

文 | 数字力场 佘宗明
发现没,好像没什么人再吹GPT-4了。
料到了它的热度会降下来,不降对不起Gartner曲线,但没想到是断崖式下降。
要知道,110多天前,作为ChatGPT进化版的GPT-4刚问世时,很多人还被它能1秒生成网站、解答逻辑题、调侃脑筋急转弯的能力惊到了。
那时候,国人的反应通常包括几点:
先是震惊,“真是牛逼Plus”。

后是担心,“差距又拉大了”。
接着是觉得自己想象力已经不够用了:按照GPT这一日千里的进化速度,GPT-5出来后,是不是得宣告大结局了?
尽管今天舆论谈到GPT时习惯提ChatGPT,但GPT-4其实是更强大的存在。
“皮衣刀客”黄仁勋就说:GPT-4的厉害之处,OpenAI也没说清楚。
360创始人周鸿祎则是将GPT-4视作“通用人工智能的奇点和强人工智能到来的拐点”。
“硅基取代碳基”的话题,也被GPT-4的史诗级进化带入舆论场。
包括马斯克跟AI教父Bengio在内的上千名科技行业人士,没多久后还联名发公开信,呼吁暂停强AI的研发。
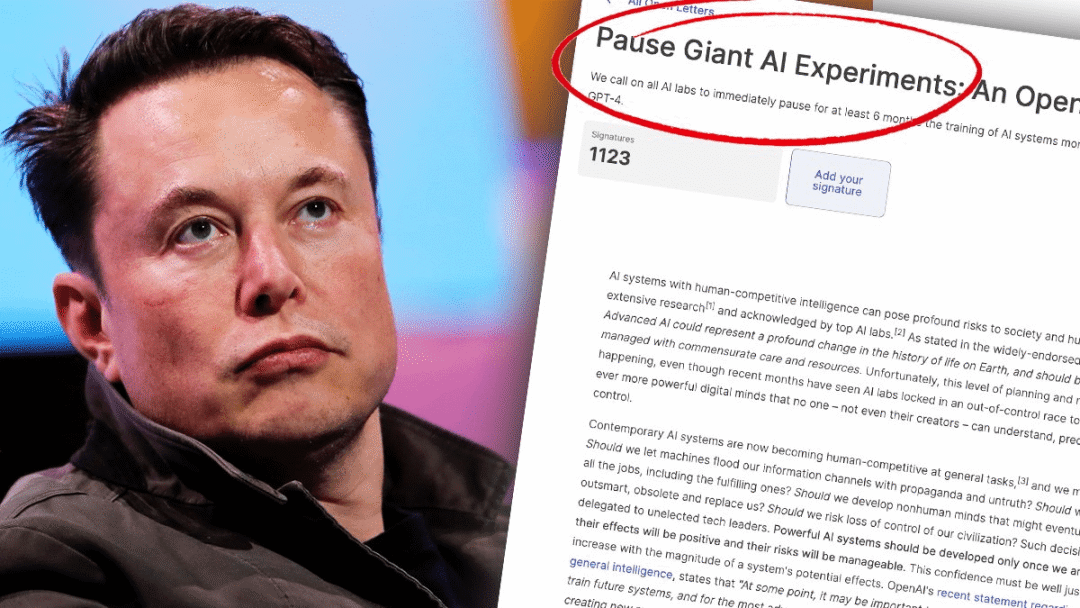
一股担心科技大爆炸引发社会大震荡的流行情绪,在全球蔓延开来。
可现在呢,你跟许多人说GPT-4,他没准会回你:GPT什么?G什么4?什么PT4?
你说:行,你先凉快着吧。他说“好嘞”,尔后继续刷普里戈任或蔡徐坤。
天空响了一道惊雷,但风暴雨并没有来。
何止是GPT-4,就连ChatGPT和背后的OpenAI公司,都在“增长放缓”的判断和“这轮AI见顶了吗”的分析中,显得有些黯淡失色。
以前上热搜,指向的都是ChatGPT厉害炸了。
而今成热门,画风早已大变——
图灵奖得主杨立昆炮轰ChatGPT:五年内就没人用了
马斯克为了不再被ChatGPT白嫖,决定给 Twitter“上锁”
ChatGPT凉了?6月访问量环比下滑近10%
OpenAI遭集体诉讼,明星大模型变“数据小偷”?
