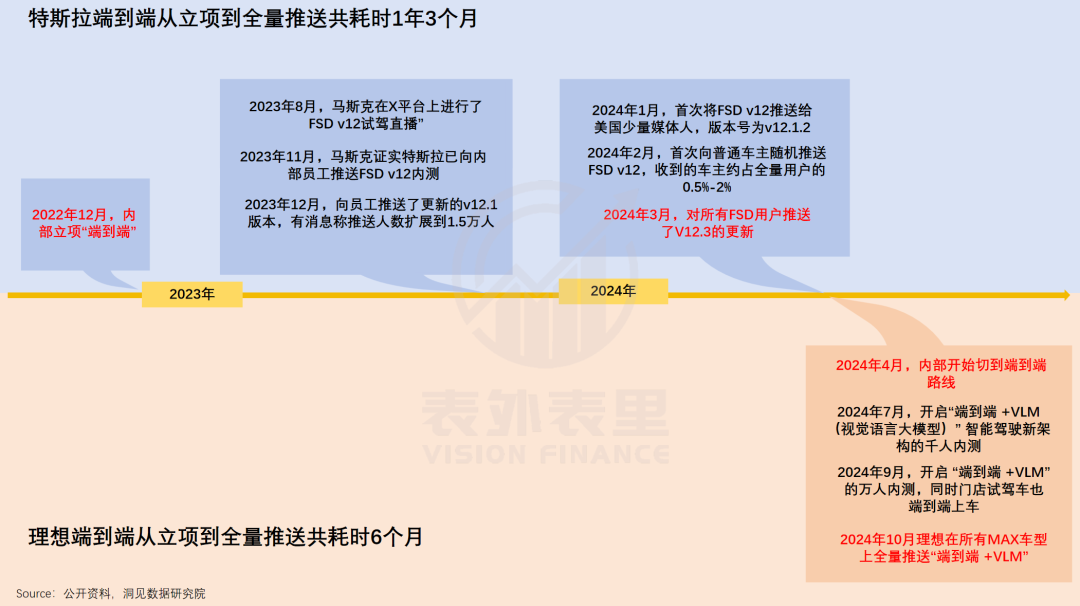
不仅提前交卷,成绩还压了优等生小鹏、华为们一头:理想直接对标特斯拉,而智驾“遥遥领先”的小鹏、华为,切的是“折中”的分段式端到端。


然而,友商们并不以为然。何小鹏在采访里含沙射影:“楼要一层一层搭,想跳跃式发展,大部分楼层会出问题。”
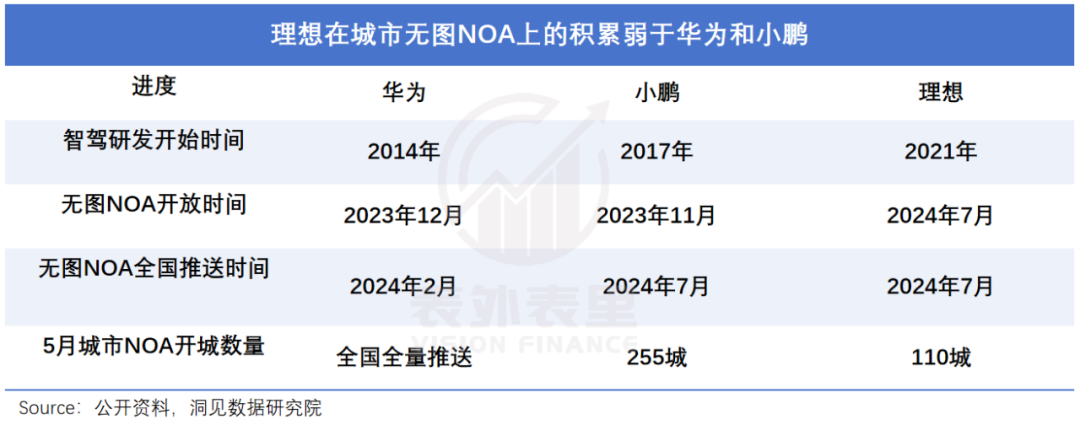
话锋直指理想在端到端上的积累太少——算力、数据、模型等一系列要做的事情,小鹏们在研发无图NOA等系统时就熟练掌握了,理想不仅研发时间更晚,开城数量还差了一大截。
华为余承东更是早在特斯拉FSD v12出来时,就“贴脸开大”过:one model端到端上限很高,但下限也很低,ChatGPT等AI工具存在幻觉,一次错误就有可能车毁人亡。
这些质疑没错,在汽车消费上怎么强调安全都不为过,但矛盾的是,企业发展往往又需要经常“踩油门”变道超车。
一、现在轰油门,对理想最好?
