

Qwen 3模型即将发布的消息,已经流传了一个月的时间;特别是最近一周内,坊间对Qwen 3的猜测不断在“憋个大的”与“最终难产”之间反复横跳。
直到4月29日凌晨,这款备受关注的模型终于亮相,号称全面超越DeepSeek R1。
杭州一家中厂的算法从业者告诉「电厂」:“近几个月网上不少DeepSeek R2的泄露信息,有人说R2要在5月份发。Qwen 3(这个时间发布)肯定是想抢个先机。”
在一家国产大模型开放平台工作的刘露则透露,其所在的团队提前不到12小时获知Qwen3的发布消息,团队成员连夜完成了Qwen 3系列模型在该平台的部署上线。
无论如何,Qwen 3的亮相都意味着开源AI大模型的技术能力再次被刷新;与之相继的,将是产业链下游应用者迎来一次新的生态选择。
「电厂」注意到,Qwen 3发布仅10小时,已经有开发者发布了套壳Qwen 3系列模型的ChatBot类产品。

基于Qwen 3的第三方ChatBot类产品,图源/网络

国内首个混合推理模型,成本/性能超越DeepSeek R1
根据阿里云通义千问团队官宣,Qwen3系列开源了8个模型,其中包含2个MoE(混合专家)大模型和6个Dense(稠密)大模型。
本次Qwen3系列模型尤为值得关注的创新是该模型支持思考模式、非思考模式两种运行方式。
在思考模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法适合需要深入思考的复杂问题;在非思考模式中,模型会提供快速、近乎即时的响应,适用于对速度要求高于深度的简单问题。
换句话说,Qwen3打破了DeepSeek R1等思维链模型慢思考的单一模式,而是为用户赋予灵活选择的权利。这也是如今全球大模型市场发展的重要方向之一。
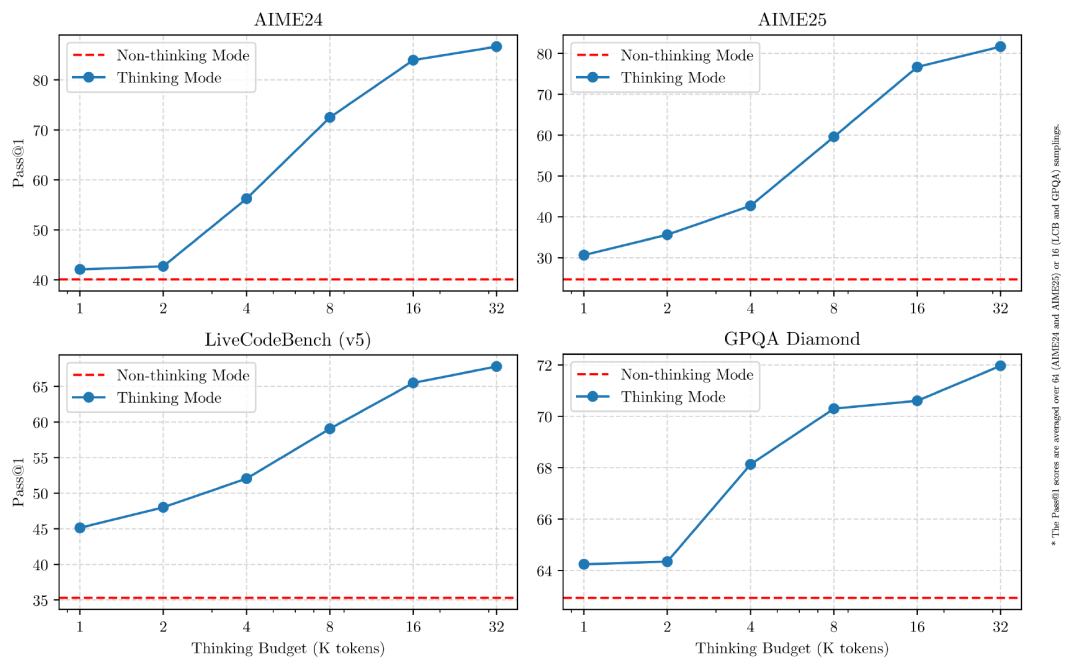
不同Benchmark下Qwen3两种思考模式对比,图源/阿里云通义 今年2月份,由部分OpenAI前员工创办的Anthropic在全球范围内率先发布了名为Claude 3.7 Sonnet的混合推理模型,被视为融合了DeepSeek V3(适于通用任务)与R1(适于推理任务)模型的各自优势。