已经有媒体开始严肃讨论:GPT,是吹起来的泡沫吗?
01
之前看GPT-4像乔峰,武功盖世。
现在看GPT-4像慕容复,浪得虚名。
这似乎又是个“初看是王者,再看是青铜”的副本。
问题来了:现有的大模型天花板GPT-4,已经不香了吗?
看上去,确实是这样。
就在上个月,“GPT-4变笨”的话题,一度在国外技术社区内引发热议。
有用户反馈,把GPT-4的3小时25条对话额度一口气用完了,都没能解决自己的代码问题,切换到ChatGPT基于的GPT-3.5版本,反倒把事情解决了。
他反馈的主要问题包括:以前GPT-4能写对的代码,现在满是Bug;回答问题的深度分析变少了,内容质量变差了。
这引起网友们的共鸣,“GPT-4开倒车”的说法由此兴起。
不少网友都怀疑,GPT-4会像微软必应那样,出道即巅峰,但后来惨遭“前额叶切除”。
深度学习框架Keras创始人、网红科学家François Chollet,为GPT-4“自干五”地洗道:
不是GPT的表现变差,而是大家渡过了最初的惊喜期,对它的期待变高了。
言下之意,是高期待值拉高了人们对GPT失误的敏感度。
但OpenAI开发者推广大使Logan Kilpatrick,倒是挺会自我拆台——
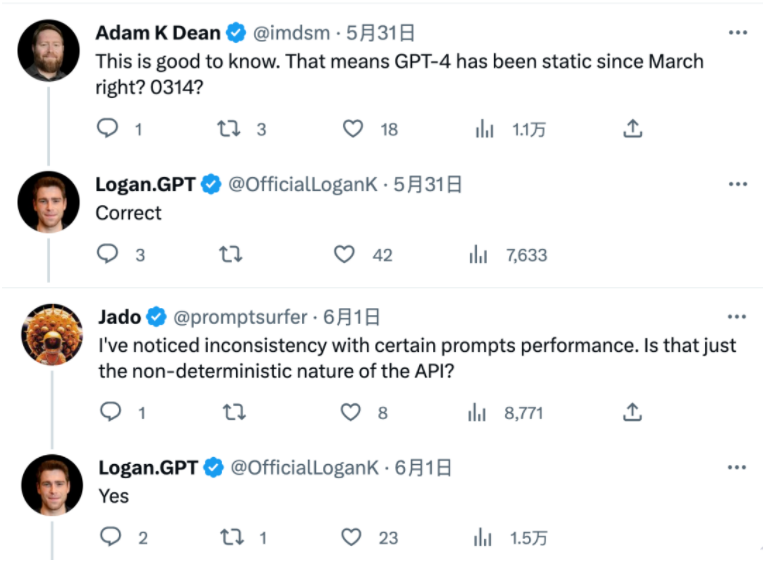
网友问他,GPT-4大模型本体自从3月14日发布以来都是静态的,对吧?
他说,没错。
网友又问他,相同提示词回答不一致,是因为大模型本身不稳定吗?
