
文|新莓daybreak 史圣园
在电影《她》中,主人公西尔多和人工智能系统萨曼莎相恋了。她是体贴的、幽默的、忠诚的、聪慧的,无需多言,便能理解他的喜怒哀乐,恰到好处地提供情绪价值。
萨曼莎的细腻与体贴,其实源于机器学习(Machine Learning)技术:在与男主的日常沟通接触中,这些数据和反馈帮助萨曼莎变得更「懂他」。
这部 2013 年上映的电影所想象的世界,似乎即将在十年后的今天成为现实。上个月末,OpenAI 发布 ChatGPT 后,数百万网友沉迷于和这个聪慧 AI 的聊天对话中。就连马斯克都为之疯狂,称这是「思想之树」。
12 月 15 日,Science 杂志公布了 2022 年度科学突破,创造性人工智能位列其中。
过去一年,无论是 AI 作画的强势出圈,还是ChatGPT 令人惊叹的对话流畅性,都在直接告诉我们:创造、交流、思考,不再是人类独占的领域。
生成式 AI 让我们看到了新一代技术革命的可能性,但距离它们能够撑起万亿美元级别的市场,还有多远的路要走?中文世界又何时能诞生一款媲美 ChatGPT 的大模型应用?
ChatGPT ,神功初成
GPT 的全称,是「Generative Pre-Training」,翻译过来就是「生成式的预训练」。
ChatGPT,即「聊天GPT」,是 OpenAI 对 GPT-3 模型进行微调后,开发出来的聊天机器人。人们可以和它进行对话交流。
与此前不太机灵的聊天机器人前辈不同,ChatGPT 不仅上知天文下知地理,像一位博闻强识的朋友;还能够记住聊天的上下文,真正像人类一样根据语境进行交流。
这并不是说 ChatGPT 拥有了人类的思维。本质上这是一个大量语言数据训练出来的概率模型,可以根据上文提示,预测下一个单词、下一句话应该是什么。
开放使用后,用户针对 ChatGPT 生成的回答进行反馈。这些反馈对于 ChatGPT 来说是非常重要的训练数据,和萨曼莎一样,ChatGPT 也会越来越善解人意,顺应用户的期望来沟通交流。
虽然,现阶段 ChatGPT 的趣味性大过信息价值,但也有很多用户将它视为下一代生产力工具,并开发出了许多用法:学代码、写周报、编剧本、做高数……
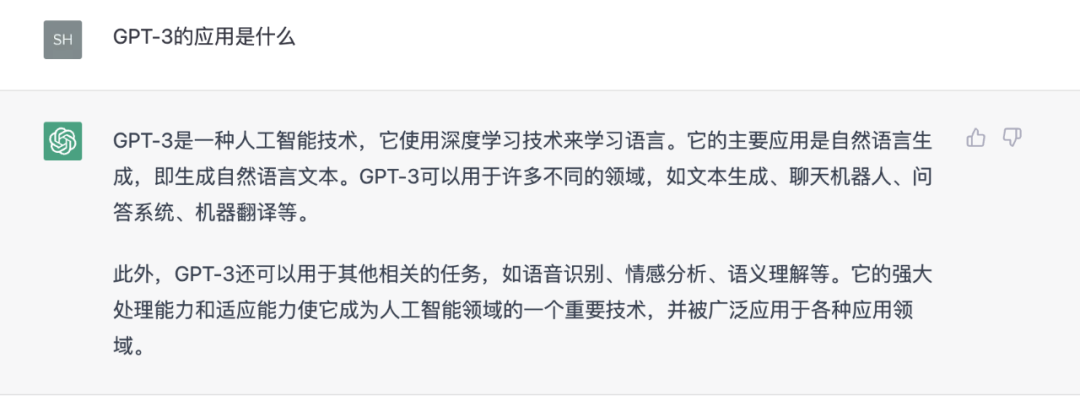
ChatGPT 有什么用?它自己的回答如下:文本生成、聊天机器人、问答系统、机器翻译。
一个名为 gpt3demo 的网站收录了使用 GPT-3 接口的所有应用,共计 432 个,包括广告生成、指导生成式AI、博客写作、文案写作、浏览器扩展、BUG核查、A/B Test、聊天机器人、健康咨询、客服、代码生成、数据集生成、设计、文件提取、图片编辑等等。
「GPT-3 是一个通用智能引擎,只要能形式化为语言的任务都可以用它来做。」复旦大学 NLP 在读博士孙天祥说。
