

文 | 光锥智能 魏琳华
编辑 | 王一粟
ChatGPT诞生的第二年,OpenAI和国内的一众企业正在试着“抛弃”它。
在Scaling Law被质疑能力“见顶”的情况下,今年9月,OpenAI带着以全新系列命名的模型o1一经发布,“会思考的大模型”再度成为焦点。
“我认为这次 o1 模型发布最重要的信息是,AI 发展不仅没有放缓,而且我们对未来几年已经胜券在握。”对于o1的发布,奥特曼信心满满。
国内大模型厂商对o1的学习、超越任务也提上了日程。两个多月之后,国内大模型公司纷纷效仿,相继推出了各具特色的o1类深度思考模型。
无论是kimi的k0 math、Deepseek的DeepSeek-R1-Lite,还是昆仑万维推出的“天工大模型4.0”o1版,都在强调着国内大模型对大模型逻辑思考能力的重视。

国产大模型集体跟进o1
在OpenAI没有披露o1具体技术的情况下,只用了2个月左右的时间,国内大模型公司就跟上了前沿方向的能力:
11月16日,月之暗面在发布会上公开了新模型k0 math,通过采用强化学习和思维链推理技术,大模型开始试图模拟人类的思考和反思过程,从而增强其数学推理能力。顾名思义,它在研究数学难题方面的能力可谓“遥遥领先”。
4天后,Deepseek的DeepSeek-R1-Lite正式上线。和OpenAI的o1相比,R1毫无保留地放出了大模型思考的完整过程。官方表示,R1的思维链长度可达数万字。从官方测试结果来看,在AIME(美国数学竞赛)、部分编程比赛的测试上,R1的表现超越了o1-Preview。Deepseek还直接在官网放出了测试版,允许用户每天体验50次对话。
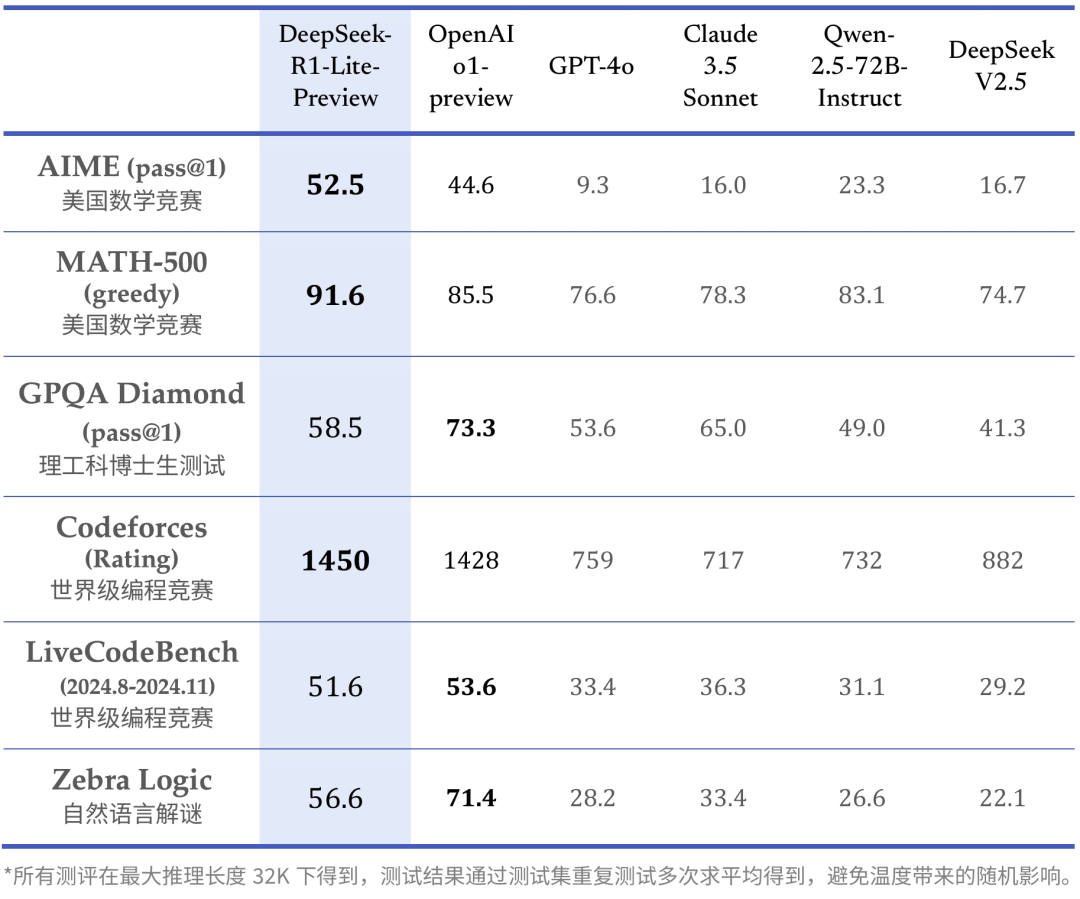
就在上周三(11月27日),昆仑万维也放出了具有复杂思考推理能力的天工大模型4.0 o1版(Skywork o1),宣布它是国内首款实现中文逻辑推理的模型。它也一次性给出了三种模型版本:开源的Skywork O1 Open、优化中文支持能力的Skywork O1 Lite,以及完整展现模型思考过程的Skywork O1 Preview。
扎堆涌现的国产“o1”大模型们,不想只做简单的“模型复刻”。
从模型测试跑出的指标分数来看,上述模型在数学、代码等能力上的表现均逼近、甚至超过了o1:
以k0 math为例,在中考、高考、考研以及包含入门竞赛题的MATH等4个数学基准测试中,k0-math的成绩超过了OpenAI的o1-mini和o1-preview模型。
不过,在一些难度更大的竞赛测试题能力表现上,比如难度更大的竞赛级别的数学题库OMNI-MATH和AIME基准测试中,ko math表现还没办法赶上o1-mini。
能够做出难度高的数学题,类o1的大模型们开始学会了“慢思考”。
通过在模型中引入思维链(CoT),大模型将复杂问题拆解为多个小问题,开始模拟人类逐步推理的过程。这是在无人参与的情况下,由大模型独立完成推理。强化学习使大模型能够自行尝试多种不同的解题方法并根据反馈调整策略,学习和反思的任务的任务,都交给了大模型。
和一般模型相比,此类产品在一些往常无法解决的问题上也能够正确回答,比如“草莓strawberry”一共有几个r、“9.11和9.9相比哪个大”等问题,交给o1,它能在一番思考后给出正确的答案。

