
前言
互联网发展到今天,已经从线上到线下,逐渐深入覆盖人们生活的每个角落,早年互联网先驱们立志追求的,让互联网服务成为在线生活的水和电的目标,已经越来越接近被实现。水和电当然不能说断就断,因此对于服务持续可用的要求也随之不断提升,并成为衡量互联网服务优劣的核心要素之一,甚至有云服务商为了争夺客户,喊出“永不掉线”的PR口号。口号归口号,在理想与现实的辗转之间,我们如何一边竭尽全力去靠近这个目标,一边又如何采取务实的手段去应对不完美的常态,是一个摆在所有相关从业者面前的一个问题。笔者在这里结合过往多年的互联网行业经验,以及个人的一些思考,梳理出了几条可以参考的价值观。需要注意的是,这里的价值观并不是形而上的抽象思想,而是可以指导具体问题的决策和执行的一些准则。
你是我的眼:监控先行
如果问到监控的重要性,几乎所有的互联网架构师都会给出肯定的回答,但是如果问到你的系统什么时候完成了监控,往往又落入知易行难的套路。所以我们经常看到一个服务上线了一年半载,相关监控覆盖仍然遥遥无期,而且经常是频频发生的故障和事故在推动监控一点一点被完善。
我们需要深刻认识到的是,监控是我们的眼睛,是服务上线后一系列问题发现和解决、系统优化和持续运营的前提,所以,请在服务第一次发布的同时,部署好你的监控,相关的监控代码应该和功能开发代码同时完成并且同时通过测试。当然,一套大而全的监控体系是非常耗费人力物力的,所以我们的初始化监控(随服务第一次发布上线)的底线,首先要满足“立体化”的要求,后续再去追求“精细化”、“自动化”、“可视化”等优化要求。
何谓“立体化”监控,这里借用一张典型的多层Web服务架构的监控需求图来说明:
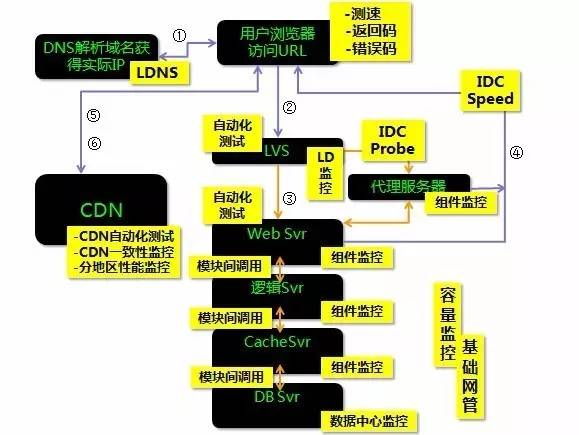
初始化监控的标准是:一定要覆盖每一层的调用结果,一开始可以简化到记录一个返回码和一个调用延时,上报到统一的监控系统甚至本地打log,但是一定要确保覆盖每一层,只有这样才具备基本的立体化监控能力,在故障出现的时候,才能快速定位到是哪一层的问题,也能快速找到正确的人来进一步分析和解决问题,避免出现前台怪后台、后台怪数据库、数据库怪第三方组件的尴尬局面。
分布只是过程,可伸缩可调度才是目标
分布,应该是提升容灾能力和服务可用率的最主要手段,然而在实践中,经常出现目标的错配,很多团队往往在其他IDC或者城市分布了一套数据和服务,就开心的宣称自己有跨IDC/城市的容灾能力了。然而故障一旦出现,仍然需要大量的人工干预:修改配置文件、切换请求通道、同步状态位甚至数据,一整套折腾下来,服务中断的时间并没有降低多少。说好的自动切换呢?说好的用户无感知呢?说好的运维团队可以睡个好觉呢?
