

文|半导体产业纵横
ChatGPT已经从下游AI应用火到了上游芯片领域,在将GPU等AI芯片推向高峰的同时,也极大带动了市场对新一代内存芯片HBM(高带宽内存)的需求。据悉,2023年开年以来,三星、SK海力士的HBM订单就快速增加,价格也水涨船高。有市场人士透露,近期HBM3规格DRAM价格上涨了5倍。
HBM(High Bandwidth Memory,高带宽内存)是一款新型的CPU/GPU 内存芯片,其实就是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。
内存市场自去年下半年已经开始进入寒冬,HBM为何依旧火热呢?
01、需求所致
长期以来,内存行业的价值主张在很大程度上始终以系统级需求为导向,已经突破了系统性能的当前极限。很明显的一点是,内存性能的提升将出现拐点,因为越来越多人开始质疑是否能一直通过内存级的取舍(如功耗、散热、占板空间等)来提高系统性能。相较于传统 DRAM,HBM 在数据处理速度和性能方面都具有显著优势,有望获得业界广泛关注并被越来越多地采用。

随着集成电路工艺技术的发展,3D和2.5D系统级封装(SiP)和硅通孔(TSV)技术日益成熟,为研制高带宽、大容量的存储器产品提供了基础。针对内存高带宽、大容量、低功耗的需求,从2013年开始,国际电子元件工业联合会(JEDEC)先后制定了3代、多个系列版本的高带宽存储器(HBM、HBM2、HBM2E、HBM3)标准。2022年1月28日,JEDEC正式发布了JESD238 HBM DRAM(HBM3)标准,技术指标较现有的HBM2和HBM2E标准有巨大的提升,芯片单个引脚速率达到6.4Gbit/s,实现了超过1TB/s的总带宽,支持16-Hi堆栈,堆栈容量达到64GB,为新一代高带宽内存确定了发展方向[9]。HBM通过TSV和微凸块技术将3D垂直堆叠的DRAM芯片相互连接,突破了现有的性能限制,大大提高了存储容量,同时可提供很高的访存带宽。
HBM的优点
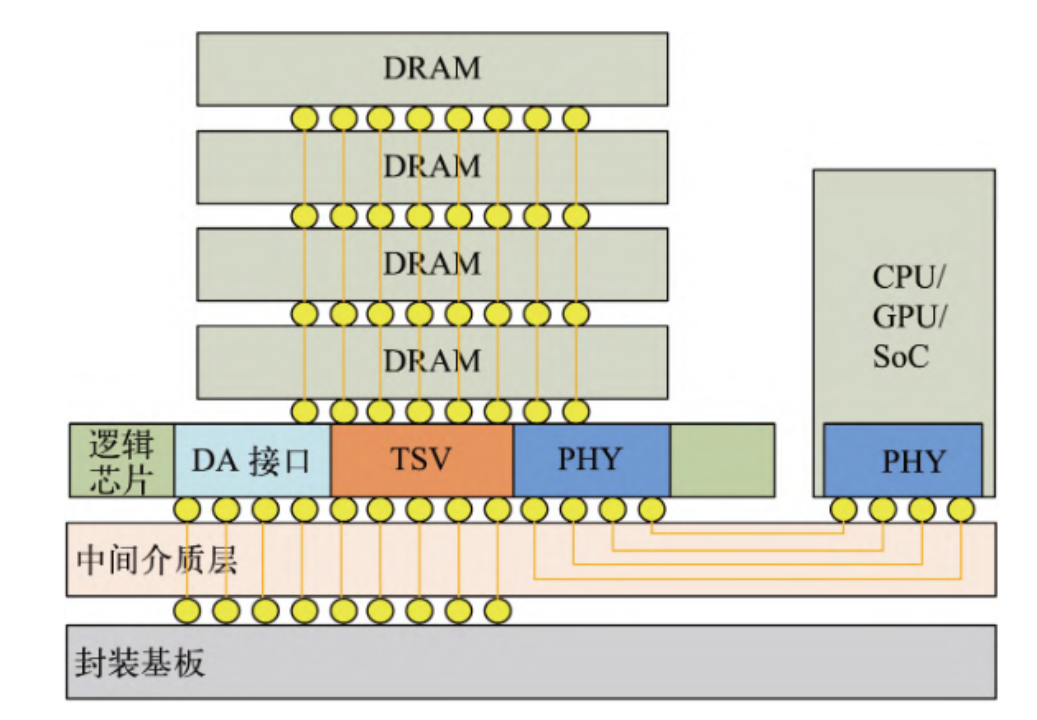
HBM堆叠结构 来源:电子与封装
高速、高带宽HBM堆栈没有以外部互连线的方式与信号处理器芯片连接,而是通过中间介质层紧凑而快速地连接,同时HBM内部的不同DRAM采用TSV实现信号纵向连接,HBM具备的特性几乎与片内集成的RAM存储器一样。
可扩展更大容量
