

文|新智元
编|文强
还记得英伟达震撼世人的新一代GAN吗?
以假乱真的精细人脸生成,令不少研究人员都惊呼:已经无法分辨虚拟和现实!

上述人脸全部由计算机生成,StyleGAN的全新风格迁移生成器架构能控制发色、眼睛大小等脸部特征。来源:github.com/NVlabs/stylegan
现在,这个StyleGAN已经开源,而且附上官方TensorFlow实现(点击“阅读原文”了解更多)。
论文、源代码、高清Flickr人脸图像数据集等所有的材料都公布了出来,非商业使用的情况下,这些素材任你使用和修改(Flickr人脸数据集参考另外的开源协议)。
Github库里还包含了一个基础的预训练StyleGAN生成器 pretrained_example.py,下载后使用相关Python代码,就可以直接用来生成图像了。

另一个更高级的样例是 generate_figures.py,这个脚本是用来生成论文中风格变换/混合、鼻子大小和发色调整等功能。
不过,需要提前说明的是,要生成1024*1024分辨率的图像,如果使用英伟达Tesla V100 GPU做训练,硬件配置和训练时间如下:
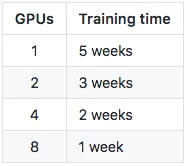
“使用较少的GPU可能无法实现与论文同样的效果——如果你想跟我们的技术一较高下,我们强烈推荐你使用同样数量的GPU。”
开源StyleGAN,莫非还有一丝卖显卡的因素(误)。
新一代StyleGAN:图像逼真到可怕,能生成世界万物
基于GAN的架构一个又一个推出,要是你一时间想不起来StyleGAN也没关系,多上几张图有助于你回忆:

