
文 | 智东西 ZeR0
编辑 | 漠影
智东西2月1日报道,今日,美国AI初创公司OpenAI宣布推出一个AI文本分类器,用于辅助辨别文本是由人类还是AI(人工智能)编写的。
这款AI工具可免费试用。用户将待检测文本复制到文本框中,点击Submit,系统就会评估该文本由AI系统生成的可能性,给出评估结果。
评估结果分成5类:非常不可能、不太可能、不清楚、可能、非常可能是AI生成。

目前试用这款AI文本分类器有一些限制,要求至少1000个字符,大约150-250个单词。
该工具在检测大于1000个字符的英文文本时效果更好,在检测其他语言时的表现要差得多,而且无法辨别计算机代码是由人类还是AI写的。
AI文本分类器直通门:https://platform.openai.com/ai-text-classifier
01.针对AI滥用风险,打造“克星”工具
AI文本分类器意在解决ChatGPT爆红之后引发的争议。
OpenAI在去年11月推出的ChatGPT聊天机器人,不仅能准确回答专业问题,还能撰写诗词歌赋、广告文案、散文小说、电影剧本、编程代码等各类文本,大受使用者的称赞追捧。
但随着使用者越来越多,ChatGPT的问题也很快暴露出来。一方面是它本身的局限性,例如素材来源可能涉及抄袭、侵权,或者有时会写出看似正确实则错误的文本;另一方面是滥用风险,例如有些人会用AI工具作弊、散播虚假信息等。