事实上,“端到端”玩家们不止路线分化,智驾团队建设也大相径庭。
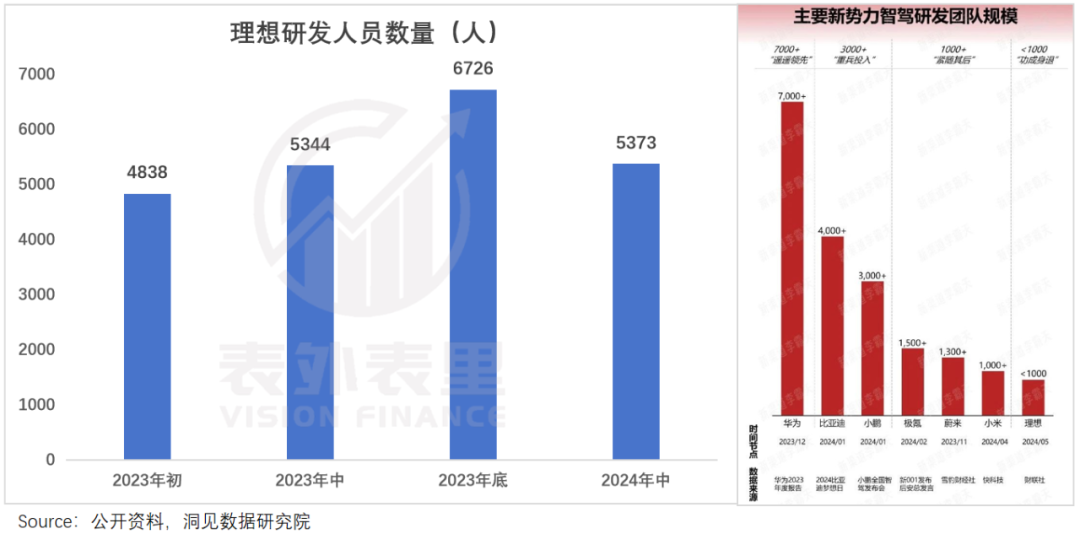
理想这边大玩“过山车”:去年卷无图NOA开城,刚把智驾人数扩至近千人,今年切入one model端到端后,又“一朝回到解放前”——截止到年中,缩减了40%。
而智驾团队规模分别是理想3倍、7倍的小鹏、华为,却似乎并没有减员的意思,如小鹏管理层表示:“小鹏没有去裁人,因为AI在发展早期仍然需要人类老师。”
这也不难理解,毕竟one model端到端路线纯数据驱动,用马斯克的话说就是“一张神经网络打包一切”,几乎把过去模块化时代积累的经验都扔进了垃圾桶。
相比之下,华为们采取的分段式“端到端”技术方案,仍是一个人工和智能“共处”的混搭系统。
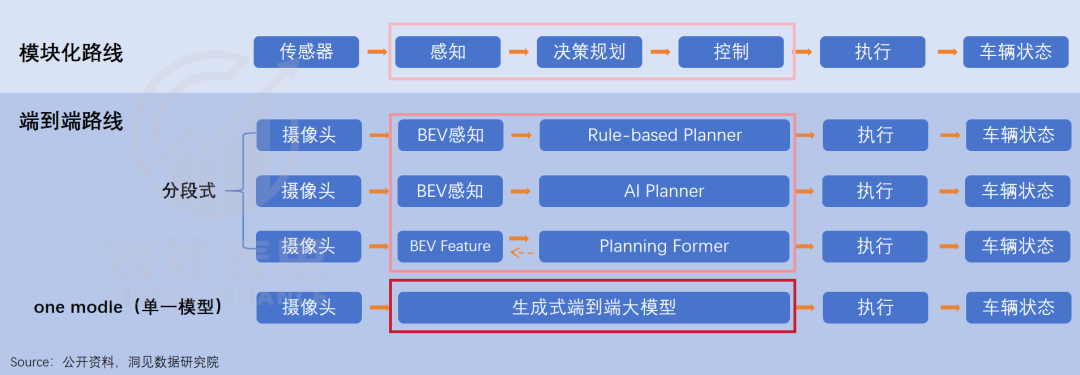
在模块化时期,对驾驶任务的决策、执行,需要基于规则——工程师将“红灯停、绿灯行”“见到行人要让行”等司机驾驶的各种行为习惯,变成代码规则,智驾系统按这些规则匹配实际情况作出反应。
而道路行驶环境复杂,疑难场景源源不断,工程师需要夜以继日地写if else。比如,小鹏去年在北京测试NPG时,类似“树叶把红绿灯遮挡”等问题层出不穷,专项成立了几十个,耗时2个多月后才勉强开放。