他又回答,Yes。
02
GPT-4变“弱”了,国内科技大佬的“大模型自信”也就变强了。
几个月前,国内外AI大模型存在代差,几乎是共识,歧异只在于差距到底有多大。
今年3月25日,周鸿祎曾表示,中国大语言模型和GPT-4差距在两三年。
5月上旬,周鸿祎跟俞敏洪对谈,谈到ChatGPT问题时说,“如果不经过两年的模仿和抄袭,上来就说自己能超越,那才叫吹牛呢。”
几天后,做客央视节目时又说:GPT-4有强大的思维链模型,能够把一个事情做连续多步推理,能够把一个目标做多任务的分解和规划。如果要跟这种能力去比,国内大模型引擎跟它比都是六七十分的水平,差距可能是两年,“如果有人说差两个月、差两周我可能不太相信”。
华为原副总裁张俊对此大概颇为认同,他5月下旬接受采访时也说,国内外AI大模型存在约两年的代差。
而李彦宏被王小川怼,也是因为他3月下旬接受专访时提了一嘴“文心一言和 ChatGPT 的水平差了2个月,但可以追赶”。
在王小川看来,这属于自我吹嘘,“怎么可能只差2个月?”“之前如果说追上GPT-3.5用一年还是有可能的,但是目前OpenAI已经训练到GPT-4的级别,GPT-5也在训练过程当中,我们追上还需要三年。”
就连李彦宏之后都给自己找补,说自己是被断章取义了。
彼时的共识就是:AI大模型的进化是非线性的,其正向增强回路的特点会强化“强者愈强”的头部效应,外加语料库质量差异,国内外AI大模型可能会越拉越大。
但近段时间,某些大佬的口径在变。
科大讯飞董事长刘庆峰就很自信。在5月6日的讯飞星火认知大模型发布会上,刘庆峰表示,当前讯飞星火认知大模型已经在文本生成、知识问答、数学能力三大能力上已超ChatGPT。
他还扬言:10月24日,将实现通用模型对标ChatGPT,中文超越ChatGPT的当前版本,英文能做到相当水平,并在教育、医疗等领域做到业界领先。
周鸿祎也不遑多让:6月8日,跟品玩创始人骆轶航对话时,他说,最近几个月国内同行陆陆续续发布了自己的大模型,虽然客观来讲跟GPT4.0还有点差距,相比GPT3.5也有点差距,但差距没有那么大。
在5天后的360智脑大模型发布会上,他更是表示,国内大模型已基本赶上或接近国际先进水平,之前曾说和全球先进的差距有一两年,今天收回这句话。
中国工程院院士邬贺铨在6月下旬接受采访时也说,评价大模型水平应该是多维度的,全面性、合理性、使用便捷性、响应速度、成本、能效等,笼统地说目前我国大模型开发与国外的差距为1—2年的依据还不清楚,现在下这一结论意义也不大。
他还指出,按2022年年底的数据,美国占全球算力36%,中国占31%,现有算力总规模与美国相比有差距但不大,而以GPU和NPU为主的智能算力规模中,中国明显高于美国(按2021年年底数据,美国智算规模占全球智算总规模15%,中国占26%)。
03
所以,GPT-4是被吹得太狠了吗?
这两天的两则新闻,或许挺适合对此作答:
阿里达摩院多语言NLP团队日前发布了首个多语言多模态测试基准 M3Exam,共涵盖 12317 道题目,结果显示,多语言能力上,GPT-4是唯一一个可以超过60%准确率的模型, 其他的均不及格。
麻省理工学院和微软的学者近来的研究也发现,GPT-4在自修复方面表现出了有效能力,GPT-3.5则没有。在此之外,GPT-4还能够对GPT-3.5生成的代码提供反馈。
那为什么很多人感觉GPT-4能力退化了?
微软研究院早前刷屏的那篇论文《AGI的火花:GPT-4早期试验》中的说法,兴许可资参考:
微软方面获得的GPT-4版本性能,要远强于目前的公测版本。公测版本变弱,是因为它要对标人类的指令和价值观。
说大白话就是:OpenAI也怕出安全问题,所以“宁可变慢一点,也要安全一些”。
有人会说:不重要了,没看到人家访问量正在下滑吗?