为了缓解这些问题,OpenAI打造了一个全新的AI文本分类器。
这是一个GPT语言模型,对从各种来源收集的同一主题的人类编写文本和AI编写文本的数据集进行了微调,使用了来自5个不同组织的34个模型生成的文本,以检测该文本由AI生成的可能性。
人类编写文本的数据集来自三个来源:一个新的维基百科数据集、2019年收集的WebText数据集、一组作为训练InstructGPT的一部分收集的人类演示。
OpenAI将每个文本分成了“提示(prompt)”和“回复(response)”,根据这些提示,从OpenAI和其他组织训练的各种不同的语言模型中生成了回复。对于Web应用程序,OpenAI调整了置信度阈值,以保持低误报率;换句话说,只有当分类器非常有信心时,它才会将文本标记为可能是AI编写的。
OpenAI也贴心地为试用者备好了引用这款AI文本分类器的BibTex格式。

02.1秒给出分类结果,但偶尔错把人类当AI
我们分别用几段ChatGPT生成文本、几段外媒新闻报道内容,测了测AI文本分类器的表现。
首先,让ChatGPT就中美前沿人工智能研究的不同之处分析了一通。

▲ChatGPT针对“中美前沿AI研究有哪些不同”问题的回答
接着将这些文字复制粘贴到分类器的文本框中。
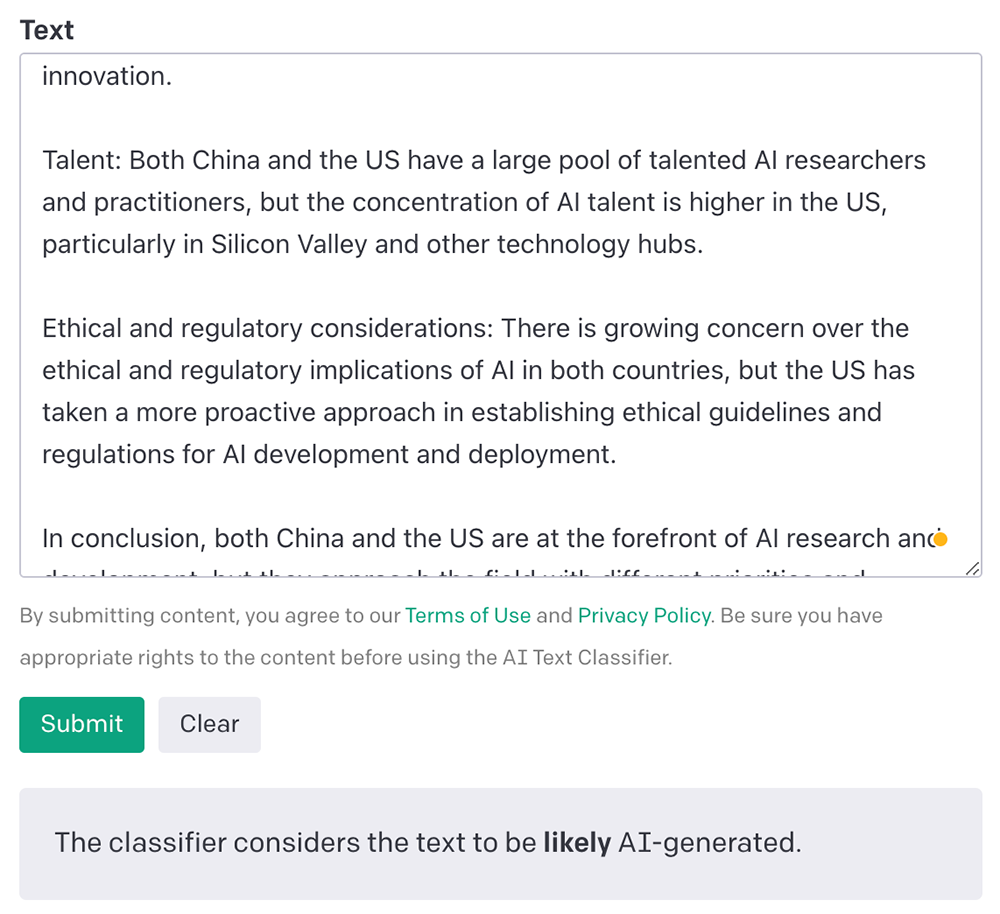