比如写作。它不仅可以写作营销文案、周报总结,还可以模仿鲁迅、胡适创作诗歌和散文、以莫扎特的风格谱曲。虽然它写出来的文章中「废话文学」成分略高,但逻辑清晰、文辞恰当,应用在日常文档工作中基本没有违和感。
国外的效率工具们,诸如 Notion、Craft、Canva 等等,都在今年陆陆续续推出了自己的 AI 辅助写作助手。虽然他们目前使用的并非 GPT 技术,但理论上都是可以使用的。
ChatGPT 还可以写代码。
即刻网友 @机智的小榴莲 用它将 Python 重构成 Go,将一种代码快速转换为另一种代码;@Shenk 用它写了一段可执行的扫雷小游戏代码;还有很多网友把 ChatGPT 当作全知全能的助教,一边请教一边学习代码。
即刻网友 @张杰伊 则认为,ChatGPT 将编程工作变成了「写提示 - ChatGPT生成代码 - 人工运行代码 - 将报错信息粘贴给 ChatGPT - ChatGPT 改 Bug - 程序运行成功」的流程,让低代码直接变成了零代码。
再比如搜索。你可以问它红烧排骨怎么做,也可以咨询「如何举办一场成功的展览」。它几乎阅读完成了互联网所有浩瀚的信息,总共阅读并记住了 5000 亿个词,模型有 1750 亿个参数。
虽然 ChatGPT 学习了海量的互联网数据,但它暂时还无法取代搜索引擎:一是时效性不足,二是准确性无法保障。
关于时效性,ChatGPT 训练集的内容停留在 2021 年以前,对近一年来发生的事情知之甚少。胡天祥解释,「理论上是可以做到时效性的同步,把新加进来的材料继续训练就可以了,但是一般这会造成灾难性遗忘,也就是会忘记之前的部分学习材料,制约它时时更新的主要是成本」。
准确性不足,也是 ChatGPT 广为诟病的一点:它很擅长一本正经地胡说八道。
OpenAI 的 CEO,Sam Altman 表示,他们正试图阻止 ChatGPT 的随机编造,会依靠用户反馈来改进。
ChatGPT 本尊也明确提示,自己和搜索引擎有着不同的目的和功能,不能互相取代。但它的确长成了搜索引擎想要进化成的模样:进一步降低信息筛选的门槛,用户可以通过单次搜索,得到一个近乎满意的答案。
最让人惊奇的应用,是用 ChatGPT 指导 AI,用魔法驯服魔法。
随着 AI 作画的出圈,提示语生成(prompt engineering)逐渐成为一门生意。好的提示语,能够帮助人与AI 进行更高质量的对话,引导 AI 生成更符合要求的文字或图像。
初创公司 PromptBase 就提供了这样的服务交易平台,你可以花 2-5 美元购买「提示工程师」写的一串单词,复制到 AI 作画或者 GPT-3 的应用中,就能生成你期待的图像或文字。每单消费,PromptBase 会收取 20% 的佣金。