比如,把“Responsibility中有几个字母i?”的问题抛给Deepseek R1,在深度思考模式中,我们能够看到大模型的思考过程:它先把单次拆解成一个个字母,再逐步比较每个字母是什么,最终给出了正确的结果。在测试中,R1的思考速度也够快,用不到两秒的时间给出了答案。

专精还是空中楼阁,o1的硬币两面
批量制造的“慢思考”大模型们,在强化学习和逻辑链的加成下,模型能力的表现突飞猛进。
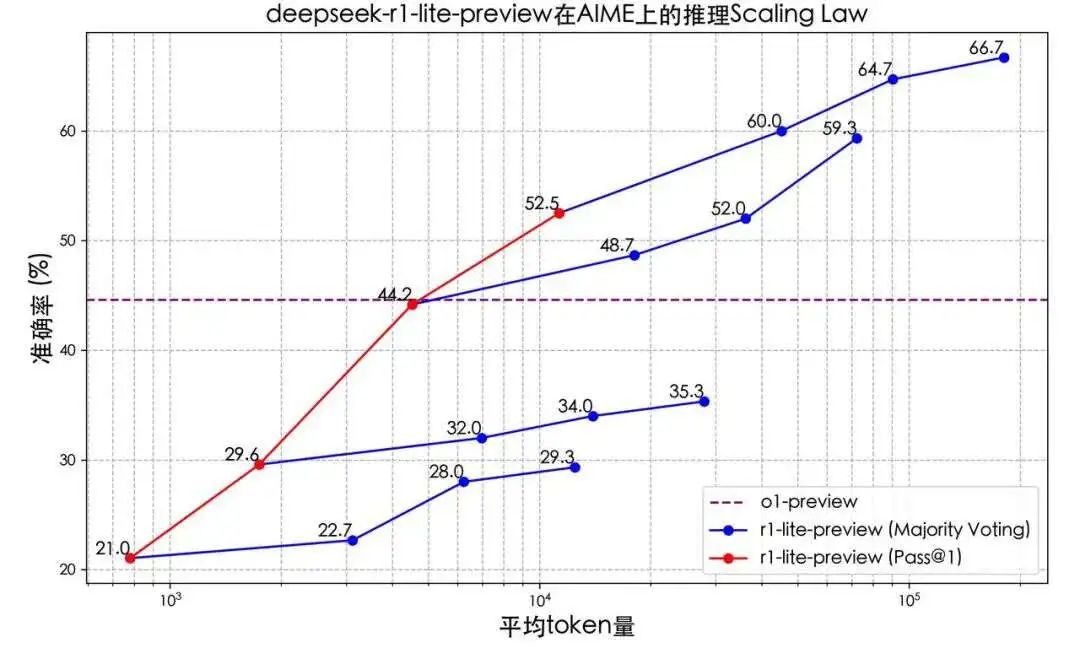
在Deepseek公布的测试效果中,可以看到,DeepSeek-R1-Lite的推理时间和准确率成正比关系,即推理时长越长,跑出的效果就越好。和过往没有“慢思考”能力的模型相比,R1的表现远优于前者。
在上述能力的加成下,大模型的自我反思、学习能力提升明显。比如,面对陷阱时,模型可以通过思维链模式自行避开问题。
发布自研模型时,昆仑万维给了大模型一个“陷阱”题目。让它回答存在中文读音“陷阱”的问题——“请将qíng rén yǎn lǐ chū xī shī转换为中文”。在第一次思考得出结论时,大模型主动发现了“西诗”是不对的说法,通过推理找到了准确的翻译结果。

