
编译|智东西 程茜
编辑|心缘
智东西2月25日报道,围绕生成式AI的前沿技术竞争愈发胶着。就在昨晚,Meta突然公布了一款全新的AI大型语言模型LLaMA,宣称可帮助研究人员降低生成式AI工具可能带来的“偏见、有毒评论、产生错误信息的可能性”等问题。
此前在最新季度财报电话会议中,Meta CEO扎克伯格提到“生成式AI”的次数比“元宇宙”还要多。如今,Meta带来了一个利好研究学者的AI重磅成果——仅用约1/10的参数规模,实现了匹敌OpenAI GPT-3、DeepMind Chinchilla、谷歌PaLM等主流大模型的性能表现。

Meta介绍LLaMA论文
Meta目前提供有70亿、130亿、330亿和650亿四种参数规模的LLaMA模型。
根据论文,在一些基准测试中,仅有130亿参数的LLaMA模型,性能表现超过了拥有1750亿参数的GPT-3,而且能跑在单个GPU上;拥有650亿参数的LLaMA模型,能够跟拥有700亿参数的Chinchilla、拥有5400亿参数的PaLM“竞争”。
要知道,GPT-3是AI聊天机器人ChatGPT背后大模型GPT-3.5的前代,GPT-3.5的参数量也高达1750亿;而谷歌驱动对话式AI应用Bard进行搜索查询的模型,参数量比5400亿还要多。
这是大模型研究迈出的重要一步!随着技术持续优化,未来有朝一日,你也许能在自己的笔记本电脑乃至手机上跑类ChatGPT功能的语言模型。
扎克伯格说,LLaMA“在生成文本、进行对话、总结书面材料以及解决数学定理或预测蛋白质结构等更复杂的任务方面表现出了很大的潜力”。