访问量下滑,确实是不少人评价ChatGPT们“涨不动了”“也不行了”的重要依据。
乍看起来,这不乏数据支撑:多家数据分析网站指出,ChatGPT的访问量环比增长率已从1月份的131.6%、2月份的62.5%、3月份的55.8%、4月份的12.6%,跌到了5月份的2.8%,6月份或环比下降。
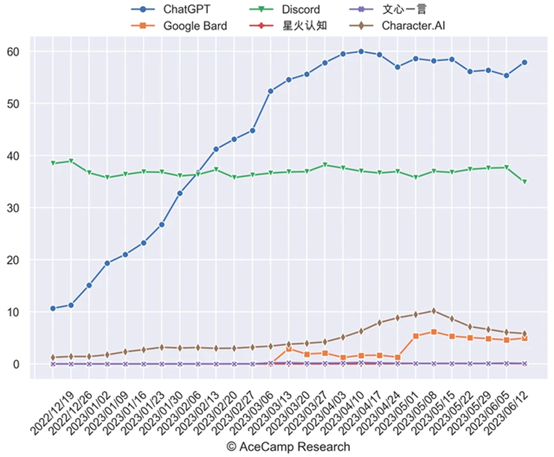
OpenAI麾下的ChatGPT和GPT-4告别流量高增长时代,大概率是事实。
但别忘了几点潜在背景:
1,OpenAI未必在乎C端用户直接访问官网的流量,因为它不像跟B端客户抢用户。
OpenAI的CEO阿尔特曼就曾表示,ChatGPT未来的核心战略使命,是吸引更多的企业应用程序接入API,而非在C端,与自己的企业客户争夺流量。
OpenAI从3月初开始,就在降价token的费用,借此鼓励更多第三方开发者(很多都是B端客户)使用ChatGPT和Whisper工具,通过API接口整合接入他们的服务。
现实中,很多人访问的都是那些应用插件,而不是OpenAI官网。这难免对ChatGPT和GPT-4造成分流,但那些统计工具并未顾及这层因素。
2,4月初ChatGPT曾出现大面积封号,主要针对“特制工具”批量注册的黑账号。
来自东方的神秘力量们凭着VPN和黑科技贡献的流量,就被切掉了。
所以,你说它的流量下滑没毛病,但这未必是OpenAI最在意的。
04
不论是GPT-4貌似没那么“灵”了,还是ChatGPT和GPT-4访问量下滑了,都指向了一点:
大模型的正确打开方式,与其说是做流量入口,不如说是深入行业场景,做行业数字化的AI底座。
从网络反馈看,反映GPT-4变笨了的,主要都是些细分行业从业者。他们想要的业务知识,确实是那些基础性、普适型的公用大模型给不了的。
OpenAI要把自身从C端爆火的超级AI应用,变成并不性感的API接口服务平台,说白了,就是想将价值做深,而不是只赚流量钱。
为什么阿里云的通义千问今年4月发布后,想要通过“伙伴计划”撬动更多企业在再训练和精调基础上打造企业的专属大模型?
为什么周鸿祎说“公有大模型在落地政府、城市、行业和企业场景时并不能直接使用,存在着缺乏行业深度、易带来数据安全隐患、无法保障内容真正可信及无法实现成本可控四大痛点”,企业级垂直大模型才是未来?
为什么腾讯云6月19日不是直接发布基础的通用大模型,而是发布面向 B 端客户的 MaaS(模型即服务)服务解决方案,帮金融、政府、文旅、传媒、教育等行业打造契合自身业务需要的“专属模型”?