一方面,慢思考模型大幅提升了大模型在一些特定学科上的表现,解决难题的能力进一步提升;另一方面,大量耗费tokens的方式却未必能换来用户需要的回报,这也是常被用户诟病的一点。
在某些情况下,增加模型思维链的长度可以提高效率,因为模型能够更深入地理解和解决问题。
然而,这并不意味着它在所有情况下都是最优解。
比如,思考“1+1>2”这类常识性问题,显然从效率和成本上来看,更适合用以往大模型的能力。这就需要大模型学会对问题难度自行进行判别,从而决定是否采用深度思考模式回答对应问题。
而在科学研究或复杂项目规划中,增加思维链的长度可能是有益的。在这些情况下,深入理解各个变量及其相互作用,对于制定有效的策略和预测未来的结果至关重要。
此外,从特定场景下的强化学习应用转向通用模型,在训练算力和成本的平衡上或许还有一定难度。
从国内发布的模型来看,目前“慢思考”类大模型开发的基座模型参数不大。比如Deepseek和昆仑万维给出的模型版本,都建立在规模量更小的模型上:Skywork o1 Open基于Llama 3.1 8B的开源模型,Deepseek也强调目前使用的是一个较小的基座模型,还无法完全释放长思维链的潜力。
“一个大概率会确定的事情是,在训练 RL 的阶段,我们所需要的算力可能并不比预训练要少,这可能是一个非共识。”谈及o1时,阶跃星辰CEO姜大昕曾经提到过这个问题。
未来的大模型不应该花费大量精力在简单的问题上,要想跑出真正能够释放思维链能力的模型,还需要一定时间。
突破AGI二阶段,国内加速探索产品落地
大厂们为什么将o1视为了下一个必备项?
在OpenAI和智谱给出的“通往AGI五阶段”的定义中,两家公司均将多模态和大语言模型能力归在L1阶段,也就是最为基础的能力配备。
而o1的出现,则标志着大模型能力突破到了L2阶段。自此,大模型开始真正拥有了逻辑思维能力,在无人力干预的情况下进行规划、验证和反思。
当下,虽然海外以OpenAI为代表,率先实现了“慢思考”大模型能力的实现,但国内厂商在后续追赶的思路上想的更多。在同步跟进o1类产品的同时,大模型公司们已经在思考如何将o1的能力和现有AI应用方向结合。
针对大模型训练进展停滞的疑虑,可以看到,在数据枯竭的情况下,o1能够为Scaling Law提供新的支撑。
此前,大模型训练已经走入了“无数据可用”的困境。当可用的优质数据资源变得越来越有限,给依赖大量数据进行训练的AI大模型带来了挑战。
更多大模型公司的加入,或将联手探索出更大的可能性。“o1 已经 scale 到了一个很大的规模,我认为它带来了一个 Scaling 技术的新范式,不妨称之为 RL Scaling。而且 o1 还不成熟,它还是一个开端。”姜大昕说。
在现有的一些AI应用上,思维链的能力已经帮助提升了AI技术的使用效果。
以智谱的“会反思的AI搜索”为例,结合思维链能力,让AI能够将复杂问题拆解成多个步骤,进行逐步搜索和推理。通过联网搜索 + 深度推理,再将所有答案信息综合整理到一起,AI能够给到一个更加精准的答案,
当大模型开始学会“自我思考”,通往L3(Agent)的大门也正在被大模型公司们推开。
“从L1到L2花了一段时间,但我认为L2最令人兴奋的事情之一是它能够相对快速地实现L3,我们预计这种技术最终将带来的智能体将非常有影响力。”谈及o1,Sam Altman肯定了“慢思考”模型对推动智能体发展的潜力。
在智能体的能力实现上,思维链是智能体功能的重要一步。应用思维链能力,大模型才能对接受到的任务进行规划,将复杂的需求拆解成多个步骤,支撑智能体的任务规划。
最近涌现的一批“自主智能体”产品就是Agent能力的突破:通过将执行任务拆解到极致,AI开始学会像人一样用手机、电脑,帮助用户完成跨应用操作。智谱、荣耀等公司推出的智能体,已经可以通过指令帮用户完成点单购买的任务。
但以目前的情况,开发者还需要具体结合o1类产品的能力,去调整智能体的输出效果,让它更接近人类的使用习惯。
在如何不过度思考的情况下,平衡大模型的推理进化和用户对效率的需求?这是杨植麟几个月前在云栖大会上的提问,这个问题,还需要留给国内大模型厂商们继续解决。
评论