扎克伯格Facebook贴文
值得一提的是,Meta宣布LLaMA基础大型语言模型“开源”,不作商用目的,免费供给研究人员。目前Meta在GitHub上提供了精简版LLaMA。
01 拥有70-650亿参数,20种语言训练
LLaMA作为一种基础大型语言模型,相比于GPT-3等模型,其可以让开发人员使用更少的计算能力和资源来进行测试。
目前,科技巨头玩家在大型语言模型领域开展军备竞赛,并且有多个成果面世。但研发人员在运行此类大模型时往往需要大量的资源投入,导致部分开发人员并不能全面研究访问这些模型。
而这种限制就会阻碍人员去理解这些模型的工作模式和功能,并且使得他们在调整模型的偏见、发生错误的可能性上会较为困难。
作为一个基础模型,LLaMA不是为特定任务而设计,Meta研究人员通过标记一些Tokens等来训练基础模型,其优势在于更容易针对特定潜在产品应用进行再训练和微调。
不同于Chinchilla、PaLM、GPT-3等大模型,LLaMA只使用公开可用的数据集进行训练,其中包括开放数据平台Common Crawl、英文文档数据集C4、代码平台GitHub、维基百科、论文预印本平台ArXiv等。项目成员称,这是为了使其工作与开源兼容和可复现。
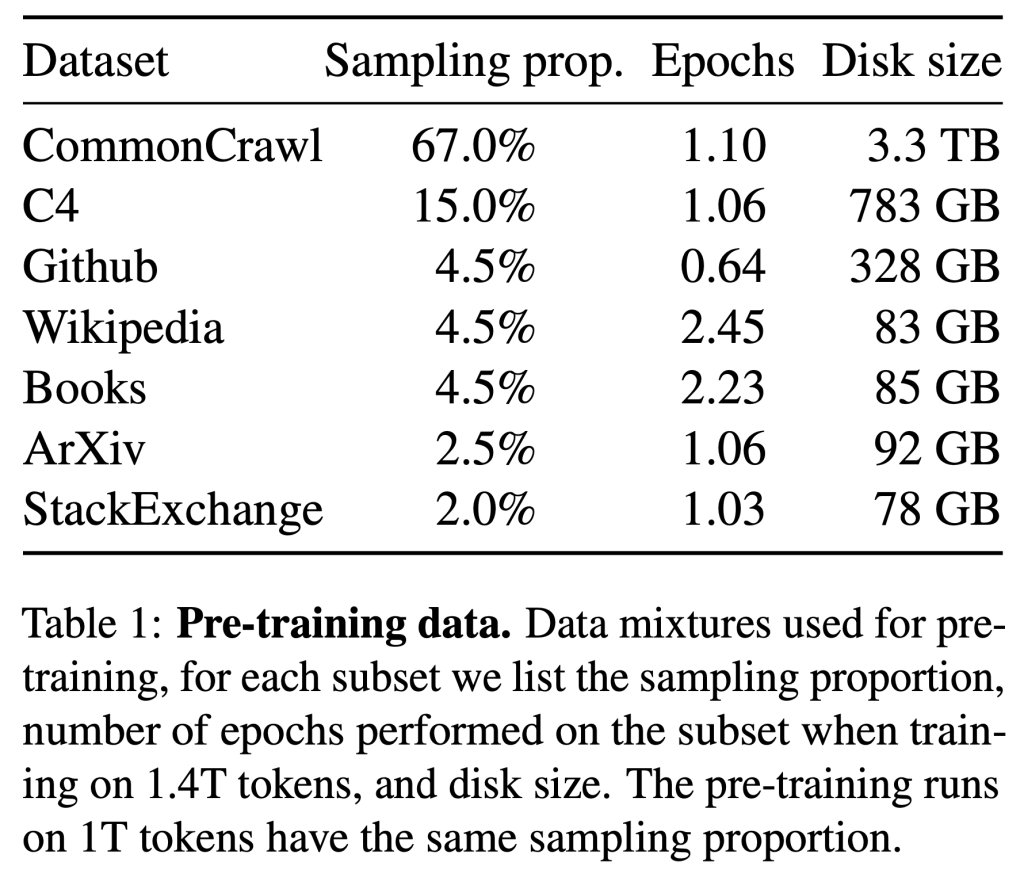
总体来看,整个训练数据集在标记化后大约包含1.4万亿个Tokens。
其中,拥有650亿参数的LLaMA和拥有330亿参数的LLaMA使用1.4万亿Tokens进行训练,最小的拥有70亿参数的LLaMA在1万亿Tokens上进行了训练。