而现在,你可以让睿智的 ChatGPT 帮你写提示语了。经网友测试,它果然比人类更懂 AI,生成的提示语质量相当高。

商用,还有点难
ChatGPT 出口成章的能力让人惊叹,但在真正的商业应用前,还需要解决两个问题:张口就来的问题和运维成本。
当被问道「红楼梦中贾宝玉适合娶谁」时,ChatGPT 言之凿凿地说「贾母」;而当要求背诵观沧海时,它更是临时编造了一首诗,不打算对结果的准确性负责。
据 Twitter 网友的集体测试,ChatGPT 的错误率在 2%-5% 左右。对于一个有趣的测试版聊天机器人来说,这样的表现无疑是优秀的;但如果要应用到严肃的商业场景,例如合同、公文的写作,尤其是对于模型精度要求很高的金融行业,还需要进一步训练输出结果的稳定性。
Sam Altman 也表示,现阶段让它不要胡说八道有点难:「让它与当前技术保持平衡是很棘手的。」
他们尝试依靠用户反馈来解决这一问题。Sam Altman说,「用户的提问、对问题的反馈,都是非常重要的数据,这让 OpenAI 知道真实世界里用户的意图分布,基于这些才能让 ChatGPT 做得更好。」
不过,如果用户反馈中混杂了一定程度的错误信息,也许会使它的准确率受到影响。「比 GPT-3 小的预训练语言语言模型都会出现比较严重的偏向性,比如种族歧视、性别歧视等等,这是互联网上的数据分布造成的。」胡天祥解释道。
运行成本是另外一个难题:GPT-3 的计算成本比搜索引擎大得多。
每天,搜索引擎都要服务数十亿个搜索请求。单次计算成本即使是微小的提升,放到这个数量级上,都是相当可观的真金白银。
Sam Altman 在社交媒体上称,目前 ChatGPT 单次回答(Single Turn)的平均费用在几美分左右(约合几毛钱人民币)。虽然未来还会持续降低,但业界人士普遍认为,只有当成本缩减 90% 后,才有商业应用的经济适用性。

「不过现在看下来,他的部署速度还是挺快的了,国内部署的大模型都比它慢得多。」胡天祥认为,虽然成本的确是个制约,但其部署速度让人看到了近期商业化落地的可能性。
中国版 OpenAI 在哪里
其实,国内不是没有大厂在做类似的事。
根据公开资料,目前中国大模型参数量最大的是阿里的 M6 大模型,达到了万亿级别;百度文心、华为的盘古大模型,也有千亿的规模。
国内智源,IDEA,百度,阿里,华为,腾讯都有类似的大模型,比如 GLM,CPM,ERNIE(百度),M6(阿里),盘古(华为)等等。虽然能力尚无法与 GPT-3 比肩,但其中一部分也已经被应用在业务。只不过,它们往往被应用在内部业务中,对外的并不多,因此知名度并不高。
百度文心,是国内少数对外开放的大模型应用之一,2021 年开放给公众使用。它可以实现视频、歌词、艺术作品的自动生成,已被应用于百度内部的搜索、信息流、百度地图等产品中。