HBM具有可扩展更大容量的特性。HBM的单层DRAM芯片容量可扩展;HBM通过4层、8层以至12层堆叠的DRAM芯片,可实现更大的存储容量;HBM可以通过SiP集成多个HBM叠层DRAM芯片,从而实现更大的内存容量。SK Hynix最新的HBM3堆栈容量可达24 GB。
更低功耗
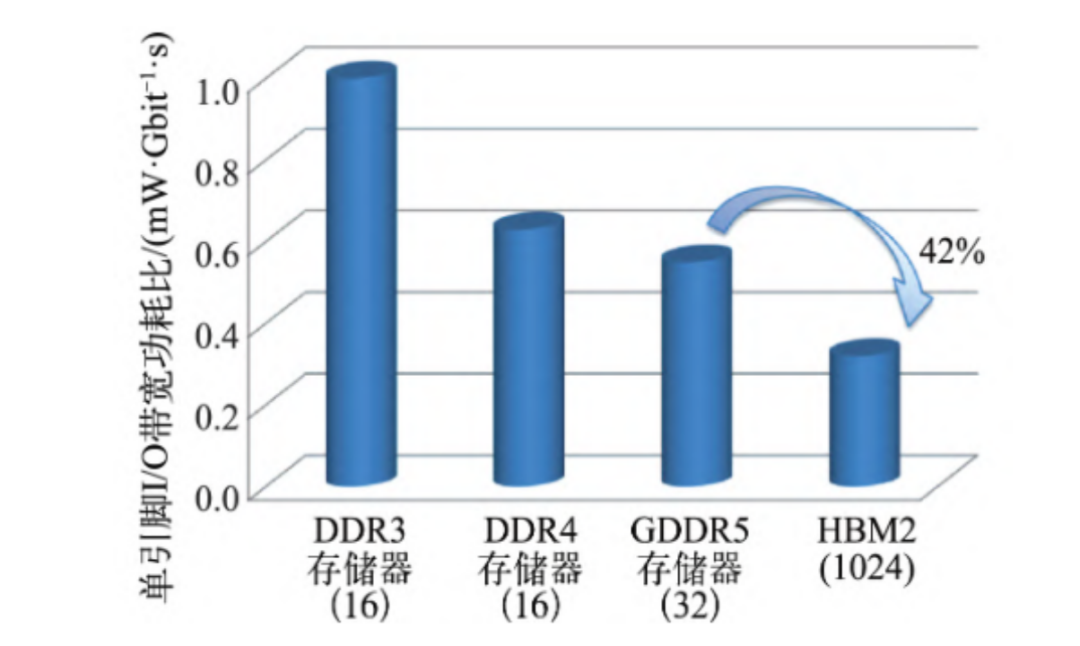
由于采用了TSV和微凸块技术,DRAM裸片与处理器间实现了较短的信号传输路径以及较低的单引脚I/O速度和I/O电压,使HBM具备更好的内存功耗能效特性。以DDR3存储器归一化单引脚I/O带宽功耗比为基准,HBM2的I/O功耗比明显低于DDR3、DDR4和GDDR5存储器,相对于GDDR5存储器,HBM2的单引脚I/O带宽功耗比数值降低42%。
更小体积
在系统集成方面,HBM将原本在PCB板上的DDR内存颗粒和CPU芯片一起全部集成到SiP里,因此HBM在节省产品空间方面也更具优势。相对于GDDR5存储器,HBM2节省了94%的芯片面积。
02、HBM新时代,巨头布局
HBM每一次更新迭代都会伴随着处理速度的提高。引脚(Pin)数据传输速率为1Gbps的第一代HBM,发展到其第四代产品HBM3,速率则提高到了6.4Gbps,即每秒可以处理819GB的数据。也就是说,下载一部片长达163分钟的全高清(Full-HD)电影(5GB)只需1秒钟。这与上一代HBM2E(3.6Gbps)相比,速率翻了一番。
当然,存储器的容量也在不断加大:HBM2E的最大容量为16GB,HBM3的最大容量则增加到了24GB(业界最大容量)。SK海力士将同时推出16GB和24GB两种容量的HBM3产品。此外,HBM3还搭载了ECC校检(On Die-ErrorCorrection Code),可以自动更正DRAM单元(cell)传输数据的错误,从而提升了产品的可靠性。
硅穿孔(TSV,Through Silicon Via)可以说是使存储器的上述高性能得以实现的核心技术。TSV技术通过电极连接DRAM芯片上的数千个微细小孔,从而连接芯片,传送数据。比起通过在芯片上连接引线的方式传送数据的传统技术,TSV技术不仅可以实现速度翻倍,还有助于提升密度(density)。
HBM3与HBM2E最根本的区别在于产品规格(spec)本身得到了升级。在HBM2的产品规格下,其速度和容量已经达到了极限,无法再进一步提高。因此,SK海力士研发团队定义了一种全新的产品规格——HBM3。