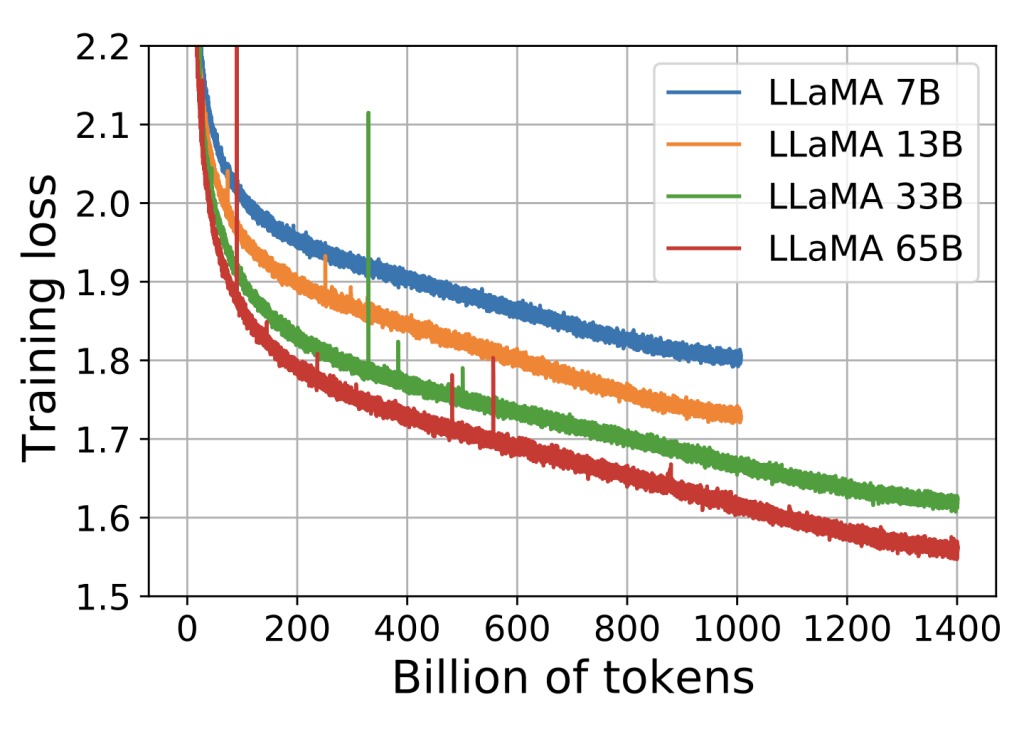
拥有不同参数的模型与训练损失的关系图
与其他大型语言模型一样,LLaMA的工作原理是将一系列Tokens作为输入,并预测下一个单词以递归生成文本,Meta使用了20种语言对其进行训练。
此外,大型语言模型中还可能会遇到生成偏见、不良信息、不实信息的风险,基于共享LLaMA的代码,其他开发人员可以测试限制或消除大型语言模型中这些问题的方法。
02 7项AI能力,不输业界主流大模型
在测试过程中,研究人员采用0-shot和1-shot、5-shot、64-shot几种方式,将LLaMA与GPT-3、Gopher、Chinchilla等模型进行了比较。
尤其值得一提的是,130亿参数LLaMA模型在单个GPU上运行时,性能表现可能超过1750亿参数GPT-3。这也许会给类ChatGPT产品跑在消费级硬件上打开新的大门。
1、常识推理(Common Sense Reasoning)
LLaMA涵盖了八个标准常识性数据基准,包括BoolQ、PIQA等。这些数据集包括完形填空、多项选择题和问答等。
结果显示,拥有650亿参数的LLaMA在BoolQ以外的所有报告基准上均超过拥有700亿参数的Chinchilla。同时,除BoolQ和WinoGrande外,该模型测试中均超过拥有5400亿参数的PaLM。
拥有130亿参数的LLaMA模型在大多数基准测试上也优于拥有1750亿参数的GPT-3。
2、闭卷问答(Closed-book Question Answering)