▲AI文本分类器秒出判断
结果,AI文本分类器1秒判断出这非常可能是AI生成的(likely AI-generated)。
换几段由人类写的分析生成式AI风险的内容:
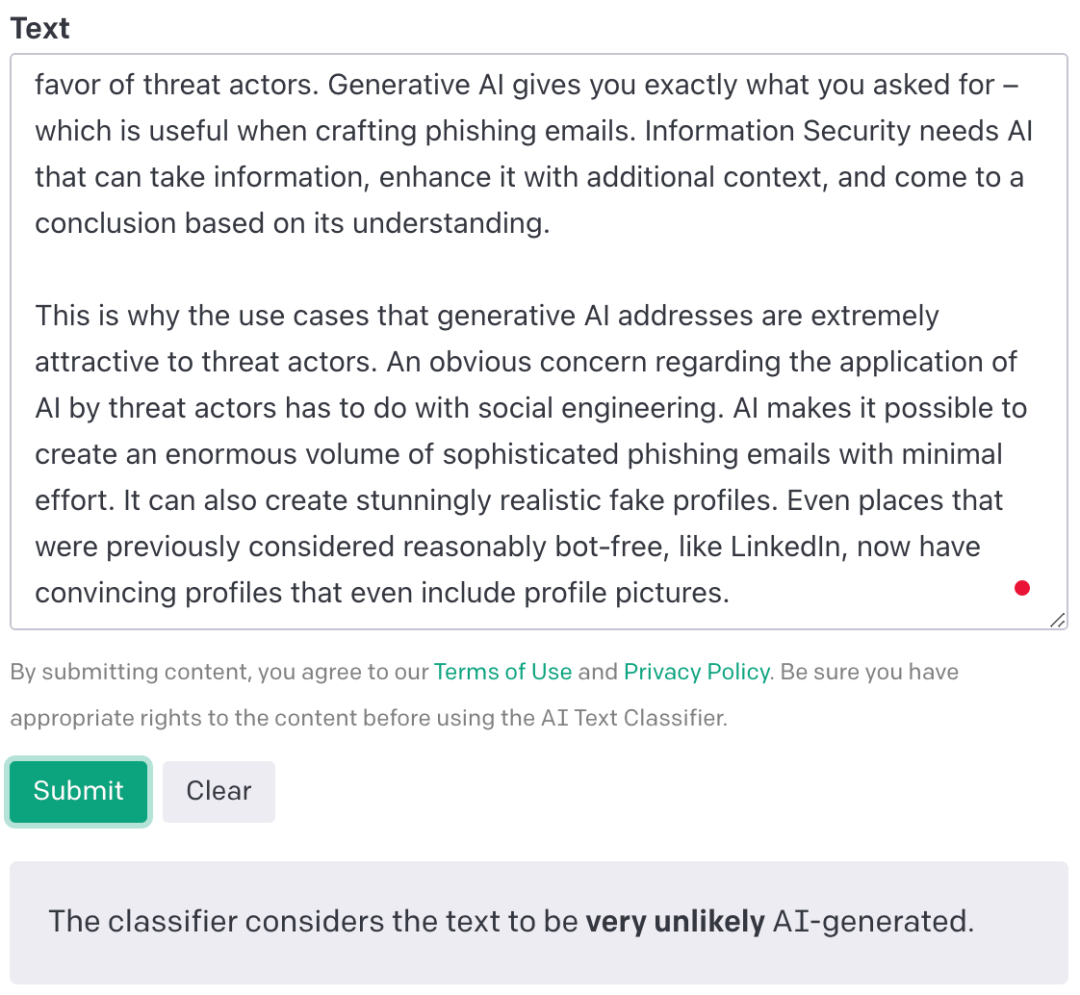
▲AI分类器很快给出评估结果
AI文本分类器这次花得时间略长,2秒给出结果:非常不可能是AI生成的(very unlikely AI-generated)。评估结果依然准确。
不过,再提升点难度,分类器就不太灵了。
知名AI研究人员Sebastian Raschka用莎士比亚《麦克白》第一页的内容做测试,发现AI文本分类器误判为“很可能是AI生成的(likely AI-generated)”。
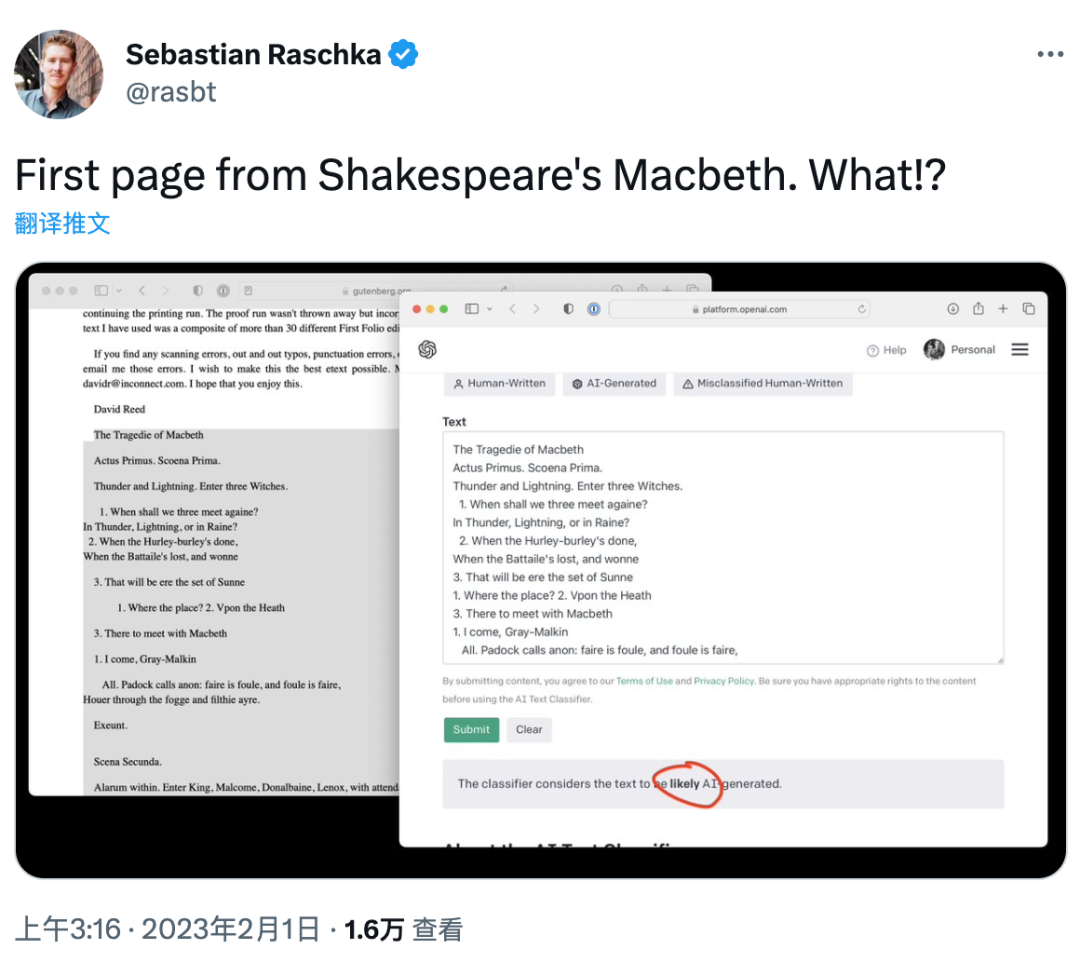
看来在AI文本分类器眼中,莎士比亚已经走在了时代的前面。
Sebastian Raschka还从自己在2015年出版的Python ML书摘录了好几段,AI文本分类器的识别也不是很准,Randy Olson的前言部分被识别成“不清楚是否由AI生成”,他自己写的前言部分被识别成“可能是AI生成的”,第一章部分被识别成“很可能是AI生成的”。
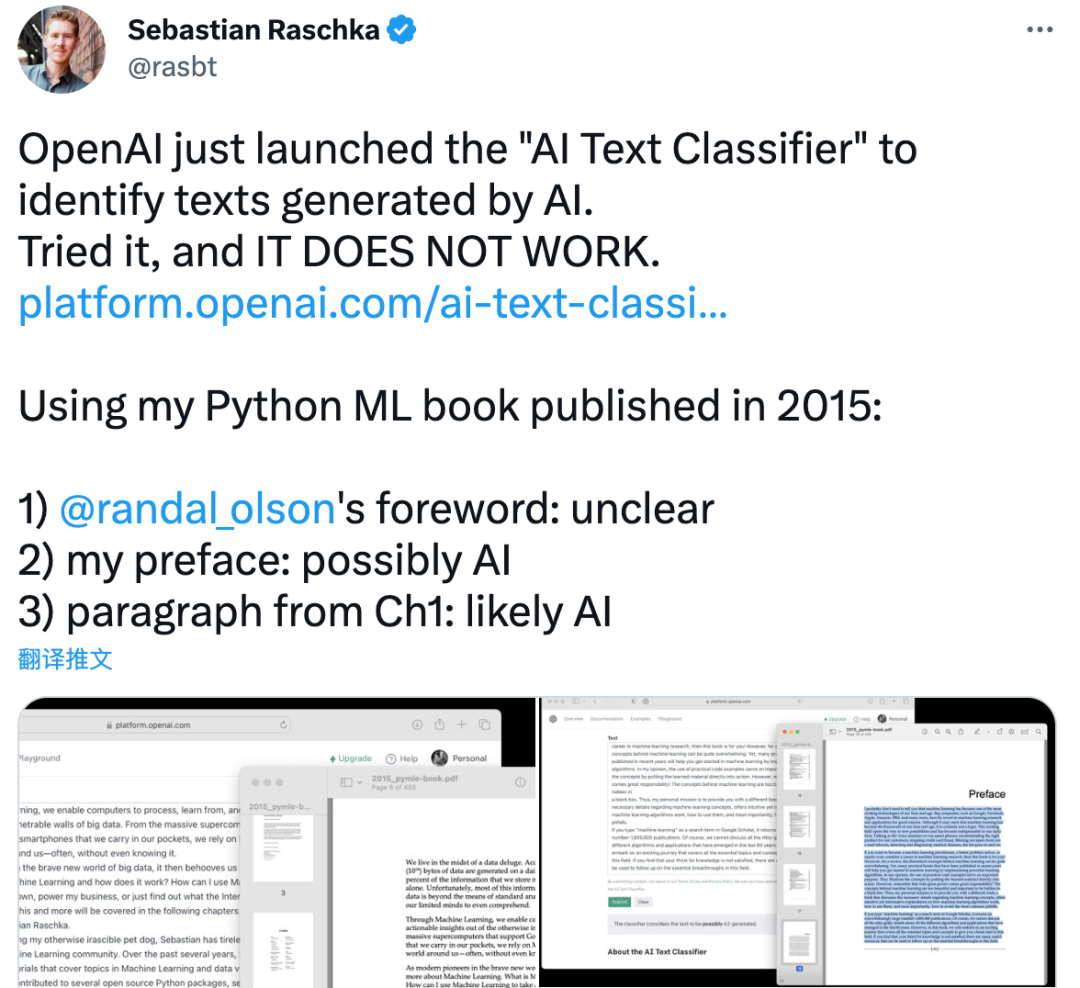