一个成功的分布,一定要达到可伸缩可调度的境界:分布出去的多套服务可以根据业务场景、负载均衡、就近接入、故障发生等因素,动态调整提供服务的级别,这个动态的过程必须是自动无须人工介入的,这样才能保证从故障发生到重新实现可用平衡的时间控制在分钟甚至秒级别,从而真正大幅度提升服务的可用率。
因此,在把数据和服务分布出去之后,应当继续完成以下工作:
对所有的分布服务建立完整监控(上一条价值观提到的)
根据获取到的监控数据,建立智能化的伸缩和调度策略
一旦故障发生,预设的策略被自动执行,并记录下所有的变更log
下图是笔者在前公司主导过的一个异地分布项目,当时在深圳和上海两地分布了完整的服务,杭州分布了有限服务(只在故障时临时启用)。从图中可以看到深圳和上海两地的同步和互访通道建立了4条,并根据实时监控的通道质量来动态调度。
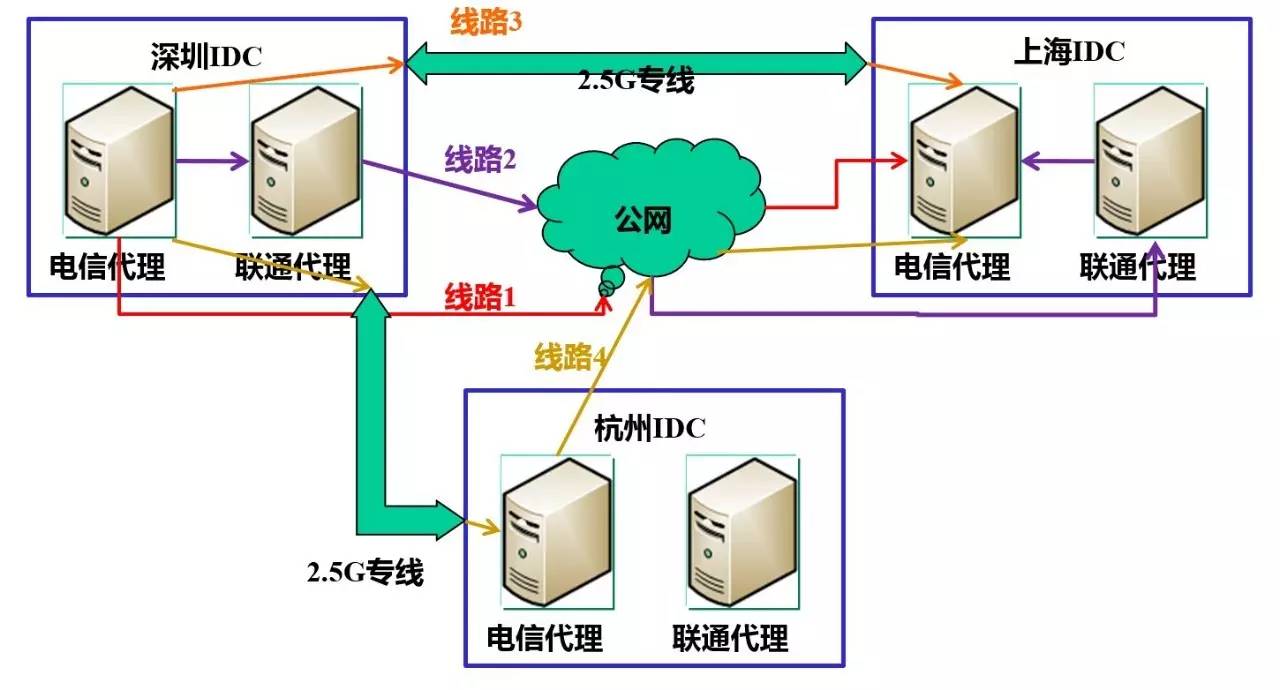
有了以上保障,开发和运维只需要事后review故障记录就行,半夜起床救火的日子一去不复返。还记得这个项目最后获得公司级奖项的时候,笔者只说了一句获奖感言:“感谢这个项目,最近我们的睡眠质量有显著改善”,多么痛的领悟啊......