美光公司(Micron)高性能存储器和网络业务副总裁兼总经理Mark Montierth表示:“美光致力于为世界最先进的计算系统提供业界性能最佳的解决方案。HBM3所提供的内存带宽对实现下一代高性能计算、人工智能和百万兆级系统至关重要。我们与新思科技的合作将加速HBM3产品生态系统的发展,以实现前所未有的超高带宽、功耗和性能。”
三星电子内存产品规划高级副总裁Kwangil Park表示:“在数据驱动的计算时代,人工智能、高性能计算、图形和其他应用程序的发展极大提高了对内存带宽的需求。作为世界领先的内存芯片制造商,三星一直致力于支持生态系统的形成,并开发HBM以满足不断增长的带宽需求。新思科技是HBM行业的生态系统先驱,也是三星的重要合作伙伴,我们期待与新思携手继续为客户提供更好的HBM性能。” 三星布局高带宽存储器(HBM)市场较为积极,并凭借深厚的积累在高带宽存储器(HBM)市场具备一定的影响力。2021年三星宣布了一项新的突破,面向AI人工智能市场首次推出了HBM-PIM技术。在此前,行业内性能最强运用最广泛的是HBM和HBM2内存技术,而这次的HBM-PIM则是在HBM芯片上集成了AI处理器的功能。PIM直接在存储芯片上集成了计算功能,而不是CPU、内存数据分离,这一突破促使了三星首发的HBM-PIM技术实现了2倍的性能,同时功耗还降低了70%。
在2022年技术发布会上发布的内存技术发展路线图中,三星展示了涵盖不同领域的内存接口演进的速度。在云端高性能服务器领域,HBM已经成为了高端GPU的标配,这也是三星在重点投资的领域之一。HBM的特点是使用高级封装技术,使用多层堆叠实现超高IO接口宽度,同时配合较高速的接口传输速率,从而实现高能效比的超高带宽。
在三星发布的路线图中,2022年HBM3技术已经量产,其单芯片接口宽度可达1024bit,接口传输速率可达6.4Gbps,相比上一代提升1.8倍,从而实现单芯片接口带宽819GB/s,如果使用6层堆叠可以实现4.8TB/s的总带宽。
2024年预计将实现接口速度高达7.2Gbps的HBM3p,从而将数据传输率相比这一代进一步提升10%,从而将堆叠的总带宽提升到5TB/s以上。另外,这里的计算还没有考虑到高级封装技术带来的高多层堆叠和内存宽度提升,预计2024年HBM3p单芯片和堆叠芯片都将实现更多的总带宽提升。而这也将会成为人工智能应用的重要推动力,预计在2025年之后的新一代云端旗舰GPU中看到HBM3p的使用,从而进一步加强云端人工智能的算力。
海士力(SKhynix)公司副总裁、HBM产品负责人兼DRAM设计主管Cheol Kyu Park Hyun表示:“作为全球领先的半导体制造商,海士力不断投资开发包括HBM3 DRAM在内的下一代内存技术,以满足AI和图形应用工作负载的指数式增长所带来的需求。与新思科技建立长期合作关系,有助于我们为共同客户提供经过全面测试和可互操作的HBM3解决方案,以提高内存性能、容量和吞吐量。”
