

中国人民大学科学研究处、中国人民大学信息资源管理学院:钱明辉、杨建梁
在新一代人工智能加速演进的过程中,数据不再只是信息的原料,更成为驱动智能系统持续进化的“第一性资源”。如果算法构成了智能大脑的结构框架,那么数据则是决定其认知边界与价值取向的核心要素。厘清数据与数据集之间的关系,明确不同类型数据集的结构特征与应用场景,并深刻认识其在模型训练、系统部署和技术治理中的作用,已成为智能时代基础能力体系构建的重要起点。从单点采集到结构组织,从模型输入到系统输出,数据的价值正在从底层积累中持续释放,推动人工智能从感知智能向认知智能稳步迈进。
相关阅读:

知识蒸馏与数据萃取:开发人工智能训练所需的“动态食谱”与“黄金食材”
一、数据之内涵:似曾相识的概念体系
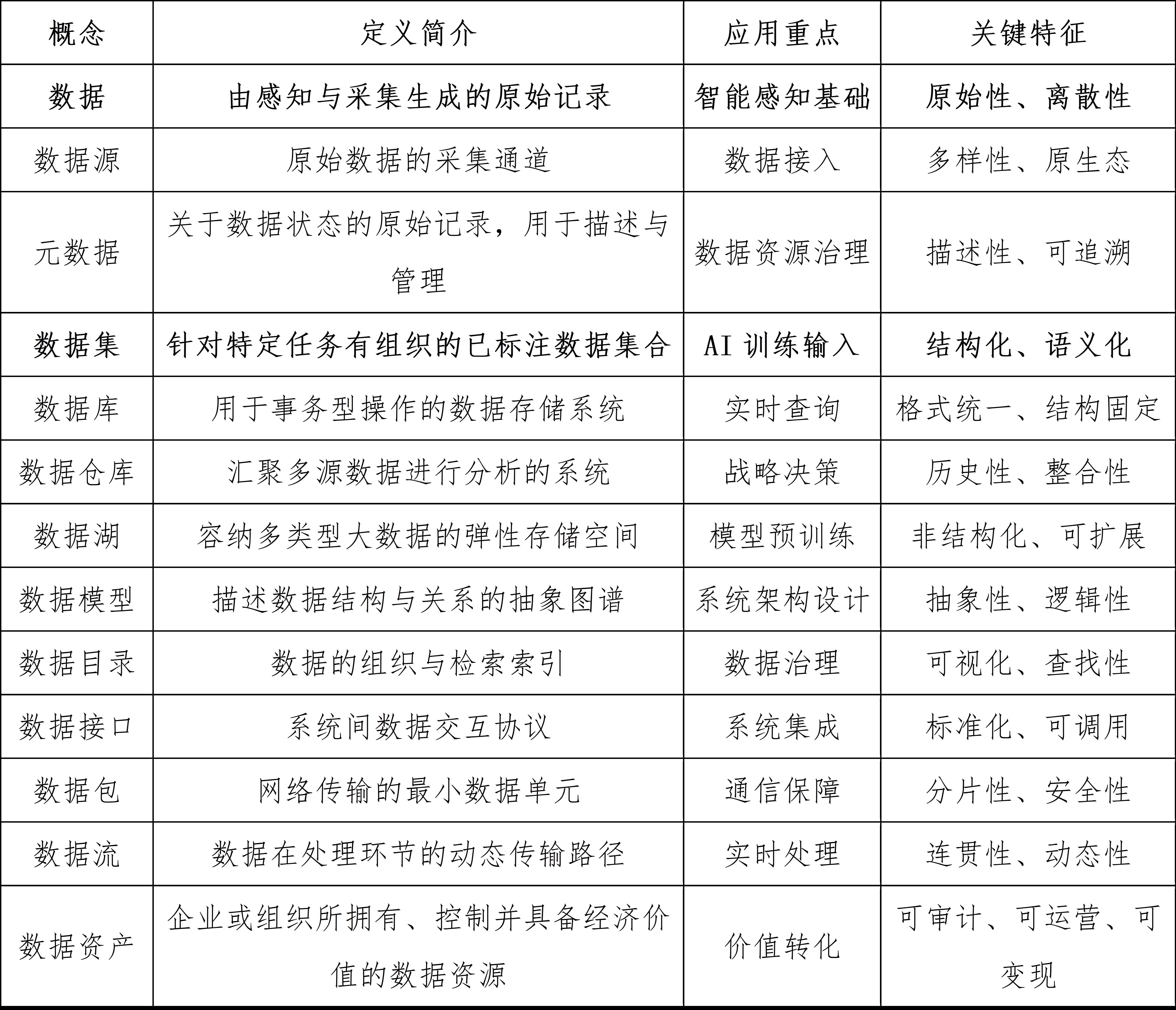
在人工智能工程体系中,“数据”已不再是单一的信息元素,而是构成整个智能系统认知能力的基础单元,其内涵也演化为一套涵盖采集、组织、建模、流通等多个层面的系统性术语体系。要实现对数据资产的高效构建与科学治理,首要任务是厘清与数据相关的一系列似是而非的概念,搭建起有逻辑、有层次的数据工程认知框架。
数据的生成始于对现实世界的感知,它通常来自传感器、用户输入、网络行为等等,是智能系统进行分析和推理的原始素材。数据源指的就是这些信息的获取通道,既包括线下的物理设备,也涵盖各种类型的线上系统和平台。随着数据的生成,元数据也随之形成——它记录了数据的属性、格式、时间、来源等信息,是实现数据管理和追踪的基础性工具。
原始数据只有经过组织和处理,才能真正为人工智能所用。数据集是在特定目标下,对数据进行清洗、标注与分类后形成的集合,是各类人工智能模型训练和测试的基本资源。而数据库则主要用于支持日常业务,强调结构化存储与高效查询,常用于实时交互与信息系统之中。相比之下,数据仓库更偏向于战略分析,它通过整合不同来源的数据,采取预先定义模式(Schema-on-Write)来展开固定分析,支撑企业级的长期决策。数据湖是集中存储海量原始格式(结构化、半结构化、非结构化)数据的存储系统,采取按需定义模式(Schema-on-Read),可以支持多样分析场景。
为了让系统“理解”这些数据,就需要构建逻辑结构。数据模型用于描述数据之间的关系,是数据库、数据仓库得以运行的底层设计。随着数据资产的增长,数据目录成为数据管理中的关键性工具,它就像“数据地图”,帮助用户快速检索、调用与管理数据资源。
数据不仅需要存储和建模,还要能在不同系统间高效流通。数据接口起到连接作用,确保各平台间的数据交换顺畅无阻。在网络传输过程中,信息通常被打包为多个数据包进行传输,以提升传输效率与稳定性。贯穿整个流程的数据流,则体现了数据从采集到应用的动态路径,是实现实时处理与边缘计算的核心机制。