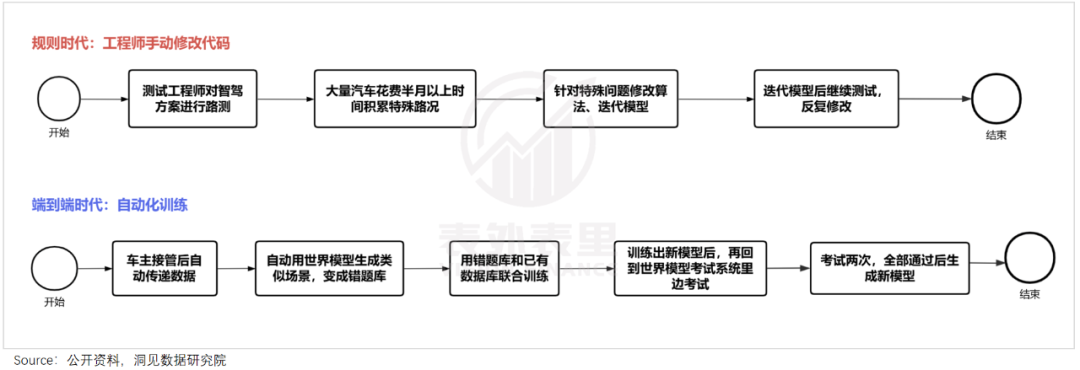
这让彼时的智驾竞争,演变成了往规控模块堆人力的军备竞赛。可以看到,小鹏、华为“遥遥领先”的开城数量,正是建立在分别超过3000+人、7000+人的智驾团队规模上。
相比之下,理想则被其智驾一号位“盖章”:人力资源不足拖累了开城进度。
如此来看,小鹏们如果直切one model端到端,意味着此前积累的规则数量大部分都将作废,人员与组织架构调整,也牵一发而动全身。
而“光脚”的理想就不一样了,用其管理层的话说:“虽然有技术切换的成本,有组织管理上的代价,但理想能负担得起。”
更何况,当下上马one model端对端,最符合理想的商业利益诉求。
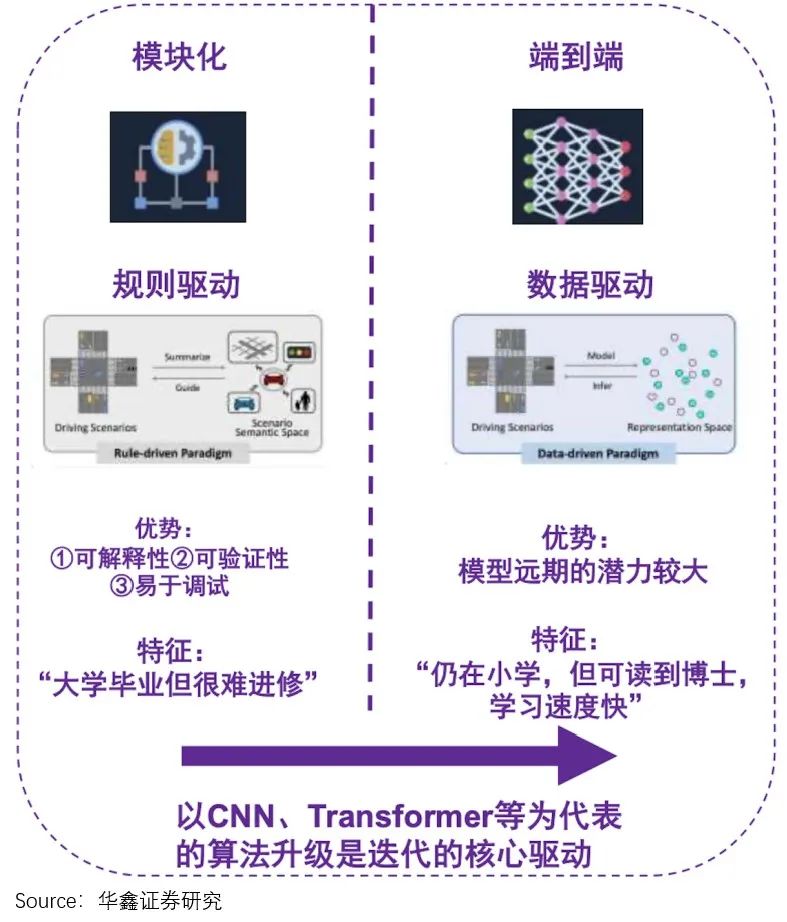
如果说,模块化设计理念下的车辆,就好像是在驾校学车的、没有自主意识,教练说做什么他就做什么(编写代码规则)。
那端到端设计理念下的车辆,就是一个拥有自主意识并且会主动模仿学习的新手司机,只要给它观看成百上千万的优秀老司机怎么开车的视频后,它会慢慢变成真正的老司机。
这意味着,越早、越多地掌握这些“优秀司机开车视频”用来训练,在这轮竞争中胜出的机会越大。
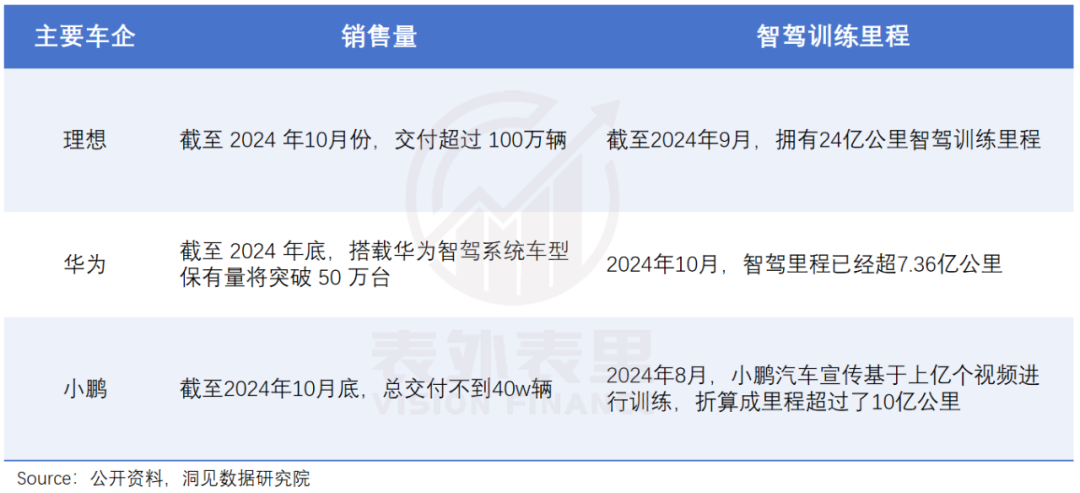
