过去一个月来,深度推理模型的混战已经渐趋白热化。无论是此前就已经对外发布深度推理模型的厂商,还是当下试图追赶这波大模型全民普及热潮的科技公司,都暗自在推理模型上发力。
国外,最先受到冲击的 OpenAI 不得不临时上新 o3-mini,免费开放给用户使用。马斯克旗下的 xAI 发布 Grok3,宣称是世界上最聪明的 AI。Anthropic 发布混合推理模型 Claude 3.7 Sonnet,主打将两种思考方式合二为一。
国内厂商也不遑多让。阿里巴巴对外开源推理模型 QwQ-Max-Preview。腾讯借着元宝接入 DeepSeek 的东风推广混元 T1,字节豆包亦被爆出正在内测最新推理模型,百度则强调即将于 3 月发布文心 4.5,外界称将强化推理能力。
科大讯飞此前已对外发布了基于全国产算力训练的推理模型星火X1,昨日又宣布完成了星火X1的全新升级。升级后的星火X1,仅用 70B 参数规模,就在数学能力上实现了与DeepSeek R1(参数量671B)和OpenAI o1的全面对标,中文数学任务更是全面领先。相较于DeepSeek R1,X1不仅答题速度更快,而且解题过程和步骤也更为清晰。作为国内率先落地应用的推理模型,此次X1取得的技术突破,将大幅降低大模型的推理训练以及部署成本,进一步加速中国大模型产业的落地应用。
测试集结果显示,升级后的星火X1在数学答题能力上实现了全面提升,尤其在解答竞赛级难题时,相较于国内外主流大模型,展现出了更加显著的优势。在各项数学竞赛试题的测试中,星火X1全面超越了参数量高出其一个数量级的DeepSeek-R1。
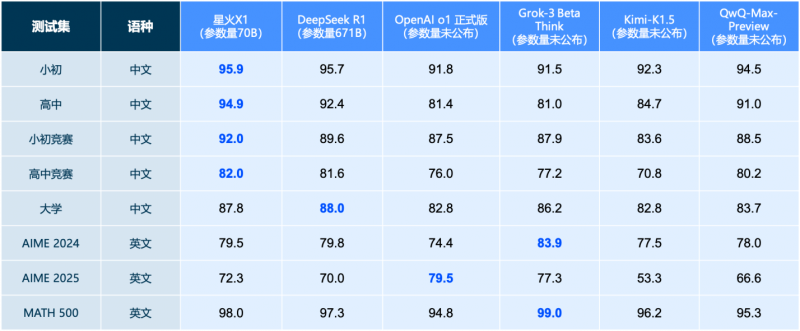
测试集合来源:中文测试集来自2023/2024年各学段考试真题/模拟题/竞赛题,英文测试集来自AIME 2024/2025和MATH 500竞赛集
是骡子是马,真刀真枪的测试见真章。我们直接上数学真题来测试星火 X1 与DeepSeek-R1。
之所以用数学能力而非文字创作等测试,是因为对于推理模型而言,数学能力才是深度推理模型最核心、也是最重要的能力。它就像是推理模型的基本功,只有数学能力过关了,推理模型才能在更多领域保证严谨和准确。
下面,我们随机选取两道中英文数学试题,来对比星火 X1 和 DeepSeek-R1。
以 2024 年高考全国甲卷理科数学试题中的一道选择题为例:

DeepSeek-R1 与星火 X1 都能解出正确答案 C,但 DeepSeek-R1 共耗时 224 秒,星火 X1 用时少了一分多,仅耗时 124 秒就解出了正确答案。
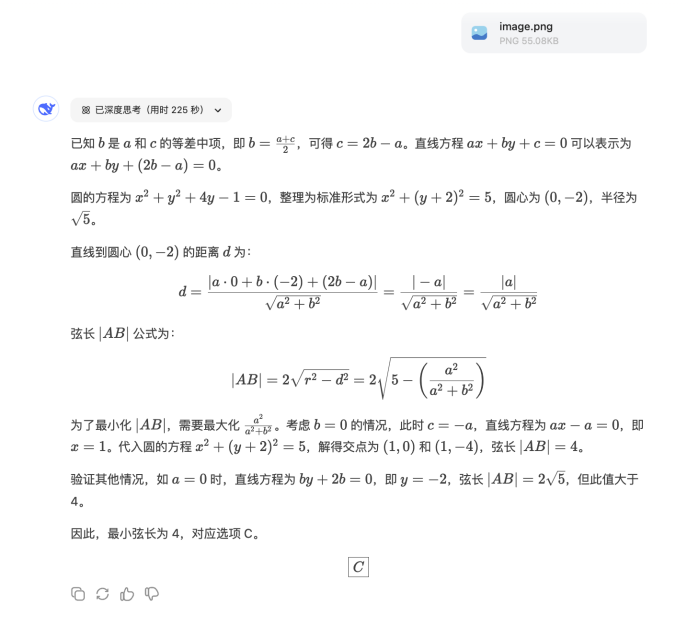