伴随着数据在生成、组织、管理与流通各环节中的角色不断跃升,其本质也从传统信息资源逐步转化为具有战略价值的关键要素。数据资产的内涵正是如此:它是企业或组织拥有或控制的、具备经济价值的数据资源,能够通过算法分析、智能应用或市场交易等方式转化为可度量的现实效益。与传统资产相比,数据资产展现出可审计、可运营、可变现的独特特征,不仅成为算法能力的输入源,更是推动智能系统持续演进的“引擎”。

总的来说,这些概念共同构成了现代数据体系的技术底座。从数据的感知采集到系统中的组织、建模、传输与调度,每一个环节都不可或缺。它们不仅保障了人工智能系统的运行效率与决策能力,更为数据集的高质量构建、规范管理与价值释放奠定了坚实基础,是推动AI系统实现从“算法驱动”走向“数据牵引”的关键支撑力量。
表1 数据相关概念解析
二、数据集类型:多元视角的分门别类
在人工智能应用日趋精细化与多元化的背景下,数据集的类型划分早已超越“结构化与否”的传统维度,转而呈现出更加立体化的分类逻辑。理解不同类型数据集的特点与适用场景,不仅是高质量数据工程的前提,也是在实际部署中实现人工智能模型精度与效率双提升的关键。
从数据结构的组织方式来看,数据集可分为结构化、半结构化与非结构化三类。结构化数据集以严格对齐的二维表结构为核心(如关系型数据库表、CSV文件),典型如金融交易流水表或企业订单记录,可直接通过SQL进行管理;半结构化数据集以动态标签或键值对为核心(如JSON日志、XML配置文件),需解析嵌套字段(如使用Spark处理物联网设备时序日志),适用于网页爬取或灵活存储场景;非结构化数据集则以无格式约束的原始文件为主体(如医疗影像、语音录音、文本语料),依赖CV/NLP等技术提取特征(如ResNet处理图像、BERT分析文本)。另外,在实际场景中时常存在多类型混合的形态,如自动驾驶数据集一般包含相互映射的结构化的和非结构化的数据。
按数据模态领域划分,数据集可包括数值类、文本类、图像类、音视频类、空间数据类、图结构类和多种模态混合类。数值类数据集是结构化数据的典型形式,通常来源于传感器读数、财务报表、用户行为日志等,广泛应用于金融风控、工业预测、医疗监测等场景。例如,在智能电网系统中,通过历史功率数据集可以实现对能源负荷的精确预测。文本数据集支撑自然语言处理任务,如情感分析、问答系统、法律文本生成,常见语料包括中文维基百科、司法判决文书。图像数据集是计算机视觉的核心资源,多应用于医学诊断、工业检测、交通识别等领域,如COCO和ChestXray数据集。