而理想早在2019年交付第一辆车开始,就学习特斯拉部署了影子模式——在车上放置摄像头,并回传数据。
与之相比,同期的友商们或多或少都有点“拉跨”。比如,技术、销量都领先的特斯拉,囿于“国内数据合规性”限制,FSD一直无法引进中国,数据积累尚属空窗期。
销量巨无霸的比亚迪,智驾业务一直“外包”给百度、大疆等供应商,既不允许这些供应商用量产车型上获得的数据,自己也没有回传数据的能力。

同样有数据回传能力的华为和小鹏,销量又不尽人意:小鹏的总交付不到40万辆;搭载华为智驾系统的车型,预计2024年底会突破50万台,都不及理想累计销量的一半。
但这种情况,显然不会一直持续下去。
最新消息,特斯拉计划于2025Q1在中国和欧洲推出FSD。比亚迪去年也秀了一组数据,“目前已形成一支300多辆车的研发车队,积累150PB以上的数据”,暗示自己也在建设数据回传能力。
这意味着,理想如果现在不上马one model端到端,很可能“错过这个村,就没了这个店。”
当然,竞对们追上来,还需要过程,且数据训练也不只是堆量,还对数据质量有要求——端到端的各个功能需要同时进行训练,训练数据越一致越好。
而一谈起这个,理想的嘴角比AK还难压,“外界说理想L系列是在套娃,但是这让我们有个最大的优势,传感器布局和传感器型号完全一致,理想L系列的数据可以完全复用。”