这个模型并不完美,但确实有效,而且不仅仅可用于人类,还能用于汽车、猫、风景图像的生成。
英伟达研究人员在论文中写道,他们提出的新架构可以完成自动学习,无监督地分离高级属性(例如在人脸上训练时的姿势和身份),以及生成图像中的随机变化,并且可以对合成进行更直观且特定于比例的控制。
换句话说,这种新一代GAN在生成和混合图像,特别是人脸图像时,可以更好地感知图像之间有意义的变化,并且在各种尺度上针对这些变化做出引导。
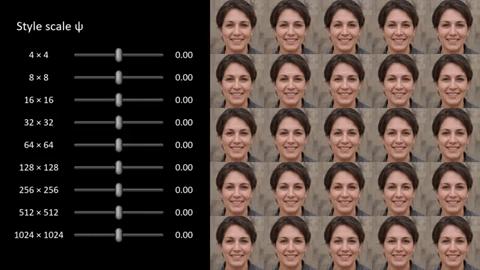
例如,在上面的动图中,其实面部已经完全变了,但“源”和“样式”的明显标记显然都得到了保留。为什么会这样?请注意,所有这些都是完全可变的,这里说的变量不仅仅是A + B = C,而且A和B的所有方面都可以存在/不存在,具体取决于设置的调整方式。
而StyleGAN之所以强大,就在于它使用了基于风格迁移的全新生成器架构:
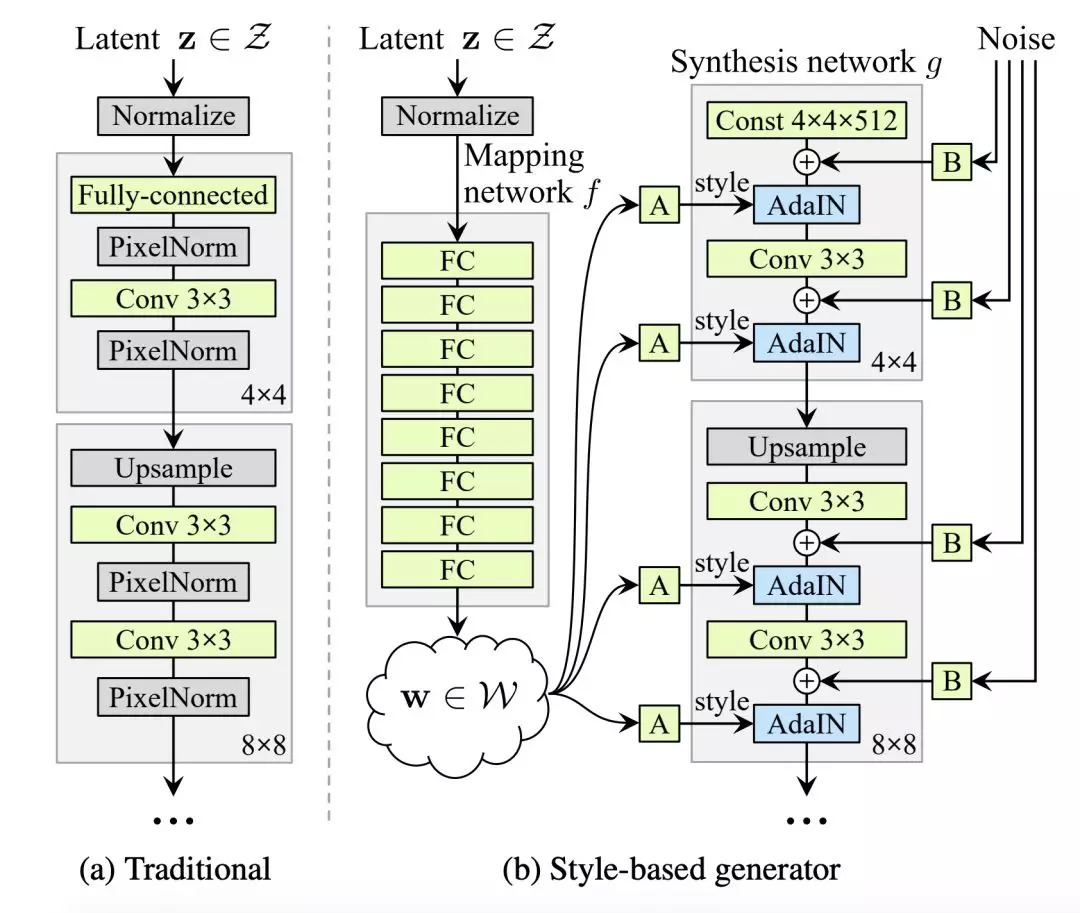
传统生成器架构和基于风格的生成器架构对比
在传统方式中,隐码(latent code)是通过输入层提供给生成器的,即前馈网络的第一层(图1a)。而英伟达团队完全省略了输入层,从一个学习的常量(learned constant)开始,从而脱离了传统的设计(图1b,右)。在输入隐空间Z中,给定一个隐码z,一个非线性网络 f:Z→W首先生成w∈W(图1b,左)。
英伟达团队的生成器架构可以通过对样式进行特定尺度的修改来控制图像合成。可以将映射网络和仿射变换看作是一种从学习分布(learned distribution)中为每种样式绘制样本的方法,而将合成网络看作是一种基于样式集合生成新图像的方法。修改样式的特定子集可能只会影响图像的某些方面。
负责任地使用,避免成为又一个“DeepFake”
之前,大多数研究都集中在如何提高“换脸”技术上,也就是如何让计算机生成超逼真的人脸。
谁料,这种技术发展的滥用造成了反效果,也即所谓的“DeepFake”。现在,DeepFake已被用于指代所有看起来或听起来像真的一样的假视频或假音频。
去年底,Idiap 生物识别安全和隐私小组负责人 (注:Idiap研究所是瑞士的一家半私人非营利性研究机构,隶属于洛桑联邦理工学院和日内瓦大学,进行语音、计算机视觉、信息检索、生物认证、多模式交互和机器学习等领域的研究)、瑞士生物识别研究和测试中心主任 Sébastien Marcel 和他的同事、Idiap 研究所博士后 Pavel Korshunov 共同撰写了论文,首次对人脸识别方法检测 DeepFake 的效果进行了较为全面的测评。

他们经过一系列实验发现,当前已有的先进人脸识别模型和检测方法,在面对 DeepFake 时基本可以说是束手无策——性能最优的图像分类模型 VGG 和基于 Facenet 的算法,分辨真假视频错误率高达 95%;基于唇形的检测方法,也基本检测不出视频中人物说话和口型是否一致。
Pavel Korshunov 和 Sébastien Marcel 指出,随着换脸技术的不断发展,更加逼真的 DeepFake 视频,将对人脸识别技术构成更大的挑战。
“在 DeepFake 方法和检测算法之间的一场新的军备竞赛可能已经开始了。”
StyleGAN的开源,无疑也会增强DeepFake的制作。因此,谷歌大脑研究员Eric Jang呼吁,请负责任地使用!
来源:Github
评论