这种混合模式引起了业界的广泛关注。OpenAI创始人Sam Altman就曾表示,OpenAI接下来将研发“它能够知道什么时候应该长时间思考,并且通常适用于广泛任务”的模型。而Qwen3是国内首个混合推理模型。
性能及成本优化方面,Qwen3系列也表现惊人。
比如本次开源的两个MoE模型,权重分别为Qwen3-235B-A22B,是一个拥有 2350 多亿总参数和220多亿激活参数的大模型;另一个为Qwen3-30B-A3B,一个拥有约300亿总参数和30亿激活参数的小型MoE模型。
MoE(混合专家模型)混合包含多个专家网络,每个专家通常是一个子模型、也可以是神经网络的一个子模块,拥有不同的能力或专长,能够处理不同类型的输入数据。在运行时,不同任务会被进行分类、输送到相应的“专家”处进行解决。
DeepSeek V3与R1都属于MoE模型。这种架构的优势是其能够,并且在解决任务时仅调动与之相应的模块、节省计算成本。这也是“AI界拼多多”DeepSeek提升性价比的杀手锏之一。作为与Qwen3的对比,DeepSeek V3与R1总参数规模为6710亿参数,激活参数为370亿。
性能方面,官方信息显示,Qwen旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,均展现出优势。
小型MoE模型Qwen3-30B-A3B ,相比DeepSeek V3、GPT 4o、谷歌Gemma3-27B-1T等模型同样表现优异。
六个开源的Dense模型均适用于通用任务解决,包括Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B。
值得一提的是参数量极低的Qwen3-4B模型,也在不少任务中展现出来相比GPT 4o更为优异的成绩。
上述模型均在 Apache 2.0 许可下开源。这是一种较为宽松的许可证,允许代码修改和再发布(作为开源或商业软件)。
Qwen3模型还支持 119 种语言和方言,并优化了Agent和代码能力、加强了对MCP的支持。