快速响应高于完美一致
我们都希望给用户提供完美的一致性服务,在尤其严苛的传统金融行业, 通常遵循ACID(Atomicity、Consistency、Isolation、Durability)作为系统设计的价值观,在互联网服务的江湖,因为ROI(互联网行业ARPU远远低于金融业)和数据特点(互联网数据毕竟没有账户金额那么敏感)的考虑,大家逐渐用新的价值观BASE(Basically Available、Soft State、Eventually Consistent)来指导我们的系统设计。事实上,BASE是在多种因素综合权衡下的无奈之举,我们必须要接受不完美的常态,并且做出一些适当的妥协,然而BASE中所有的妥协都应该指向另外一个方面的极致追求,就是响应速度。
用户可以容忍在银行排队1小时,但是无法容忍在你的页面上等待10秒钟,即使在一些复杂情况下,我们真的需要这么多的时间帮用户完成一个操作,但是请先反馈用户,再慢慢完成这些事情。
一个典型的案例:大家可以试试在网络不好的情况下发微信朋友圈,无论如何你都会马上得到一个发送成功的反馈,伴随着即刻被满足的良好体验。但是你的好友可能会在10秒钟甚至几分钟之后才看到这条消息,原因是在网络不好的情况下,系统在后台做了大量的失败重试、确保最终一致的操作。然而这些操作没有必要让用户知道,更不应该占用他的时间,不是么?
硬挺着遭罪、弯弯腰享福:服务应该具备的柔性
在讨论柔性服务之前,我们必须先接受2个事实:
支持服务的资源永远都是相对短缺的;
服务所处的环境永远都是不稳定的;
在以上两个问题凸显的时候,我们是刚性的选择给用户0或1两种服务,还是去探求这之间的从0.1到0.9的多种状态?
互联网在线服务的一大特点,就是用户访问具有很大的波动性,举几个例子:一个突发新闻热点事件出现后,门户网站的流量会暴增;电商网站促销,交易量几十倍上升;节假日临近,车票预订网站面临抢票高峰。类似这样的场景,服务方往往无法在短时间内增加大量的硬件资源,来支撑突增的访问量。如果我们还硬撑着给用户提供完美服务的话,系统会在远远超出正常负荷的状态下运行,很大的可能会造成雪崩,服务直接从1降到0。