SK海力士在新一代高带宽内存(HBM,High Bandwidth Memory)市场上,正展开乘胜追击。其秘诀正是得益于MR-MUF(Mass Reflow Molded Underfill)技术。通过自主研发的这项技术,SK海力士不仅击败了竞争对手美光半导体(Micron),还击败了DRAM市场排名第一的三星电子,主导了处于起步阶段的HBM内存市场。曾位居DRAM万年老二的SK海力士在最前沿的内存市场技术上领先竞争对手,另业界瞩目。
03、ChatGPT推动
ChatGPT等新兴AI产品对高性能存储芯片的需求与日俱增。据韩国经济日报报道,受惠于ChatGPT,三星、SK海力士高带宽内存(high bandwidth memory,HBM)接单量大增。
与 HBM 相关的上下游企业也在纷纷发力,以期抢占先机。AMD 在 HBM 的诞生与发展过程中功不可没。最早是 AMD 意识到 DDR 的局限性并产生开发堆叠内存的想法,其后与 SK 海力士联手研发了 HBM,并在其 Fury 显卡采用全球首款 HBM。据 ISSCC 2023 国际固态电路大会上的 消息,AMD 考虑在 Instinct 系列加速卡已经整合封装 HBM 高带宽内存的基础上,在后者之上继 续堆叠 DRAM 内存,在一些关键算法内核可以直接在整合内存内执行,而不必在 CPU 和独立内 存之间往复进行通信传输,从而提升 AI 处理的性能,并降低功耗。
英伟达同样重视处理器与内存间的协同,一直在要求 SK 海力士提供最新的 HBM3 内存芯片。据悉,目前已经有超过 2.5 万块英伟达计算卡加入到了深度学习的训练中。如果所有的互联网企 业都在搜索引擎中加入 ChatGPT 这样的机器人,那么计算卡以及相应的服务器的需求量将达到 50 万块,也将连同带动 HBM 的需求量大幅增长。
IP厂商亦已先行布局HBM 3。去年,Synopsys推出首个完整的HBM3 IP解决方案,包括用于2.5D多芯片封装系统的控制器、PHY(物理层芯片)和验证IP。HBM 3 PHYIP基于5nm制程打造,每个引脚的速率可达7200Mbps,内存带宽最高可提升至921GB/s。Rambus也推出支持HBM3的内存接口子系统,内含完全集成的PHY和数字控制器,数据传输速率达8.4Gbps,可提供超过1TB/s的带宽。
评论