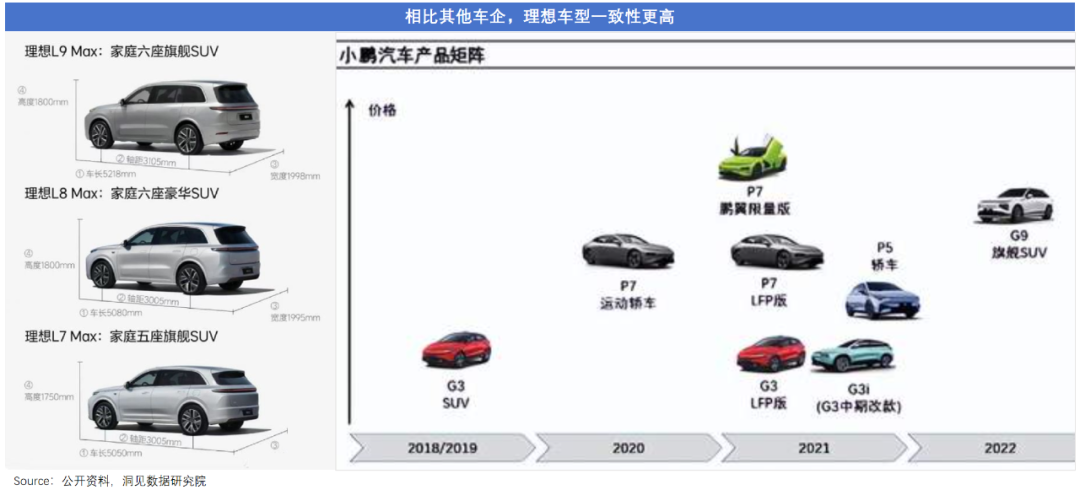
除了规模、质量,数据的多样性也会影响大模型的学习效果。理想智驾团队去美国试驾特斯拉FSD V12时就发现了:在西海岸硅谷和东海岸纽约,FSD性能差距大到像2个系统。
这时,以前总是被嘲“技术落后”“多此一举”的增程式路线,又帮了理想一把:相比纯电车“只能在几百公里打转”,理想汽车的足迹深入新疆、西藏等地。
于是,在“鞭子”加“胡萝卜”的双重刺激下,理想开启了狂奔。
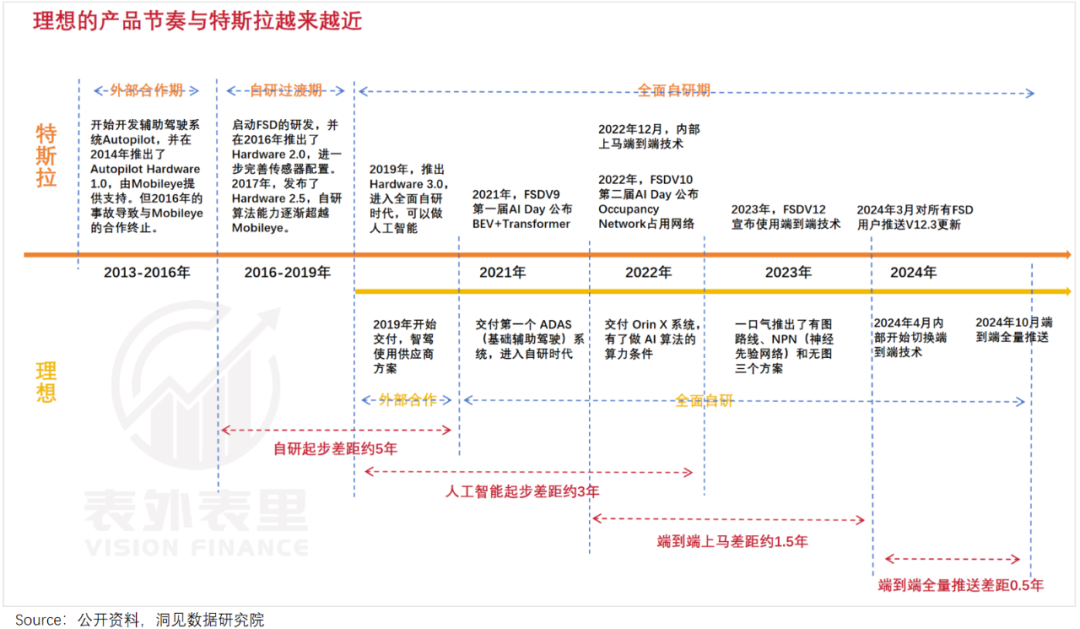
二、1年多时间,补了特斯拉3年的课
去年10月开始研发无图,3个月后从研发转向量产交付,次月就交付了初版……短短几个月,理想就完成了友商一两年的工作。
如此疯狂,就是为了“给端到端争取时间”。
端到端需要的算力、数据、模型等一系列事情,无图智驾方案基本都会涉及,正如特斯拉能快速落地FSD v12,背后是其早早就举起了纯视觉方案的大旗,并逐渐在规划和控制模块也加入神经网络。

有了特斯拉在前面探路,还有自己数据优势傍身,理想跑得更快更猛:无图方案从测试到全量推送,只花了5个月时间,到了端到端,这一时间被缩短至3个月。
横向对比来看,特斯拉从无图到端到端全量推送,大约经历了3年,而理想仅仅花了1年多时间就补完了作业。
