

文|Edu指南
3月15日 OpenAI 周二发布多模态大语言模型GPT-4,该模型是OpenAI 在调用和响应深度学习模型制作方面的最新里程碑,并且在重要考试中胜过其大多数人类考生。
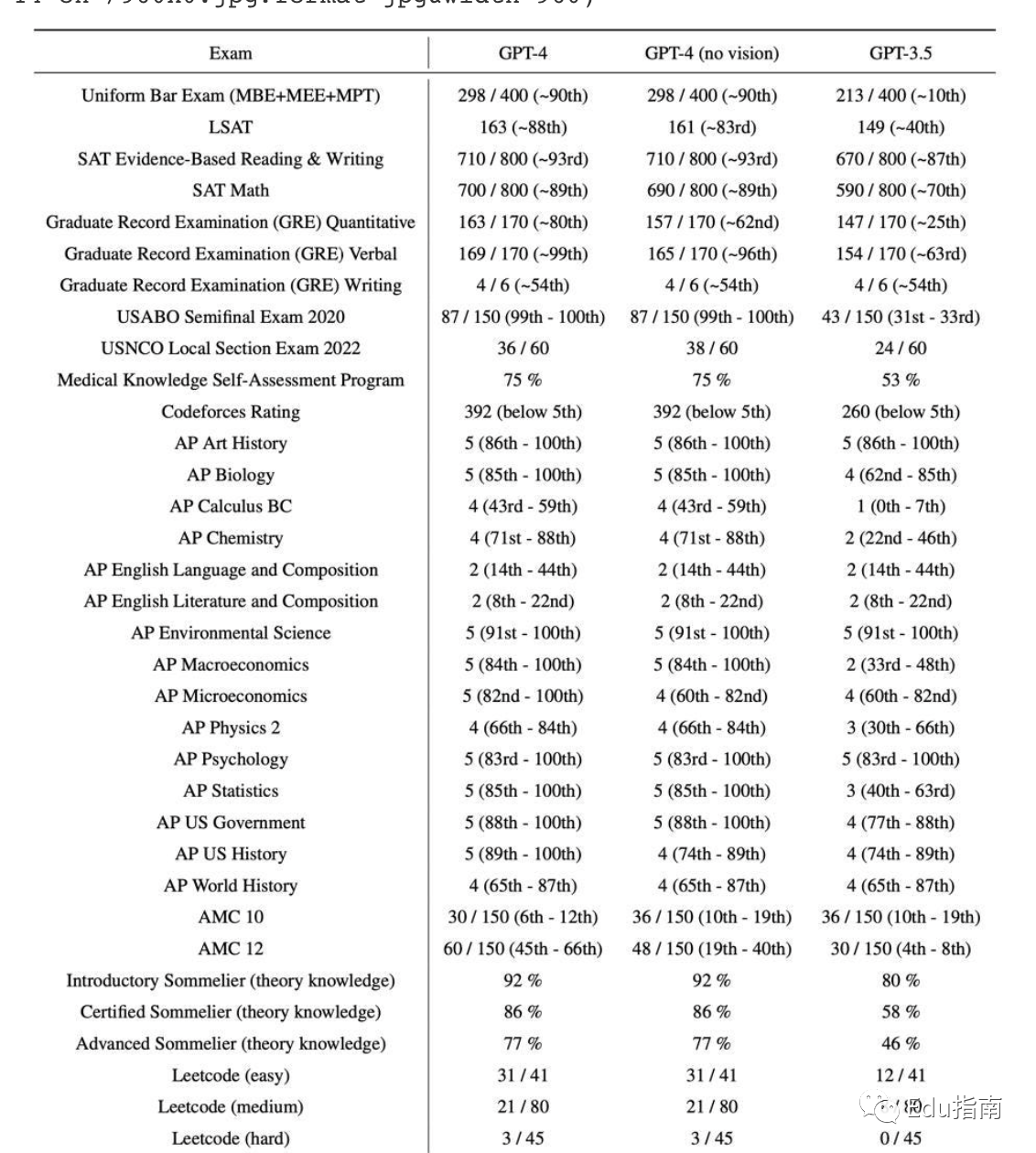
根据 OpenAI 的描述,该模型展示了“在各种专业和学术领域对标人类水平的表现”。GPT-4 在模拟律师考试中获得了前10%的成绩,而其前身 GPT-3.5(ChatGPT 的基础)得分排位在后 10% 左右。
GPT-4 在其他各种考试中也表现出色,例如美国高校入学考试 SAT 数学考试,其获得了800 分中的 700 分成绩。然而,它暂时并不具备所有学科能力,例如在AP英语语言和作文中仅获得 2 分。
需要考虑的一件事:OpenAI 的 GPT 系列本质上是一个反流引擎系列,利用它训练的材料并重新组装它来解决用户的查询。有时是对的,有时是错的。它可以回忆考试的细节——而人类用户可能很难对所有细节都记得清清楚楚,它的回复可能更像是对人类必须参加的各类考试的评论。
OpenAI 首席执行官山姆奥特曼Sam Altman在谈到 GPT-4 时承认:“它仍然存在缺陷,仍然有限,而且在第一次使用时可能让人印象深刻,但当人们花更多时间使用后可能做不到这个程度(即多轮对话查询后得到的回应可能出现缺陷)。”

GPT-4 是一个大型多模态模型,它支持通过文本和图像输入查询,并以文本形式返回答案。当前开发者可以通过列入候补名单的 GPT-4 API 等待使用,而个人用户通过 ChatGPT Plus 订阅使用。当前基于图像的输入仍在完善中。
尽管增加了图像输入机制,但 OpenAI 并未公开或提供对其模型制作的相关信息。这家备受关注的公司选择不公布有关其规模、训练方式以及流程中包含哪些数据的详细信息。
“鉴于竞争格局和 GPT-4 等大型模型的安全影响,本报告不包含有关架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法或类似内容的更多详细信息,”该公司在其技术论文中表示。
在YouTube 上的直播中,OpenAI 总裁兼联合创始人 Greg Brockman 通过要求各模型用一句话概括OpenAI GPT-4博客文章,每个词语都以字母“G”开头,以此证明GPT-4和GPT-3.5之间的区别。
GPT-3.5 根本就没有尝试回应。GPT 4 返回“GPT-4 产生了突破性的、巨大的收益,极大地激发了广义的 AI 目标(GPT-4 generates ground-breaking, grandiose gains, greatly galvanizing generalized AI goals)" 。” 当 Brockman 告诉模型,句子中包含“AI”不算数时,GPT-4 在另一个没有“AI”的句子中修改了它的回应。