上为DeepSeek-R1,下为星火X1
此外,星火 X1 此次升级之后,保留了 X1 的完整思考过程。从思维链中可以看到,X1 早早地用代数方法解答出了正确答案 C,但此后又多次检查验证,最后甚至重新又换了另外一种解题思路,多次验证、检查确认无误后才输出正确答案。
以一道 AIME 2024 真题为例:
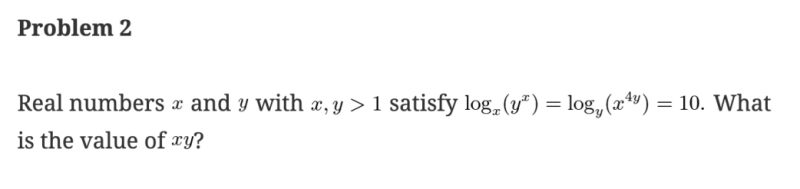
二者同样都能解出正确答案 25,但星火 X1 仅耗时 234 秒,而 DeepSeek-R1 则用了 323 秒,仍然是星火 X1 的解题速度更快。


上为DeepSeek-R1,下为星火X1
从上边两道题的解答过程和结果中,我们不难发现,星火X1不仅准确给出了题目答案,而且解题速度远超 DeepSeek-R1,解题过程和步骤也更为清晰。
星火 X1 之所以能用更少的算力、更小的参数规模实现对满血版 DeepSeek-R1 的超越,离不开科大讯飞的两大技术创新。
一是通过高效的领域数据自动化挖掘和多类型数据合成算法,构建了海量的数学领域预训练数据,从而显著提升了基座模型的数学专业能力。
二是基于评语模型与强化学习算法,实现了大模型长思维链的激发,同时评语模型还促使大模型在推理过程中进行反思验证,进一步提升了模型在推理阶段的准确性。
尤其是对于当前国内算力紧张的局面来说,星火 X1 的技术突破更具意义。仅有 70B 参数规模的星火 X1,可以让未来模型的推理训练以及部署成本都大幅下降,加速中国大模型产业的普及和应用。在星火X1升级的同时,科大讯飞还联合华为联合发布了全新升级的星火一体机系列新品,不仅支持DeepSeek部署,更可以做到单台机器即可部署星火X1。
未来,大模型不再是大型企业或者科技公司的专属,中小公司乃至普通人也都能低成本地拥有专属大模型。科技普惠的目标有望真正实现。
和多数市面上的推理模型仍停留在“对话框”乃至预览阶段不同,星火 X1 推出仅仅一个多月时间,就已经在各行各业广泛应用。基于星火 X1 的强大推理能力,科大讯飞旗下讯飞晓医、星火教师助手、AI学习机等重要产品也实现了全新升级。
以讯飞晓医为例,其背后是星火医疗大模型 X1 的重磅升级。医疗大模型 X1 基于星火 X1 研发,大幅降低了医疗幻觉问题,在面对复杂问题时也可以逐步解释循证过程,提高医疗复杂场景推理的逻辑正确性、专业性、可解释性。
技术的创新从来都不是一蹴而就的,无论是此前 DeepSeek 打破模型训练高成本的算力桎梏,还是星火 X1 用更有限的全国产算力平台实现更小参数的胜利,都彰显出中国科技企业在人工智能领域的突破性跃迁。
从最早坚持使用全国产算力平台,到今天的 70B参数就完成对主流推理模型的超越,科大讯飞用实际行动证明了中国科技企业的韧性与顽强。中国大模型产业不仅要站起来,更要跑起来!
(免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。)
评论