“2024年要成为智驾绝对头部。”这是李想立下的flag,如今理想正朝着这个目标步步逼近。
但在其风头日盛时,何小鹏却兜头泼来一瓢冷水:“如果有人说他有一个大模型,可以用来降维做智能驾驶,或者他说有很多车,所以有很多数据,千万不要相信,绝对是胡扯。”
这并非何小鹏的一家之言,马斯克也有类似说法:大多数的数据最终都会被丢掉,重要的是那些占比不到1%的稀有视频,比如一些奇怪或者车流量异常大的十字路口的数据。
甚至理想自己也是如此——其建立了一套“老司机”的评价标准,只有不到3%的车主通过了考核,连智驾负责人都没达标。
也就是说,能够投喂给大模型的优质数据其实凤毛麟角。而理想积累的数据虽然“拳打”问界、“脚踢”小鹏,相比特斯拉却仍有较大差距:
从销量来看,截至2023年底,特斯拉在北美累计交付约250万辆,而理想到今年10月在国内累计交付100万辆;
智驾里程积累上,特斯拉在全量推送FSD V12前,累计智驾里程超过70亿英里,而理想的这一数据是25亿公里,刚过特斯拉的1/5。
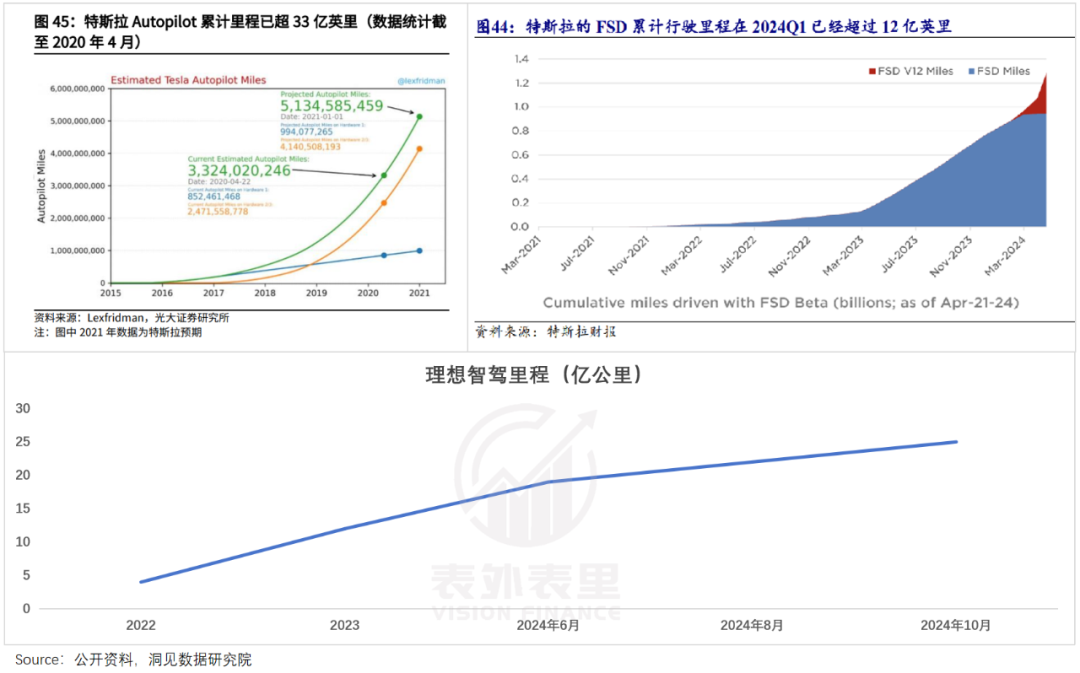
这使得理想训练的优质数据量也远少于特斯拉:据《马斯克传》,FSD V12在2023年初切入端到端时就分析了1000万个视频画面,而理想在全量推送前训练的视频仅为400万个。