开源大模型“城头变换大王旗”
Qwen3的发布,距离DeepSeek R1的亮相已过去了3个多月。
1月20日,凭借比肩OpenAI o1的性能、低廉的成本,以及对大模型研发范式的改变,R1一经发布就荣膺开源大模型世界的“无冕之王”至今。
在此期间,包含科大讯飞(星火X1)、百度(文心X1)、OpenAI(o3 mini)、阿里(Qwen-QwQ-32B)、字节(豆包1.5深度思考)在内的玩家纷纷下场推理模型,但至多是接近R1性能或实现部分超越,未能真正挑动后者的位置。
在大模型的世界里,数月的时间已足够一代新王换旧王。正是这样的背景下,关注的目光落到了Qwen3身上。
与许多国内玩家不同的是,早在2024年8月,阿里就公开站到了开源自研模型的大厂阵营之中。在这条最终被DeepSeek验证可行的市场之路上,Qwen可以说已经提前拿到了不少牌。
至今Qwen系列产品已在不少开源榜单中排名靠前。如据全球最大AI开源社区Huggingface 4月29日显示,在audio-text-to-text任务类目下,Qwen的两款模型热度居前。
Huggingface 于2月10日发布的开源大模型榜单“Open LLM Leaderboard”也显示,排名前十的开源大模型全部是基于Qwen开源模型二次训练的衍生模型。
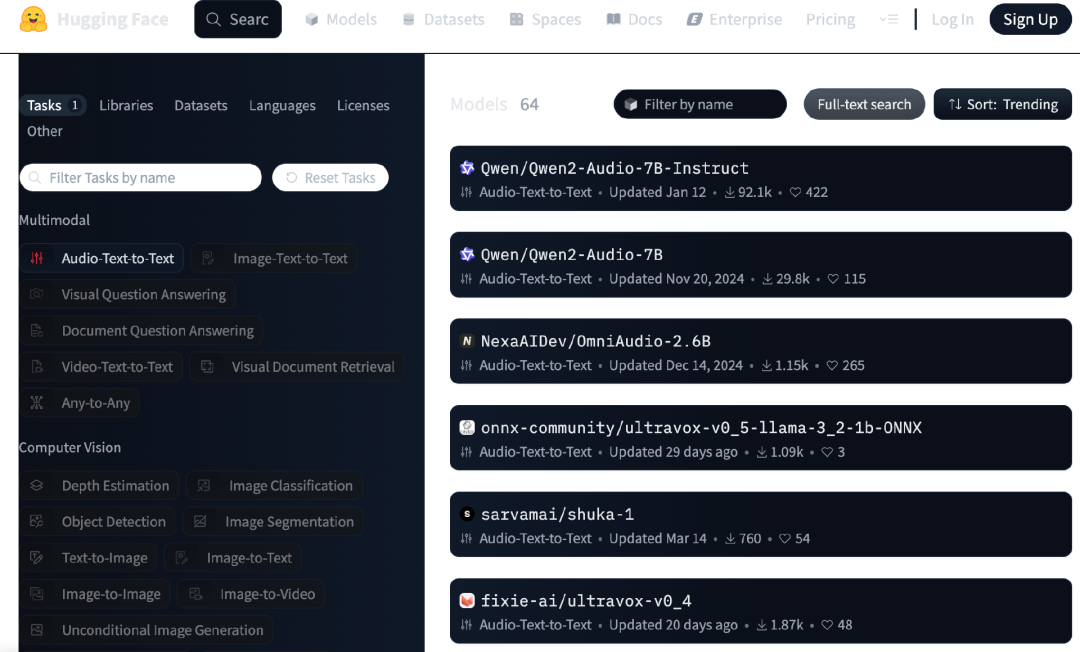
图源/Huggingface 在生态活跃度方面,Qwen也处于全球前列。据官方数据显示,从2024年下半年开始至2025年1月底,基于Qwen系列的衍生模型数量超过了美国Llama系列,超过9万个,已是全球最大的AI模型家族,超过了Meta 旗下的Llama家族。
不过对比Llama系列,Qwen系列开源模型在下载量方面与前者仍有差距。据Meta首席执行官Zuck Burg在今年3月份宣布,Llama的下载量已达到10亿次;而Qwen系列的下载量还在千万级别。
在Qwen3发布这一天,周靖人接受了“晚点”的采访,他讲道,判断“开源生态跑出来了”的指标主要有两点“一是看开发者的选择,二是看性能指标”。
本次随着Qwen3的发布,这款新模型通过在性能指标和成本方面超越DeepSeek R1,以及创新的混合推理模式,登顶为全球最强大的开源大模型,又为Qwen增添了一张好牌。
但在这之后,还有更多的挑战等待着它。接下来DeepSeek R2的亮相,也将为整个市场增添新的变数。
在贯彻“第一通吃(winner-takes-all)”定律的开源市场,竞争远未到达终局、谁能成为最终的“winner”还充满未知,无论是DeepSeek,还是Qwen和Llama,都仍需要为不下牌桌而持续努力。
不过值得欣慰的是,虽然战程未半,至少当下的开源大模型“桂冠”仍归属于国产玩家。
(注:文中刘露为化名)

评论