看到一系列令人啼笑皆非的测试结果后,他评价说:“在ChatGPT让你的作业变得更简单之后,它现在比以前更难了。现在,你必须多次修改自己的措辞,直到它们看起来不再是AI生成的,然后才能提交。”
03.识别正确率仅26%,AI文本分类器还有很多局限性
OpenAI在与训练集分布相同的验证集和挑战集上评估了其AI文本分类器和之前发布的分类器,挑战集由人类编写的补全(completions)和来自在人类补全上训练的强语言模型的补全组成。
结果显示,与OpenAI之前发布的分类器相比,全新AI文本分类器的可靠性要高得多,在验证集上的AUC得分为0.97,在挑战集上为0.66(OpenAI之前发布的分类器在验证集上为0.95,在挑战集上为0.43)。分类器可靠性通常随着输入文本长度的增加而提高。
OpenAI还发现,随着生成文本模型大小的增加,分类器的性能会下降。
换句话说,随着语言模型规模变大,它的输出对AI文本分类器来说更像人类编写的文本。
OpenAI在博客中坦言其分类器“不完全可靠”,比如在低于1000个字符的短文本上非常不可靠,即使是较长的文本有时也会被错误标记,有时人类书写的文本也会被错判成AI编写的文本。
在对英语文本“挑战集”的评估中,该分类器正确地将26%的AI创作文本识别为“可能是AI编写的”,而在9%的时间内错误地将人类创作文本标记为AI编写。