建立服务的柔性,即是在因为访问突增或者故障等原因导致的资源不充足的情况下,主动降级,放弃一些非关键的服务,保留核心服务,尽可能满足用户需求的同时又保持系统不至于全面崩溃。所以,建立柔性服务应该包含以下几个步骤:
1) 从产品层面梳理用户的核心需求,以用户视角划分出一个服务所提供的feature list以及优先级;
2) 评估feature list里面每一项feature所需要的硬件资源水平(网络带宽、CPU计算量、内存/硬盘等存储量);
3) 根据feature的优先级建立服务的柔性等级;
4) 对柔性等级设置开关,根据实时的资源情况切换对应的开关;
下面借用腾讯QQ曾经的一个柔性服务级别来作为示例:
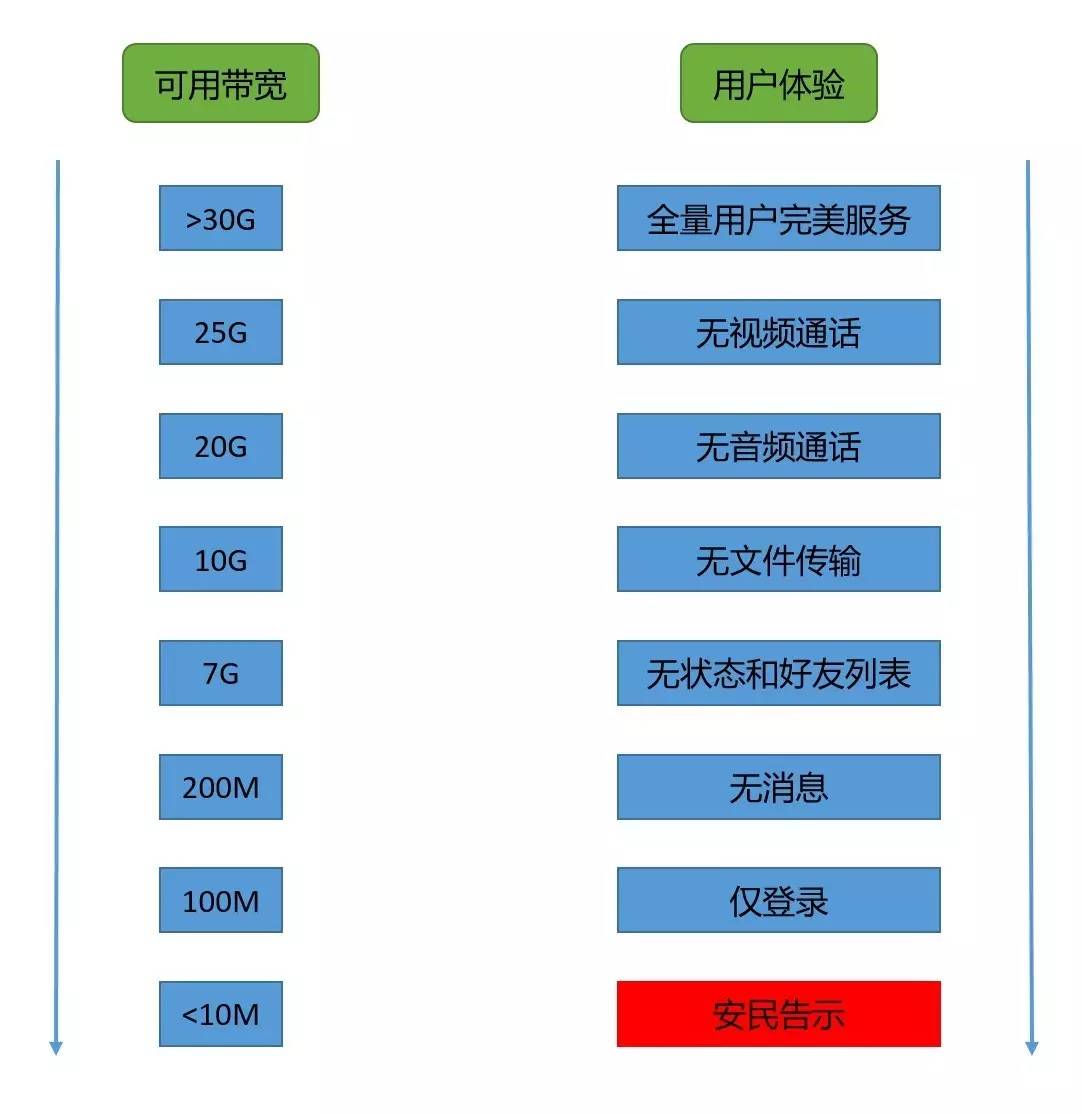
有限的资源就像是一道矮门,当我们经过这扇门时,如果不懂得弯腰,必然会碰的头破血流,学会弯腰,哪怕牺牲一些姿态,却能帮我们安全通过。
时刻准备好末日告白
最后的最后,终于来到了大家都不想面对的一个境地,当发生了最极端的情况,必须要接受服务完全中断的局面。在此时,我们要做的是尽全力维护用户的知情权。因此,随时准备好一份安民告示,是非常有必要的。告示的内容一定要包含用户最关心的信息,例如:故障原因、影响范围、账号等核心数据是否安全、何时能恢复服务等。
与此同时,在这样悲伤的时刻,我们如果可以引入一些有趣味和有创意的内容,用户的不满情绪会得很大程度的安抚甚至转移。
以下是两个网站发生404错误(虽然这不是一个典型的服务故障)后的处理案例:
1)腾讯发起的404公益活动,在出现404错误的时候展示失踪儿童信息:

2)丁香园的404展示页面:

结语
以上的一些价值观,在互联网服务的实现中有很现实的指导意义。然而,在互联网+的时代背景下,更值得我们去思考的,是传统行业转型、传统服务互联化的过程中,该如何去吸收融合这些价值观,并且重塑新的价值观,这,又是一个新的话题.......

本文作者:周文江(点融黑帮),现任点融深圳site-manager,新南威尔士大学计算机硕士,曾在腾讯履职8年半,也有过2年多的创业经历,在互联网研发和团队管理方面有较为丰富的经验。
评论