音视频数据集用于训练语音识别、多模态感知系统,如语音助手、视频摘要等应用场景。地理空间数据集包含位置、轨迹与空间分布信息,是智慧城市、自动驾驶等系统的重要支撑,如遥感图像、GPS路径数据。图结构数据集则以节点与边表示实体关系,服务于知识图谱、社交网络、推荐系统等任务,是AI实现逻辑推理与关系理解的关键。此外,还有一些数据集是融合文本、图像、音频、视频、结构化数据等的多模态混合类数据集,用于支撑复杂任务中的跨模态感知与理解,如视觉问答、图文生成、人机对话等复合应用场景。这类数据集的建设不仅对数据融合技术提出挑战,更成为推动大模型多模态能力突破的关键基石。
从时间特性来看,数据集可划分为时序数据集与静态数据集。其中,时序数据集强调时间连续性,适用于预测与动态建模,如传感器监控、股市行情、气象变化等;静态数据集则是由捕捉某一时点的信息快照构成,常用于图像识别、人脸比对、城市建模等静态任务。此外,依据人工智能模型训练流程的不同阶段,数据集还可分为训练集、验证集与测试集三类。训练集用于模型学习和参数拟合,是模型能力形成的核心数据基础;验证集在训练过程中用于参数调优与性能监控,帮助提升模型的泛化能力;测试集则承担最终评估职责,用于检验模型在真实场景中的适应效果。三者共同构成AI模型从训练到部署的闭环体系。
不难看出,数据集已从传统的“数据集合”概念,演化为驱动人工智能系统构建、训练、部署、进化的基础性资源。无论是支撑AI模型能力提升,还是实现行业应用落地,选择适配场景的数据集类型,构建科学合理的数据结构,都是人工智能工程中不可或缺的基础环节。不同类型的数据集服务于不同的AI需求,其背后反映的是从数据原料到智能系统之间日益紧密的耦合关系。

三、数据集意义:人工智能的首要资源
数据集作为人工智能系统演化的基础载体,其作用早已超越“训练材料”的初级定位。数据集不仅是人工智能系统的输入资源,更是其能力构建、价值表达与生态扩展的核心基础。从模型学习到产业落地,从技术突破到治理进化,数据集的作用贯穿于人工智能发展的全链条,是推动当前人工智能技术范式持续演进的关键变量,其系统意义体现在以下五个层面:
一是支撑智能算法演进,构建AI模型能力的成长基座。数据集是人工智能模型从“零认知”走向“类智能”的第一步。质量可靠、标注精确、覆盖广泛的数据样本,为神经网络提供了充足的学习素材,使模型得以从基础感知任务逐步跨越到复杂的语言理解、视觉推理与行为预测。同时,结构合理的数据集还能有效减少过拟合,提高模型的泛化能力,是保障算法稳定性与可扩展性的核心抓手。