原因就在于:AI大模型是工业革命级的生产力工具,最终得服务于生产效率提升,是以还得将B端作为切入口。
唯有如此,才能在AI时代“把所有行业重做一遍”。
前些天,傅盛PK朱啸虎,围绕ChatGPT激辩,核心也在于类ChatGPT产品的价值点开掘上。
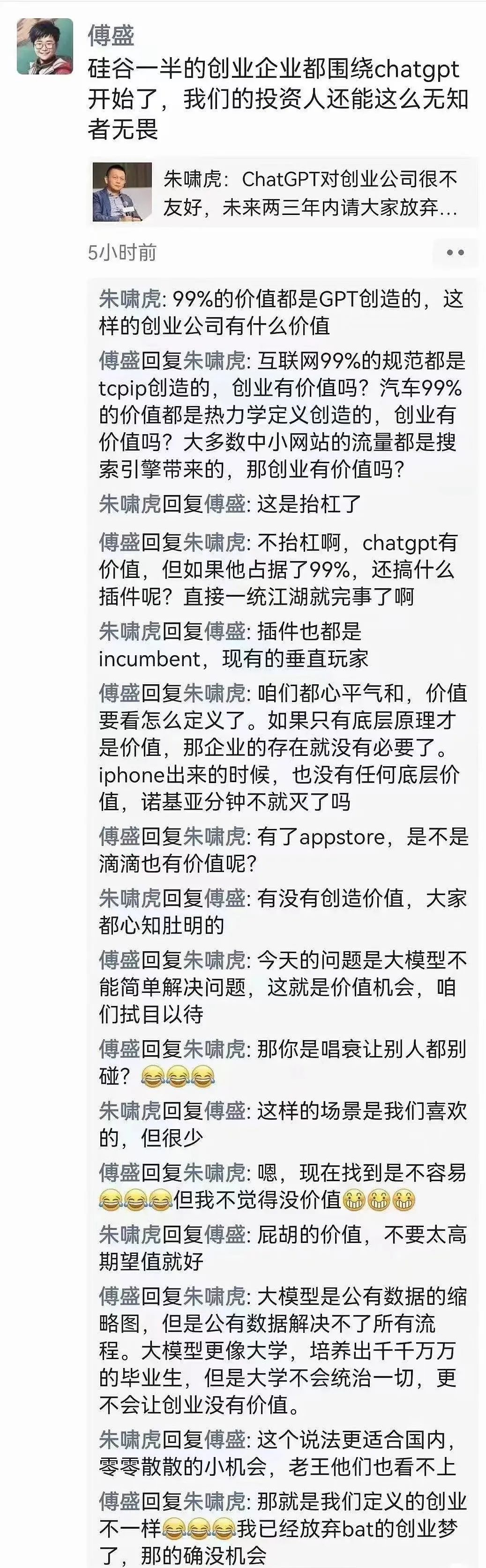
作为创投圈话题人物的朱啸虎,认为ChatGPT对创业者不友好,只有大厂商才玩得转大模型,大模型都是在大模型上做应用又没什么价值,完全没有BAT级机会。
曾跟周鸿祎、雷军、马化腾、马云等一众大佬相爱相杀的猎豹创始人傅盛,则认为大模型催生了很多新的架构在大模型之上的创业机会,包括直接在大模型上搭建的不同应用和由于数据私有带来的垂直领域大模型等。
可以这么理解:朱啸虎认为,创业公司们很难复制OpenAI,压根就没做通用AI时代的Windows或安卓系统的机会。
傅盛则不以为然,认为做AI时代的美团滴滴也挺好——美团滴滴们不就是靠拿捏住落地场景做大的吗?
05
说回GPT-4,再怎么说它变弱了,它依旧是霸榜级别的存在。
打个不甚恰当的比方,GPT-4就是大模型版NBA里巅峰期还没过去的詹姆斯,它身后的Bard、LLaMA、文心一言、通义千问等,就相当于字母哥、杜兰特、库里、约基奇,仍在追赶。
詹姆斯未必是“永远的神”(华语乐坛这么多年了“永远的神”也只有华晨宇一个),但在其鼎盛期,他的实力是独一档。
至于OpenAI的GPT以后会不会走下坡路,就难以料定了。
就目前看,中国大模型的追赶之路仍然道阻且长。
特别是考虑到美国预计7月份针对对华芯片出口实施新管制,连英伟达为中国特供的A100平替版GPU芯片A800都要禁,加速追赶正迎来更多高难度挑战。
但不能说中国大模型就没机会。中国互联网过去20年能弯道超车,成为全球Top2的玩家,超大市场提供的海量应用场景就是个重要因素。
中国消费互联网规模能做成全球第一,就得益于互联网平台们抓住了应用场景里蕴藏的机会,进而不断做大。
到了大模型时代,国产大模型很难再做出ChatGPT那种一问世就举世瞩目的大模型产品了,毕竟喝头啖汤有身位优势。
可它们能不能立足于应用场景,在助益实体产业中发掘出更多“平台级”机会来,还挺值得观察。
能,就会得到市场的犒赏。
说到底,GPT-4有没有从北乔峰变南慕容,固然挺有说头。
但反求诸己,更重要的,还是练好“适合自身体质”的武功秘笈。
不然的话,连进AI江湖“五绝”的机会都没。
评论