然后他继续让 GPT-4 为 Discord 机器人生成 Python 代码。更令人印象深刻的是,他拍了一张笑话网站的手绘模型照片,将图像发送到 Discord,关联的 GPT-4 模型以 HTML 和 JavaScript 代码响应,实现了模型网站。
最后,Brockman 设置 GPT-4 来分析 16 页美国税法,以返回具有特定财务状况的夫妇 Alice 和 Bob 的标准扣除额。OpenAI 的模型给出了正确答案,并解释了所涉及的计算。
除了更好的推理,从其改进的测试分数中可以明显看出,GPT-4 提高了协作性(按照指示迭代以改进以前的输出),能够更好地处理大量文本(分析或输出大约 25,000 个单词的中篇小说) ,以及接受基于图像的输入(用于对象识别,尽管该功能尚未公开)。
更重要的是,根据 OpenAI 的说法,GPT-4 应该比其更早版本更不容易犯错。
“我们花了六个月的时间使用我们的对抗性测试程序和 ChatGPT 的经验教训迭代调整 GPT-4,从而在真实性、可控性和拒绝超出安全范围方面取得了有史以来最好的结果(尽管远非完美) ”,OpenAI表示。
人们可能已经从微软 Bing 问答功能首次亮相时就熟悉过这种“远非完美”的安全级别,事实证明它使用了 GPT-4作为其 Prometheus 模型的基础。
OpenAI 承认 GPT-4 像它早前版本一样会出现“扭曲事实并犯推理错误”,但该公司称新模型降低了犯错程度。
GPT-4 相对于以前的模型显著减少了事实歪曲
“虽然仍然是一个真正的问题,但 GPT-4相对于以前模型更少出现事实歪曲的表现(这些模型本身在每次迭代中都在改进),”该公司解释说。“在我们内部的对抗性真实性评估中,GPT-4 的得分比我们最新的 GPT-3.5 高 40%。”
GPT-4 的定价是每 1000个提示token 0.03 美元和每 1000个完成token 0.06 美元,其中一个token大约是四个字符。还有一个默认速率限制为每分钟 40,000 个token和每分钟 200 个请求。
此外,OpenAI 开源了Evals,这是一个用于评估和校对测试机器学习模型(包括它自己的模型)的程序。
尽管人工智能风险的担忧一直都在,但企业急于将人工智能模型推向市场。在 GPT-4 到来的同一天,由前 OpenAI 员工组建的初创公司 Anthropic推出了自己的基于聊天的助手 Claude,用于处理和生成文本摘要、搜索、问答、编程等。
谷歌担心在相关模型的营销方面落后,因此推出了一个名为PaLM 的 API,用于与各种大型语言模型和一个名为 MakerSuite 的原型环境进行交互。
几周前,Facebook 推出了LLaMA 大型语言模型,斯坦福大学的研究人员现已将其转变为Alpaca 模型,未来或将有更广泛的竞争。
“还有很多工作要做,我们期待通过社区在模型之上构建、探索和贡献的集体努力来改进这个模型,”OpenAI 表示。
参阅
https://openai.com/research/gpt-4
https://www.theregister.com/2023/03/14/openai_gpt4_ai/
评论