二是加速技术应用落地,提供系统适配现实的转换接口。无论是语音助手、自动驾驶,还是医疗诊断、金融风控,人工智能的系统部署无一不依赖于高质量、场景对齐的数据集作为输入支撑。语音识别系统需要真实用户口音语料,自动驾驶算法必须依托各类交通场景图像进行泛化训练,医学辅助系统则高度依赖高分辨率影像与专家标注的病例信息。数据集不仅帮助算法理解现实,更是技术能否走出实验室、服务实际场景的决定性因素。
三是连接科学技术产业(STI),构建持续协同创新的生态纽带。标准化、开放化的数据集极大降低了算法研发门槛,使得企业可以快速验证模型方案,研发机构也能借助真实世界数据开展落地研究。比如,SQuAD文本问答集、Kaggle平台的产业数据集,都在推动AI生态系统”的跨界创新与人才成长方面发挥了深远影响。同时,企业私有数据的专业深度与科研开放数据的通用广度也形成了互补关系,共同构建了人工智能领域的“双循环”创新机制。
四是保障系统公正可控,铸就算法合规治理的技术前提。人工智能系统的价值输出,最终取决于其背后的数据输入。因此,构建多样来源、结构透明、价值对齐的数据集,成为AI系统可持续演化的道德基础与治理前提。例如,在司法文书生成、教育内容推荐、金融风控评估等场景中,数据集是否涵盖不同族群、文化背景与行为特征,将直接影响系统的公平性与可信度。标准化的数据质量评估机制与数据脱敏处理流程,正在成为AI伦理提升与合规治理的重要抓手。
五是激发技术创新动能,成为智能瓶颈突破的高效燃料。高密度、高覆盖的数据集不仅提升了模型训练的效率,更孕育了众多新的研究方向与方法变革。迁移学习、预训练大模型、对比学习、数据蒸馏等新范式的诞生,背后都离不开经过规范治理的大规模数据资源的支撑。反过来,模型能力的提升也能够反向推动数据集建设从简单积累转向结构重塑,促成“模型与数据”双向驱动的良性闭环。

“聚沙成塔”不仅是对数据量级的比喻,更是对认知演化过程的真实写照。每一个精心构建的数据集,都是人类知识、经验价值的凝结体,是智能系统走向可信、可控、可持续的基础单元。从感知、建模到决策,从单一任务到通用智能,从孤立工程到系统治理,一路走来,数据集的角色不断被认识、被重塑、被强化,正在从人工智能开发的辅助工具跃升为智能体系进化的核心要素。当数据成为战略资产,数据集的建设与治理将决定AI社会演化的轨迹与速度。唯有以系统性思维构建数据体系,持续提升价值对齐度、知识密集度与业务响应度,才能真正让人工智能从“能用”走向“好用”,从“看得见”走向“信得过”。未来的AI塔尖,将由今天每一粒数据沙粒筑成。
基金项目:国家社会科学基金重点项目“基于数智融合的信息分析方法创新与应用”;国家档案局科技项目“基于生成式人工智能的档案数据化关键方法及其应用研究”。
致谢:感谢中国人民大学信息资源管理学院应芷安博士后在本文完成过程中所提供的资料收集与整理支持。

评论