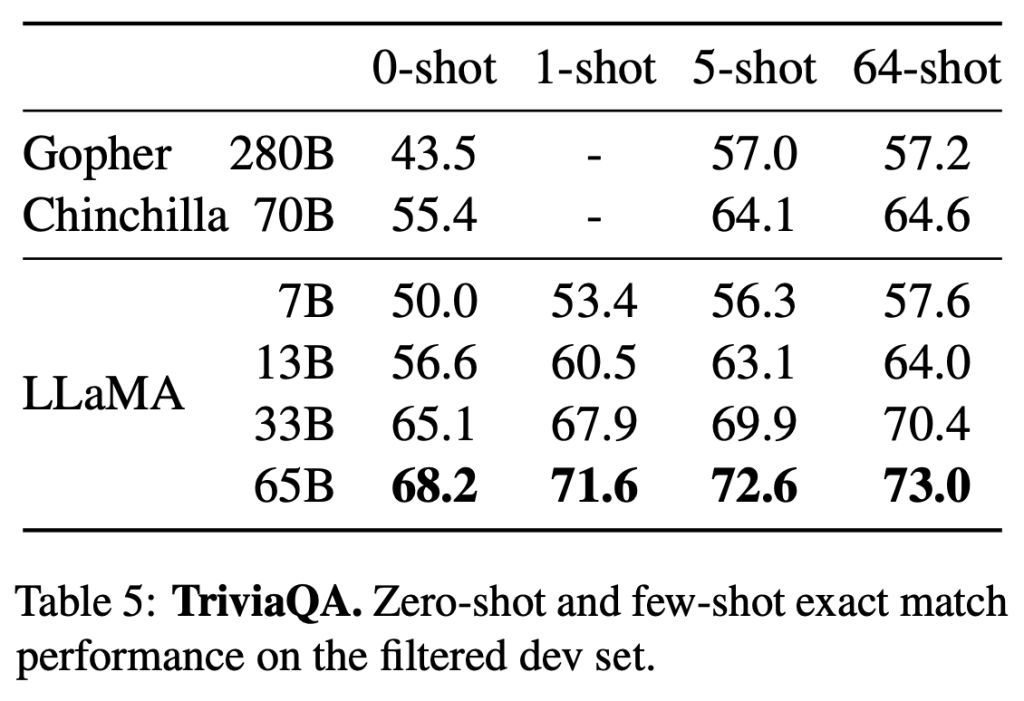
研究人员就闭卷答疑对LLaMA进行了测试,该基准测试的数据集包含阅读理解与问答的大规模语料集TriviaQA以及自然问题。
拥有650亿参数的LLaMA在0-shot和1-shot条件下,实现了较好的性能。
在推理过程中,拥有130亿参数的LLaMA在一个V100 GPU上运行,其基准测试结果显示,与GPT-3和Chinchilla不相上下。
3、阅读理解(Reading Comprehension)
在阅读理解能力方面,LLaMA通过大型深层阅读理解任务数据集RACE评估,拥有650亿参数的LLaMA与拥有5400亿参数的PaLM相差并不大。
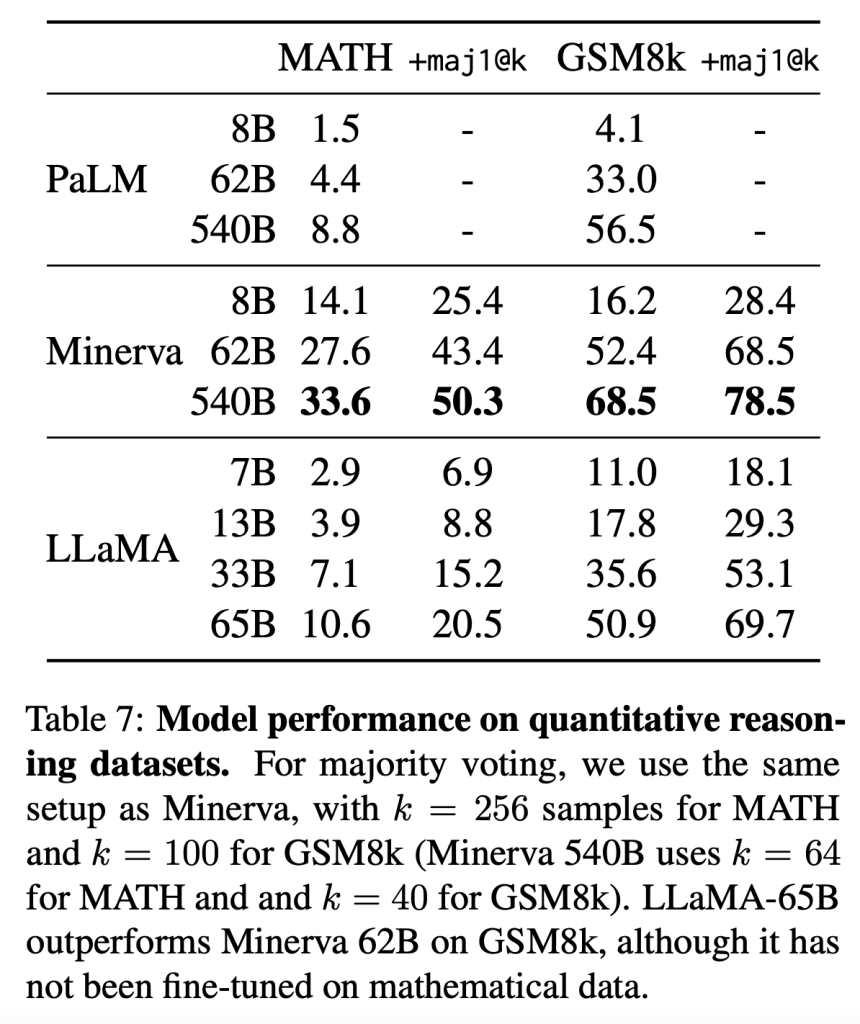
4、数学推理(Mathematical reasoning)
研究人员根据两个数学基准评估LLaMA模型,分别是包含中学和高中数学问题的数据集MATH、OpenAI发布的小学数学题数据集GSM8k。
其比较模型对象是,从ArXiv和Math Web Pages提取的拥有385亿数据进行微调的PaLM模型Minerva。
结果显示,在GSM8k上,拥有650亿参数的LLaMA优于拥有620亿参数的Minerva。
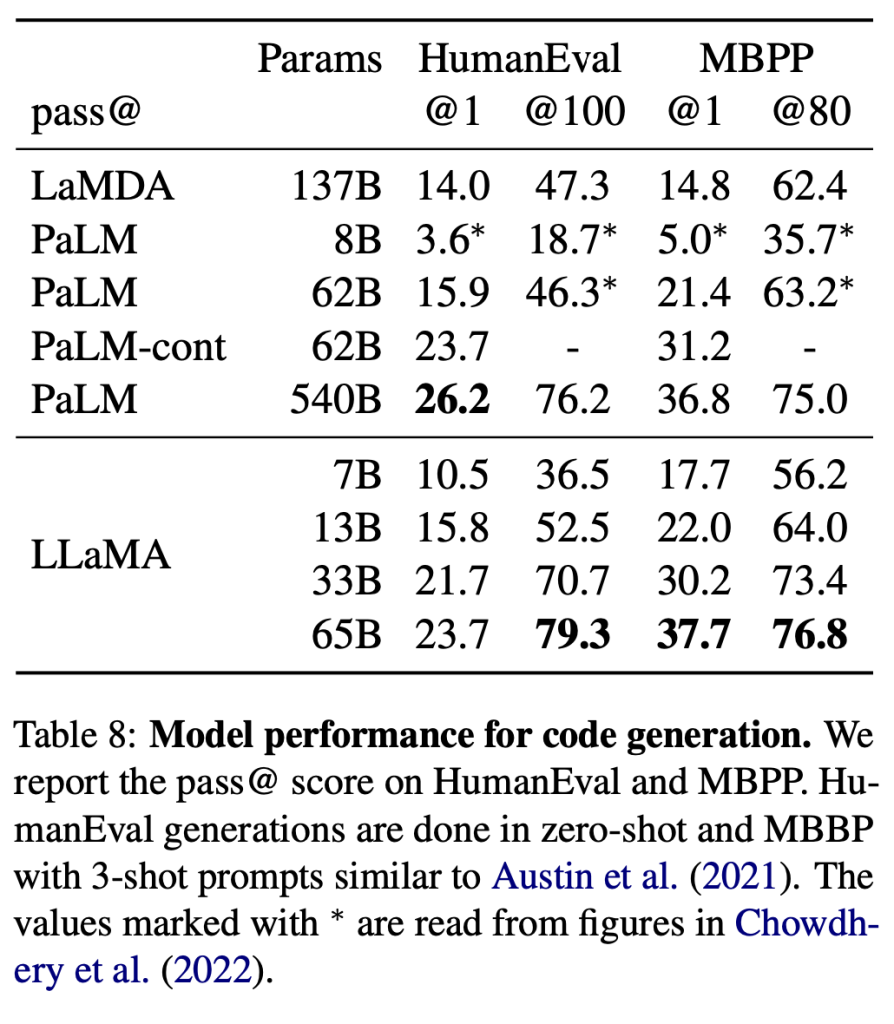
5、代码生成(Code generation)
基于编程代码开源数据集HumanEval和小型数据集MBPP,被评估的模型将会收到几个句子中的程序描述以及输入输出实例,然后生成一个符合描述并能够完成测试的Python程序。