乍一看,400万个也不少,但当车子真正开到路上,问题就凸显出来了。
如下图,理想智驾明显学会了“早八老司机”的蛇形走位,不仅丝滑加塞,甚至还弹窗提醒车主帮忙加塞。

实际上,即使是有着惊艳拟人化表现的FSD,也会在马斯克的直播间里,当着1000万观众的面企图闯红灯。
这是因为one model端到端下,数据传进来和轨迹输出去之间,只有一个生成式大模型,它并不知道红绿灯是什么,只有在学习了海量司机驾驶视频之后,才知道红灯停、绿灯行。
而在大模型“学习”的过程中,难免会犯各种各样的错误,正如上述余承东所说的,“one model下限很低。”
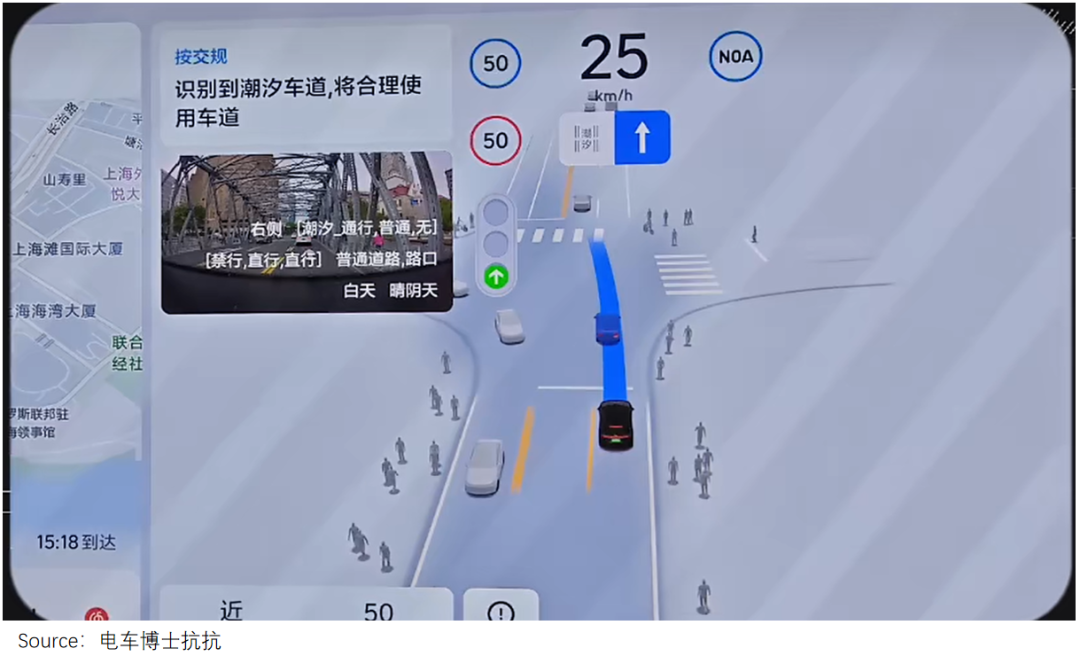
理想目前的解题思路是在one model端到端模型之外,并联一个视觉语言模型(VLM)托底。
例如,遇到坑洼不平的路面或潮汐车道时,后者会提醒前者降速、合理选择车道;遇到危险时,两个系统能一起帮司机踩刹车。
在此之外,理想还祭出了一个简单粗暴的方法——让更多人用智驾,积累更多数据。
其智驾负责人曾透露端到端的落地流程:先内部验证范式,到产品验收环节,从鸟蛋到早鸟到千人内测,我们让用户一起去做产品的测试和迭代。