3 个月前,百度发布了 AI 助理,提供给普通用户 AI 自动生成文字、图片等功能,还提出为创作者带来一套 AI 生产内容工具,更高效的生产视频内容。这意味着,百度的 AI 产品正式开始 toC 了。
就在前几天,由百度文心续画的陆小曼未尽画稿,和海派画家续画的同名画作,共计以 110 万元的高价落槌。一方面,让人看到了 AI + 艺术的商业价值,另一方面,也能看出百度对于商业变现的迫切性。
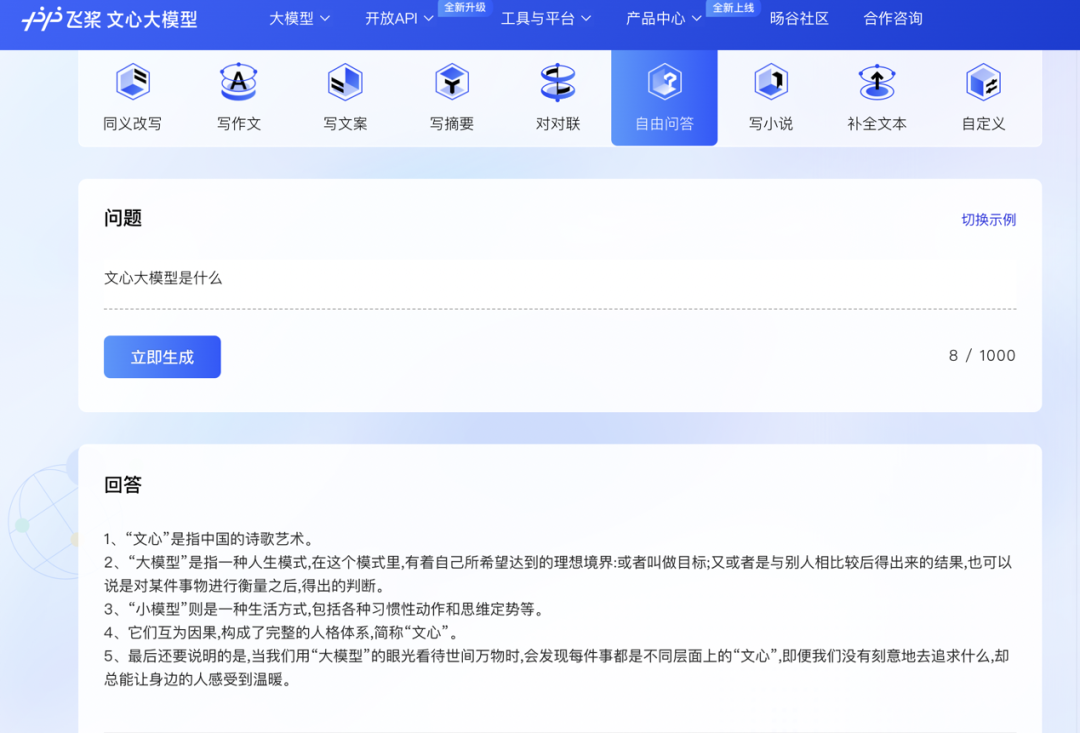
在飞桨平台上,我们也可以体验类似于 ChatGPT 的功能,但显然它的语义理解能力还有待增强。当我们问它「文心大模型是什么」时,它没能对自己进行一个流畅的自我介绍,生成的文字也显得前言不搭后语。
为什么国内的模型,在效果上无法媲美 OpenAI 呢?
一是中文领域的难度更大。「中文训练数据一来确实少,二来质量低。」胡天祥说,即使是 ChatGPT 的英文处理也显著优于中文处理。中文互联网世界里,各大 APP 相对割裂,可供 AI 训练的公共内容远不及英文素材丰富。
第二,技术的进步,需要长久而持续的投入。「OpenAI 的团队 2020 年放出 GPT-3 后就一直在维护和更新,不断收集用户反馈和真实的数据,慢慢形成了数据壁垒。」
千亿级别的大模型,显卡的算力成本需要在千张以上。像 GPT 这样拥有 1750 亿参数的大模型,运算一次要花 450 万美金,跟发射一个卫星的成本差不多。商业前景不明朗,又需要不计成本的投入,对大厂来说这不划算。
另一方面,国内大厂的科研团队隶属于公司,节奏紧张,很难避免商业变现的压力;而 OpenAI 自成立之初,便将自己定位为「非营利组织」,更类似于研究院的性质,招徕顶尖的科研人才。当然,微软的投资给了 OpenAI 烧钱做研究的底气。
值得注意的是,OpenAI 发布的关于 ChatGPT 的论文中,共有 8 位主要作者,其中 3 位的姓名是中文拼音。他们或许来自中国,或许是华裔。而网络领域顶会(SIGCOMM)的期刊中,每年都会收录几篇来自于阿里、华为等公司的研究论文。这说明国内 AI 领域,不缺乏优秀的基础研究者。
我们缺乏的,可能是耐心。中金基金的研究报告中曾写道,「实力雄厚的美国互联网巨头对 AI 底层技术战略性投入力度较大,但中国的 AI 产业主要受需求拉动,大多数 AI 公司布局应用层。」
好消息是,ChatGPT 的成功出圈,让资本和业界都看到了它不可估量的商业潜力。
2022 年被很多人称为「AIGC 元年」,此前默默无闻的大模型赛道,今年融资也多了起来,单笔融资金额高达 10 亿元,联想创投、创新工场等知名投资机构均参与其中。
这意味着,会有更多初创公司加入这场需要耐心和毅力的长跑。与大厂不同,它们或许能以更聚焦的技术输出全情投入,为中文世界的生成式 AI 积累点滴珍贵的创新。
评论