对于拥有相似参数的模型,LLaMA优于其他通用模型。
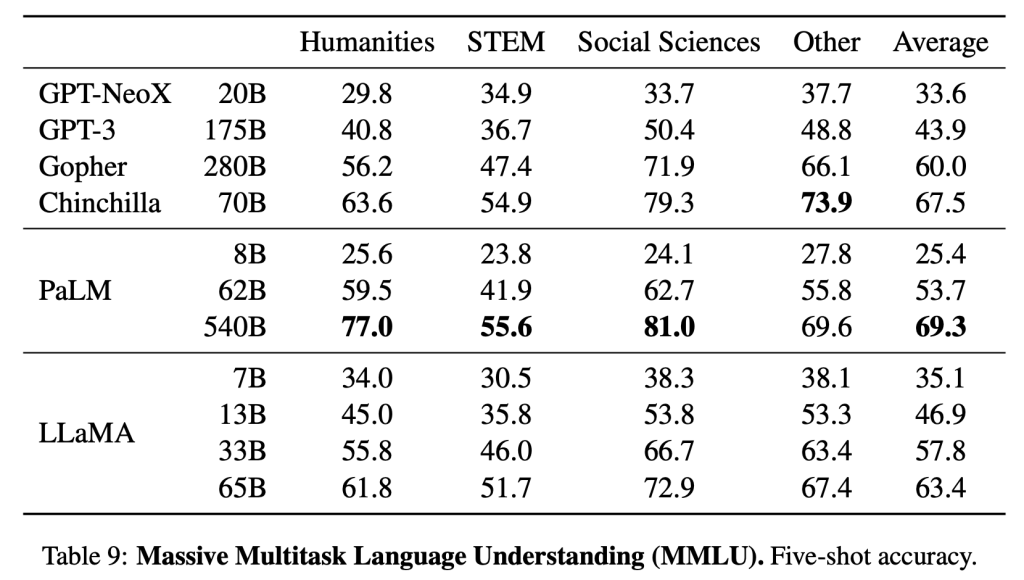
6、大规模多任务语言理解(Massive Multitask LanguageUnderstanding)
这一数据集基准涵盖人文科学、STEM、社会科学等各种知识领域的多项选择题。
经比较,研究人员发现,拥有650亿参数的LLaMA在大多数领域平均落后于拥有700亿参数的Chinchilla和拥有5400亿参数的PaLM几个百分点。
研究人员猜测,其中一个可能的原因是,他们在训练前使用的数据集较为有限,包括177GB大小的ArXiv、Gutenberg和Books3,而其余模型的训练数据足有2TB大小。
7、训练期间的能力进化(Evolution of performance during training)
在训练过程中,研发人员跟踪了LLaMA在一些问题回答和常识性基准上的表现,其都保持稳步提高。
不过针对于相关数据集的评估,研究人员认为其存在许多性能差异,该基准的结果并不可靠。
03 去年曾发布Galactica大模型但因偏见和造假火速下架
关于大模型的研究如今在AI领域十分火热。其基本原理就是通过获取新闻、社交媒体或其他互联网资源上的文本,来训练软件,使得基于大模型生成的产品可以在用户给出提示或查询搜索时自行预测和生成内容,其目前最直观的例子就是最近爆火的聊天机器人ChatGPT。
也正由于这一现象级消费级应用的推动,使得科技巨头开始构建基于大模型的产品测试,并将生成式AI视作新竞争领域。