OpenAI建议只对英文文本使用该AI文本分类器,因为它在其他语言中的表现要差得多,而且在代码上不可靠。此外,它也很难识别有标准正确答案的文本,例如你很难判断“1+1=2”是人类还是AI写的。AI文本分类器很可能在儿童编写的文本和非英语文本上出错,因为它主要是在成人编写的英语内容上进行训练。
AI书写的文本可以通过编辑来逃开分类器的检测。OpenAI分类器可根据成功的攻击进行更新和重新训练,但还不清楚从长期来看检测是否具有优势。
OpenAI也提醒道,基于神经网络的分类器在训练数据之外的校准很差。对于与训练集中的文本有很大不同的输入,分类器有时可能对错误的预测非常有信心。
04.结语:着重解决ChatGPT在教育领域构成的风险
由于上述局限性,OpenAI建议在确定内容来源的调查中只使用分类器作为众多因素中的一个,并对AI产生的虚假信息行为的风险、对大型语言模型在教育领域构成的风险进行研究。
OpenAI正与美国教育工作者合作,讨论ChatGPT的能力和局限性,并为教育工作者开发了一个关于使用ChatGPT的初步资源,其中概述了一些用途以及相关的限制和考虑因素。
资源链接:
https://platform.openai.com/docs/chatgpt-education
通过将AI文本分类器公开,OpenAI希望从使用者那里获得更多有价值的反馈,以进一步改进OpenAI在检测AI生成文本方面的工作。
评论