在内测版本,理想就直接加入了高难度的高速场景,相比之下,特斯拉首次全量推送的FSD V12也仅适用于城市街道,高速路段在V12.5才推送。
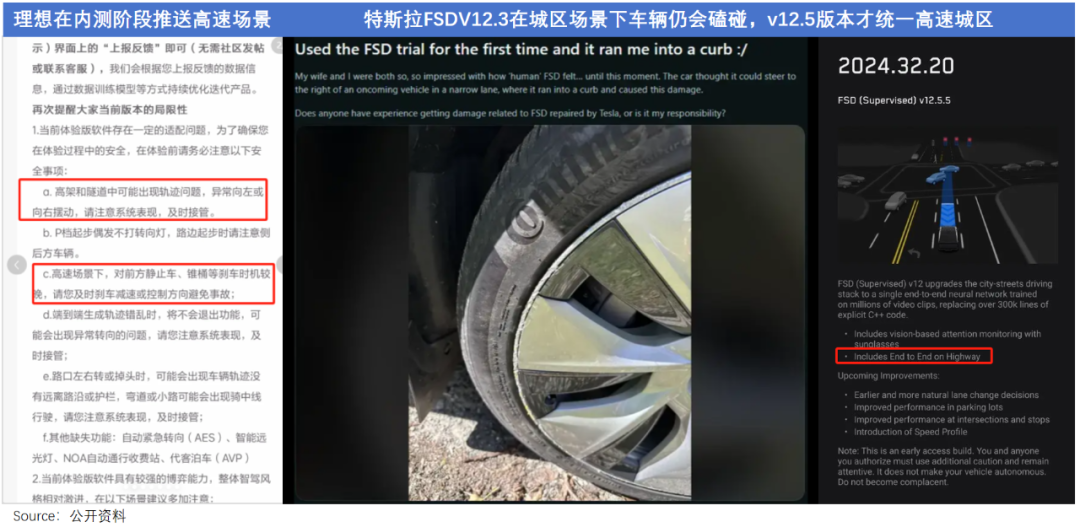
从这一维度上看,理想多少有些着急了。但“急”不止发生在理想身上,切入端到端路线的玩家,没有哪个敢放慢步伐。
“特斯拉今年将在综合训练和推理AI上投入约 100 亿美元。”这是马斯克分享的数据,他还表示,“任何没有在这个水平上投入且资金效率不高的公司,都无法竞争。”
这意味着,车企需要有足够的销量去获取利润。而在智驾水平显著影响购车选择的当下,越早落地技术,越能抢夺用户心智,促进销量增长,特别是在智驾接受度较高的中国。
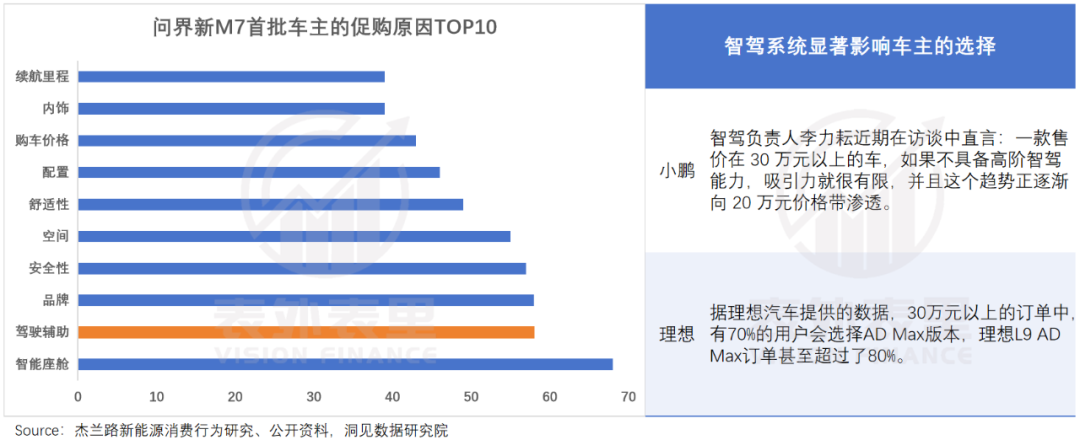
基于此,理想选择了继续轰油门。几个月前,李想公开表示要推出更高算力的自动驾驶体系,让用户享受“L3级自动驾驶体验”。
小结
据传,理想智驾部门很喜欢以希腊神话为“关键战役”命名,而这一次的端到端项目,被叫作“达摩克里斯计划”。
按照理想的说法,“这个项目有挑战、很危险,如果做不好,达摩克里斯之剑会掉下来。”
很显然,理想比任何人都清楚,从奶爸车到智驾黑马的“一跃”,代价不仅是招兵买马、训练模型的开销,还有坐在驾驶位上的百万车主们。
接下来的路,理想也得系好安全带才行。
评论