年初,微软向聊天机器人ChatGPT的创造者OpenAI投资了数十亿美元,随后,微软推出了其ChatGPT版新Bing搜索引擎。谷歌很快也加入竞赛,该公司基于其大型语言LaMDA推出类似的对话式AI应用程序Bard。
去年5月,Meta也曾发布了拥有1750亿参数的OPT大型语言模型,这一模型的适用对象也是开发人员,是生成其聊天机器人BlenderBot的基础模型。半年后,Meta推出名为Galactica的语言模型,该模型可以撰写科学文章并解决数学问题,但在推出三天后,这一模型就因经常胡言乱语以及给出虚假信息被撤下。
国外投资机构DA Davidson高级软件分析师Gil Luria认为:“Meta今天的公告似乎是测试他们生成式AI能力的一步,这样他们就可以在未来将它们应用到产品中。”
他还补充道:“生成式AI作为AI的一种新应用,Meta对此经验较少,但显然对其未来的业务很重要。”
04 结语:生成式AI竞赛不断升温
大型语言模型已经在生成创意文本、解决数学问题、预测蛋白质结构、回答阅读理解问题等方面展示出了巨大的潜力,如今ChatGPT的发布使得其在消费级应用市场中爆发。
继微软、谷歌之后,Meta也试图在这一领域展现自己的技术优势。
在科技大厂纷纷亮出生成式AI商用计划之时,Meta难得地聚焦在研究贡献上,无论是用更多数据训练出的更少参数规模模型实现优于更大参数规模模型的研究成果,还是将LLaMA模型和权重开源开放,都令人感到耳目一新。
但也由于仅限于研究用途,这可能导致Meta短期内难以在生成式AI领域形成像OpenAI、谷歌那样的影响力。
评论